


OceanBaseデータベースにおいて、テーブルは最も基本的なデータ格納単位です。テーブルにはすべてのユーザーがアクセス可能なデータが含まれており、各テーブルは複数の行で構成され、各行は複数の列で構成されます。各テーブルの設計と使用は、業務要件に基づいて適切に計画する必要があり、システムの効率性と拡張性を確保するために不可欠です。以下では、テーブルタイプ、更新モード、データ分散、インデックス、データ型、ビューなどの観点から説明し、APテーブル設計原則に基づいて、シナリオ推奨事項と組み合わせの説明を行います。
APシナリオにおけるテーブル設計の原則
AP(分析処理)シナリオにおけるテーブル設計は、以下の3つの原則を中心に展開し、後述のテーブルタイプ、データ分布、インデックス、ビューなどの機能と組み合わせて活用します。
- ワイドテーブル:分析シナリオでは、列数が多いワイドテーブルが一般的であり、単一クエリで部分的な列のみにアクセスすることが多いです。カラムストアテーブルやカラムストアインデックスを採用することで、列単位での格納とスキャンが可能となり、I/Oを削減してベクトル化やSkip Indexを効果的に行えます。さらに、パーティションやテーブルグループと組み合わせることで、ワイドテーブルを水平方向に分散させ、他のテーブルと整列させることができ、Joinや並列スキャンを容易にします。詳細は本記事の「テーブルタイプ」「データ分布」および APシナリオにおけるデータテーブル設計とクエリ最適化の実践 を参照してください。
- 事前集計:固定次元の集計やレポート系のクエリについては、マテリアライズドビューなどを用いて事前に結果を計算・永続化し、クエリ時にはマテリアライズドビューから直接読み取ることで、リアルタイム集計にかかるオーバヘッドを低減します。レポート作成、ダッシュボード、固定された分析基準などのシナリオに適しています。詳細は本記事の「ビュー」および マテリアライズドビュー(MySQLモード)、マテリアライズドビュー(Oracleモード)を参照してください。
- パーティション戦略:パーティションテーブルを用いて、パーティションキー(時間、地域、IDなど)に基づいてデータを水平分割することで、パーティションプルーニングによるスキャン量の削減、パーティション単位での並列計算が可能になり、パーティション単位でのライフサイクル管理(アーカイブ、クリーンアップ)も容易になります。APシナリオでは、パーティションキーを一般的なフィルタリング・集計の次元と一致させることを推奨し、テーブルグループと組み合わせて複数テーブルのパーティションを整列させることで、Joinを最適化します。詳細は本記事の「データ分布」および OLAPシナリオにおけるテーブルパーティション設計の実践を参照してください。
テーブルタイプ
OceanBaseデータベースでサポートされているテーブルタイプには、パーティションテーブル、レプリケーションテーブル、主キーテーブル、主キーのないテーブル、外部テーブルなどがあります。
- パーティションテーブル:OceanBaseデータベースでは、通常のテーブルのデータを一定のルールに従って複数のブロックに分割し、同一ブロックのデータを物理的にまとめて保存することができます。このようにブロックに分割されたテーブルをパーティションテーブルと呼びます。OceanBaseデータベースの基本的なパーティション戦略には、範囲 (Range) パーティション、リスト (List) パーティション、ハッシュ (Hash) パーティションが含まれます。
- レプリケーションテーブル:レプリケーションテーブルは、OceanBaseデータベースにおける特殊なテーブルです。このテーブルは、任意の「正常」なレプリカでデータの最新の変更を読み取ることができます。
- 主キーテーブルと主キーのないテーブル:主キーテーブルとは主キーを含むテーブルのことです。主キーが指定されていないテーブルは主キーのないテーブルと呼ばれます。
- 外部テーブル:データベース内のテーブルデータはデータベースのストレージ領域に格納されますが、外部テーブルのデータは外部ストレージサービスに格納されます。
- ヒープテーブル (ヒープ組織テーブル):データは主キー順にソートされずに格納され、主キーはセカンダリ一意インデックスとなり、データとインデックスは分離されます。主キーは一意性制約に使用され、クエリは主テーブルに依存します。ユーザーデータが時間順に書き込まれる場合、Skip Indexを効果的に活用して分析系クエリの効率を向上させることができます。APシナリオでは、新規作成されるテーブルはデフォルトでヒープ組織テーブルとなります。テナントレベルの構成パラメータ default_table_organizationがOLAPパラメータテンプレートで
HEAPに設定されており、ORGANIZATIONが明示的に指定されていない場合、新規作成されるテーブルはヒープテーブルとなり、大量インポートやSkip Indexの利用に適しています。 - 一時テーブル:APシナリオでは、ETLの中間結果、ダイレクトロードの一時保管、複雑なクエリの中間結果キャッシュなどに一時テーブルが広く使用されます。データはセッションまたはトランザクションごとに隔離され、セッション終了後やトランザクションのコミット/ロールバック後に自動的にクリーンアップされるため、永続化テーブルとは区別されます。MySQLモードではセッションレベルの一時テーブルが、Oracleモードではグローバルな一時テーブルがサポートされます。
APシナリオでは、OceanBaseは多様なテーブルタイプをサポートしています。TPシナリオで一般的なレプリケーションテーブル、パーティションテーブル、主キーテーブル、主キーのないテーブルに加え、データの格納方法(行単位か列単位か)や新たな次元に基づいて、カラムストアテーブルや行列混合テーブルといったテーブルタイプも導入されています。
カラムストアテーブル:カラムストアテーブルはデータを行ではなく列単位で格納するため、分析系クエリのパフォーマンスを大幅に向上させることができます。特に、データ量が多く集計分析を頻繁に行うシナリオに適しています。詳細については、カラムストアテーブルのアーキテクチャを参照してください。
行列混合テーブル:行単位と列単位で格納されたデータがそれぞれ別々に保持されており、システムはクエリステートメントに基づいて、行ストアと列ストアのどちらでクエリを実行した方がパフォーマンスが優れているかを自動的に判断します。トランザクション業務と分析業務の両方を扱うシナリオに適しています。
テーブルの更新モード
OceanBaseデータベースでは、テーブル作成時にデータの書き込みおよびクエリモードを指定できます。テーブル作成時に CREATE TABLE ステートメントのパラメータ merge_engine を使用して、delete_insert 更新モード と partial_update 更新モード を選択します。これら2つのモードは、異なるビジネスシナリオに合わせて設計されたデータ更新戦略です。
delete_insert(全列更新モード)
クエリ性能を優先 し、「Merge-On-Write」メカニズムにより
UPDATE操作を全列のDELETEおよびINSERTレコードに変換し、各行データが完全な列値を含むことを保証します。このモードは、複雑なクエリやバッチ処理(分析タスクなど)の効率を大幅に向上させますが、増分データに追加のストレージ容量が必要となります。増分データが頻繁であり、かつ高速な分析が必要な シナリオに適しています。partial_update(部分更新モード)
変更された列の値のみを記録し、冗長なストレージを回避します。クエリ時には複数のデータをマージして最新値を取得する必要があるため、パフォーマンスは相対的に低くなります。しかし、更新頻度は高いがクエリ要求は低い シナリオ(OLTP系業務など)や、ストレージコストに敏感な環境に適しています。
特性カテゴリ |
delete_insert更新モード |
partial_update更新モード |
|---|---|---|
| ストレージ方式 | 更新のたびにSSTableに全列データを含む2行(DELETEとINSERT)を書き込む。 |
更新のたびに変更された列の値のみを記録するため、ストレージ容量を節約できる。 |
| クエリ効率 |
|
クエリ時に複数のMemtable/SSTableのレコードをマージして主キーの最新値を取得する必要があるため、パフォーマンスに影響を与える可能性がある。 ストレージコストを重視し、更新操作が頻繁なシナリオに適している。 |
| 適用シナリオ | 増分データの割合が高く、複雑なクエリやバッチ処理による分析を頻繁に実行する必要があるシナリオ。 | 更新頻度が高いが、クエリの要求は低いシナリオ。 |
詳細については、MySQLモードでのテーブル作成およびOracleモードでのテーブル作成を参照してください。
データの分散
パーティショニング戦略は、APテーブル設計において重要な要素です。OceanBaseデータベースでは、パーティションテーブルを作成することでデータを異なるパーティションに分散し、さらに異なるパーティションのデータを異なるマシンに配置します。クエリ時にはパーティションプルーニングを活用してスキャンするデータ量を削減できるほか、複数マシンのリソースを活用してクエリ性能を向上させることができます。デフォルトでは、異なるテーブル間のデータはランダムに分散しており、直接的な関連性はありません。ロードバランシングを用いることで、あるテーブルのデータをクラスタ全体に比較的均等に分散させることが可能です。
分散型APシステムでは、テーブルのデータ量は通常多くなります。異なるテーブルのデータがランダムに分散している場合、テーブル結合時のデータ転送オーバーヘッドは無視できないものとなります。テーブルグループを利用することで、パーティショニング方法が同じパーティションテーブルのデータを特定のルールに従って整列させ、関連性のあるデータを同一マシン上に集約することができます。これにより、これらのテーブルを結合する際にPartition Wise Join方式で実行でき、結合シナリオにおけるデータ転送のオーバーヘッドを効果的に低減し、性能を向上させることができます。
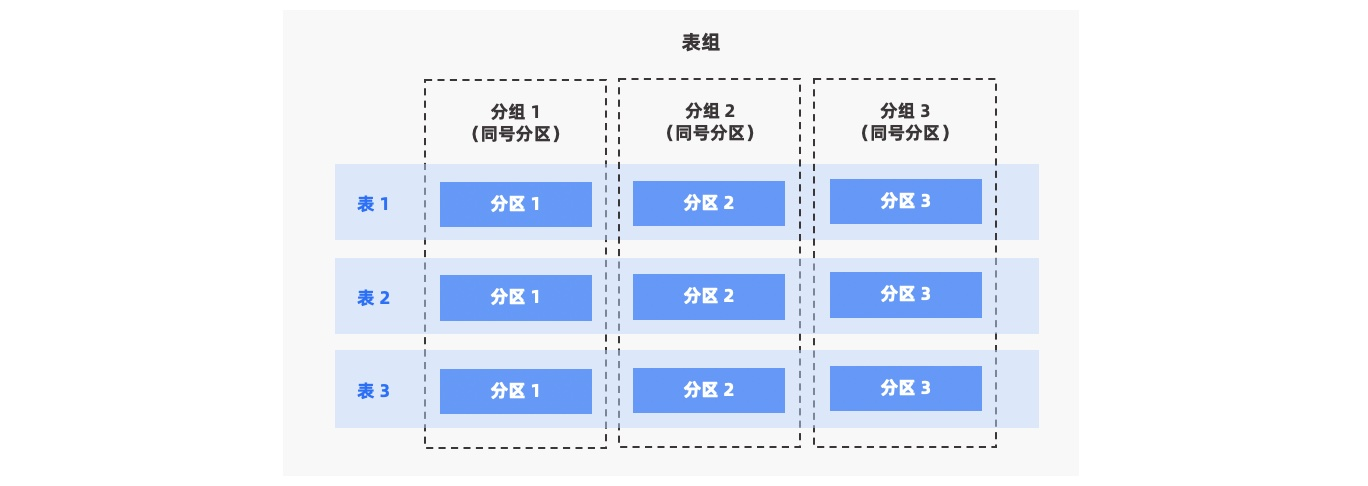
OceanBaseはパーティションテーブルとサブパーティションテーブルをサポートしており、RANGEパーティション、LISTパーティション、HASHパーティションの3種類のパーティションタイプをサポートしています。
OceanBaseは3種類の属性を持つテーブルグループを提供しています:
NONE:テーブルグループ内のすべてのテーブルのすべてのパーティションが同一マシン上に集約されます。
PARTITION:テーブルグループ内の各テーブルのデータをパーティション単位で分散します。サブパーティションテーブルの場合は、各パーティションの下にあるすべてのサブパーティションがまとめられます。
ADAPTIVE:テーブルグループ内の各テーブルのデータを適応型方式で分散します。テーブルグループ内のテーブルがパーティションテーブルの場合はパーティション単位で、サブパーティションテーブルの場合は各パーティションの下のサブパーティション単位で分散します。
詳細については、データの分散、MySQLモードのテーブルグループおよびOracleモードのテーブルグループを参照してください。
インデックスの種類
インデックスはクエリパフォーマンスを向上させるための重要なコンポーネントです。OceanBaseはAPシナリオで複数のインデックスタイプをサポートしています。
- インデックスデータの分布:ローカルインデックスとは、インデックスパーティションがベーステーブルのパーティションと一対一で対応し、結合して格納されるものを指します。グローバルインデックスとは、インデックスがベーステーブルのパーティションと独立しており、パーティションをまたいで構成できるものを指します。これらは「インデックスがどのパーティションに作成され、どのように分布するか」という観点に関連しています。
- インデックスのストレージ形式:行ストアインデックスとカラムストアインデックスは、インデックステーブル自体が行単位または列単位でデータを整理していることを指します。カラムストア形式(例:
WITH COLUMN GROUP (each column))は分析系のスキャンや集計に適しており、行ストア形式はポイントクエリやランダムアクセスに適しています。カラムストアインデックスとは、カラムストアストレージ形式を採用したインデックスのことです(例:B-treeインデックスをカラムストアとして指定する場合)。インデックステーブルは列単位でデータを整理し(WITH COLUMN GROUP (each column)など)、行ではなく列に基づいて格納されます。これはHTAPシナリオにおける集計、ワイドテーブルのスキャン、分析系クエリに適しており、特に大規模データを扱う際のデータ検索と分析時間を大幅に短縮できます。詳細については、カラムストアおよびインデックスの作成(MySQLモード)— カラムストアインデックスを参照してください。
上記の2つの観点から、インデックス構造に基づいて以下のカテゴリに分類できます:
- B-treeインデックス(通常のインデックス):デフォルトのインデックス構造で、一意インデックス、非一意インデックス、関数インデックスが含まれます。等値クエリ、範囲クエリ、ソート、ポイントクエリに適しています。B-treeインデックスはローカルインデックスまたはグローバルインデックスになり得、行ストアまたはカラムストア形式を採用することもできます。カラムストア形式のB-treeインデックスは一般的に言われるカラムストアインデックスであり、HTAPシナリオにおける分析系スキャンに適しています。詳細については、インデックスの概要、インデックスの作成(MySQLモード)、カラムストアを参照してください。
- 全文インデックス:転置インデックスと分かち書きに基づき、
CHAR/VARCHAR/TEXT列に対してキーワードマッピングを構築します。ログ分析、ドキュメント/ナレッジベースの検索、関連性のソートに適しています。ローカルインデックスのみサポートします。詳細については、全文インデックスを参照してください。 - JSON複数値インデックス:OceanBaseデータベースのMySQLモードは複数値インデックス機能をサポートしており、配列やコレクションにインデックスを作成して、JSON配列要素に基づく検索のクエリ効率を向上させることができます。タグ/分類、多対多関連、および
MEMBER OF()、JSON_CONTAINS()、JSON_OVERLAPS()などの述語に適しています。ローカルインデックスのみサポートします。詳細については、複数値インデックスおよびインデックスの作成(MySQLモード)を参照してください。 - 空間インデックス:地理空間データやGISシナリオで使用される独立した空間インデックス構造で、座標範囲内のデータを迅速に検索できます。ローカルインデックスのみサポートします。
- ベクトルインデックス:Vector型列に作成されるベクトルインデックスで、密ベクトルインデックスと疎ベクトルインデックスが含まれます。密ベクトルインデックスの例としてHNSW、IVFが挙げられます。疎ベクトルインデックスのタイプと制約は、ベクトルインデックスの概要を参照してください。L2、内積、コサインなどの距離/類似度計算をサポートしており、ベクトル類似度検索クエリに適しています。独立したインデックス構造を持ち、ローカルインデックスのみサポートします。
APシナリオにおけるカラムストアインデックス、行ストアベーステーブル + カラムストアインデックスなどの組み合わせについては、APシナリオにおけるデータテーブル設計とクエリ最適化の実践のHTAPシナリオにおけるクエリの最適化を参照してください。全文インデックス、JSON複数値インデックス、空間インデックス、ベクトルインデックスなどの特殊なインデックスの選択については、JSON複数値インデックスと全文インデックスの実践を参照してください。その他の構文と実装の詳細については、MySQLモードインデックスの概要およびOracleモードインデックスの概要を参照してください。
データ型
テーブルの作成と使用の前に、データベース管理者はビジネスニーズに基づいてテーブル構造とデータ型を適切に計画する必要があります。データストレージの効率とクエリの最適化を確保するため、管理者は以下の原則に従う必要があります:
- テーブル構造の正規化:テーブル構造を適切に設計することで、データの冗長性を最小限に抑え、クエリのパフォーマンスを向上させます。
- 適切なSQLデータ型の選択:各列に最も適したSQLデータ型を選択することで、ストレージ容量を削減し、クエリの速度を向上させます。
一般的なSQLデータ型には以下のものが含まれます:
- 基本データ型:例えば
INT、VARCHAR、DATEなどです。 - 複合データ型:例えば
JSON、ARRAY、BITMAPなどです。これらは、より複雑なデータ構造の格納に適しています。
詳細なSQLデータ型の説明については、以下を参照してください:
ビュー
OceanBaseデータベースは、標準ビューとマテリアライズドビューをサポートしています。
- 標準ビュー(Standard Views):標準ビューは、非マテリアライズドビューとも呼ばれ、最も一般的なビューのタイプです。これらはビューの定義を表すSQLクエリのみを格納し、クエリ結果は格納しません。
- マテリアライズドビュー(Materialized Views):マテリアライズドビューは標準ビューとは異なり、物理的にクエリの結果を保持します。OceanBaseデータベースは非同期マテリアライズドビューをサポートしており、基礎テーブルのデータが変更されても、マテリアライズドビューは即座に更新されません。これにより、基礎テーブルのDML操作の実行パフォーマンスが保証されます。マテリアライズドビューは事前集計の一般的な実装方法であり、固定された分析基準、レポート、大画面表示などのシナリオに適しています。詳細については、MySQLモードのマテリアライズドビューおよびOracleモードのマテリアライズドビューを参照してください。
シナリオの推奨と組み合わせ
ワイドテーブル、事前集計、パーティショニング戦略などのAPテーブル設計原則を組み合わせ、以下の表は典型的なシナリオにおけるテーブル設計の組み合わせ提案を示しており、業務形態に応じた選定に役立ちます。具体的なパーティションキー、パーティション数、ストレージ形式、インデックスは、データ量とクエリパターンに基づいてさらに詳細に決定する必要があります。詳細については、APシナリオにおけるデータテーブル設計とクエリ最適化の実践、OLAPシナリオにおけるテーブルパーティション設計の実践、およびJSON複数値インデックスと全文インデックスの実践を参照してください。
シナリオ |
推奨されるテーブル設計の組み合わせ |
説明 |
|---|---|---|
| 純粋な分析、ワイドテーブル、複数列スキャン | カラムストアテーブル + パーティションテーブル(時間/次元別)+ テーブルグループ(複数テーブルのJOIN時) | ワイドテーブルはカラムストアでI/Oを削減します。パーティション戦略により、データの絞り込みと並列処理が可能になります。テーブルグループは関連するテーブルのパーティションを整列させ、パーティションワイズJOINを容易にします。 |
| 定型レポート/ダッシュボード、繰り返し集計クエリ | 詳細テーブル(パーティション+カラムストアまたは行列混合)+ マテリアライズドビュー(事前集計結果) | 事前集計:マテリアライズドビューが集計結果を保持し、クエリは直接読み取ります。詳細テーブルは引き続きアドホック分析に使用できます。 |
| HTAP、TPを主としつつ分析も必要な場合 | 行ストアベーステーブル + カラムストアインデックス + パーティションテーブル | 書き込みとポイントクエリは行ストアを使用し、分析はカラムストアインデックスを使用してストレージを制御します。詳細については、APシナリオにおけるデータテーブル設計とクエリ最適化の実践の行ストアベーステーブル+カラムストアインデックスを参照してください。 |
| TP/APの物理的隔離が必要な場合 | F/Rの行ストアまたは行列混合 + カラムストアレプリカ(Cレプリカ) | APトラフィックはCレプリカで弱い読み取りを行い、TPはF/Rを使用します。F/R上に分析用のカラムストアインデックスを構築しなくても、カラムストアスキャンを実現できます。 |
| アドホック分析、クエリ列が固定されていない場合 | 行列混合テーブル + パーティションテーブル | オプティマイザーが自動的に行ストア/カラムストアのパスを選択します。パーティションではデータの絞り込みとライフサイクル管理を行います。 |
| ログ/イベントトラッキング、時間範囲によるクエリとクリーンアップ | カラムストアテーブルまたは行列混合 + RANGEパーティション(日/時間単位) | パーティション戦略:時間によるパーティショニングはデータの絞り込みや、パーティション単位でのアーカイブ・削除を容易にします。カラムストアは列単位でのスキャンと圧縮に適しています。 |
上記の組み合わせは重ねて使用できます(例:パーティションテーブル + カラムストア + マテリアライズドビュー)。具体的な選択は、業務の書き込み量、クエリパターン、ストレージコストに基づきます。
データ作成例
パーティション、カラムストア、行ストアインデックスを含むテーブルを作成します。
CREATE TABLE salesdata (
sale_id INT,
product_id INT NOT NULL,
saledate DATE NOT NULL,
saledate_int INT, -- 通常の列として定義
quantity INT,
price DECIMAL(10, 2),
customer_id INT,
PRIMARY KEY (sale_id, saledate_int) -- 主キーには通常の列を含めることができます
)
PARTITION BY RANGE COLUMNS (saledate_int) (
PARTITION p2023_q1 VALUES LESS THAN (202304),
PARTITION p2023_q2 VALUES LESS THAN (202307),
PARTITION p2023_q3 VALUES LESS THAN (202310),
PARTITION p2023_q4 VALUES LESS THAN (202401)
)
WITH COLUMN GROUP(each column);
CREATE INDEX idx_product_id ON salesdata(product_id);
CREATE INDEX idx_customer_id ON salesdata(customer_id);
パーティション:
salesdataテーブルは 範囲パーティション(RANGE)を使用します。PARTITION BY RANGE COLUMNS (saledate_int):saledate_int列によってパーティションを分割します。4つのパーティションが定義されています:
p2023_q1パーティションには202304より前のすべてのデータ(つまり2023年第1四半期)が含まれます。p2023_q2、p2023_q3、p2023_q4パーティションは、2023年の第2、第3、第4四半期のデータをそれぞれカバーします。
カラムストア:
WITH COLUMN GROUP(each column);により カラムストア が指定されています。これらの列のデータはカラムストア方式で保存され、大規模なデータ分析シナリオに適しています。行ストアインデックス:
product_id列とcustomer_id列に対して、それぞれインデックスidx_product_idとidx_customer_idを作成しました。行ストアインデックスは、特定の列に基づくクエリ、特に頻繁に実行される小規模なクエリを高速化することができます。
カラムストアテーブルを作成して使用する際、大量のデータをインポートした場合は、読み取り性能を向上させるためにメジャーコンパクション操作を1回実行し、統計情報収集を行って実行戦略を調整する必要があります。
メジャーコンパクション操作:データを一括インポートした後、メジャーコンパクション操作を1回実行することを推奨します。これは、断片化されたデータを整理し、物理的に連続した状態にすることで、読み取り時のディスクI/Oを削減し、読み取り性能を向上させるのに役立ちます。データインポート後、テナント内でメジャーコンパクション操作を1回トリガーし、すべてのデータがベースライン層にメジャーコンパクションされていることを確認してください。操作については、MAJOR AND MINOR (MySQLモード)およびMAJOR AND MINOR (Oracleモード)を参照してください。
統計情報収集:メジャーコンパクション操作完了後、統計情報の収集を行うことを推奨します。これは、オプティマイザーが効果的なクエリ計画と実行戦略を生成するために非常に重要です。GATHER_SCHEMA_STATS (MySQLモード) /GATHER_SCHEMA_STATS (Oracleモード)を実行して、すべてのテーブルから統計情報を収集し、ビューGV$OB_OPT_STAT_GATHER_MONITOR (MySQLモード)およびGV$OB_OPT_STAT_GATHER_MONITOR (Oracleモード)で収集進捗を監視できます。
なお、カラムストアテーブルのデータ量が増加するにつれて、メジャーコンパクション操作の速度が低下する可能性がある点に注意してください。