


カラムストア FAQ
カラムストアとは?
OceanBaseのカラムストアは、ディスク上の静的データをカラムストア形式で保存し、メモリ上で変更されたデータを行ストア形式で保存するデータ格納方式です。これにより、スキャン性能とトランザクション処理能力の両方を兼ね備えることができます。
分析系のクエリでは、カラムストアはクエリ性能を大幅に向上させることができ、OceanBaseがHTAPを効果的に実現するために欠かせない機能です。従来のAPデータベースでは、カラムストアデータは通常静的であり、原位置での更新が困難です。一方、OceanBaseのLSMツリー構造では、SSTableが静的であるため、本質的にカラムストアの実装に適しています。MemTableは動的でありながらも行ストア形式のままであるため、トランザクション処理に追加の影響を与えません。このようにして、TP型およびAP型のクエリ性能をある程度両立させることが可能です。
「カラムストアインデックス」とは?
OceanBaseデータベースでは、「カラムストアに対するインデックス作成」とは異なる、カラムストアインデックスの概念もサポートしています。カラムストアインデックスとは、インデックステーブルの構造がカラムストア形式であることを指します。
例えば、既に行ストアテーブル t6 があり、c3 の合計を求めたい場合、パフォーマンスを最適化するには、c3 に対してカラムストアインデックスを作成できます:
create table t6(
c1 TINYINT,
c2 SMALLINT,
c3 MEDIUMINT
);
create /*+ parallel(2) */ index idx1 on t6(c3) with column group (each column);
その他にも、より多くのインデックス作成方法をサポートしています:
インデックス内で冗長な行ストアをサポートします。
create index idx1 on t1(c2) storing(c1) with column group(all columns, each column); alter table t1 add index idx1 (c2) storing(c1) with column group(all columns, each column);インデックス内で純粋なカラムストアをサポートします。
create index idx1 on t1(c2) storing(c1) with column group(each column); alter table t1 add index idx1 (c2) storing(c1) with column group(each column);
データベースインデックスで STORING 句を使用する目的は、インデックスに追加の非インデックス列データを格納することです。これにより、特定のクエリのパフォーマンスを最適化でき、テーブルへの再アクセスを回避したり、インデックスソートのコストを削減したりできます。クエリがインデックスに格納されている列のみにアクセスし、元の行をテーブルから再クエリする必要がない場合、クエリ効率を大幅に向上させることができます。
カラムストアテーブルとカラムストアレプリカに関するよくある質問
カラムストアテーブルとカラムストアレプリカの違いは何ですか? それらの関係はどうなっていますか?
両者は異なる観点から説明されています:
カラムストアテーブル:テーブルレベルのストレージ形式(行指向、純粋な列指向、行列混合など)を指し、
WITH COLUMN GROUPまたはテナントレベルのdefault_table_store_formatなどによって決定されます。データは物理的にテナントの F(フル機能)/R(読み取り専用)レプリカ に保存されます。これらのレプリカでは、MemTable/ダンプは引き続き行単位で組織され、ベースラインは列指向または行列冗長で構成されます。読み取りパスは増分データとベースラインデータを統合します。F/Rレプリカ上で意味に合致するパスを実行する場合、デフォルトではレプリカのロールに応じた強整合性読み取り(トランザクションや分離レベルなどに依存)が得られます。カラムストアレプリカ(Cレプリカ):独立したレプリカタイプを指し、通常は独立したゾーンに配置されます。Paxosの選挙や投票には参加せず、ログの非同期追従によってF/Rレプリカとの整合性を取ります。ローカルの メジャーレイヤーは主に列指向で ユーザーテーブルデータを格納します。同一の論理テーブルは、F/Rレプリカ上ではある種のストレージ形式(例えば行指向や行列混合)であり、Cレプリカ上では列指向形式であることができ、APとTPの リソース分離 に利用されます。
関係:両者は独立しています。Cレプリカがない テナント上にカラムストアテーブルを作成することも可能です(データはF/Rレプリカの列指向または混合形式にのみ存在します)。また、Cレプリカを持つテナント内では、F/Rレプリカ上に行指向テーブルを作成し、Cレプリカ上に同一テーブルの列指向形式 を提供して読み取り専用の分析を実現することもできます。カラムストアテーブルとCレプリカは同時に存在し、アーキテクチャ要件に応じて組み合わせることができます。
- 読み取り整合性:Cレプリカはログソースに対して追従の遅延があります。OceanBase V4.6.0以前では、独立ODPなどの方法でアクセスするCレプリカの分析クエリは、通常 弱い整合性 で計画されることが一般的でした。V4.6.0以降では、セッション設定に基づいてCレプリカ上で 強い整合性または弱い整合性 の読み取りをサポートしています(例:
ob_read_consistency)。そして、ap_query_route_policyなどによって列指向計画を試みるかどうかが制御されます。
カラムストアテーブルを作成するには、必ずしもカラムストアレプリカが必要ですか? Fullレプリカ上にカラムストアテーブルを作成できますか?
カラムストアレプリカは不要で、Full(F)レプリカ上にカラムストアテーブルを作成することもできます。
カラムストアテーブルはテーブルレベルのストレージ形式設定であり、テーブル作成時の WITH COLUMN GROUP またはテナントレベルの構成パラメータ default_table_store_format で指定します。テナントにF/Rレプリカがあれば十分です:任意のローカリティ(例えば F@zone1, F@zone2 のみ)で、カラムストアテーブルや行列混合テーブルを作成でき、データは列指向(または行列冗長)形式でF/Rレプリカに保存されます。カラムストアレプリカ(Cレプリカ)はオプションの独立デプロイメント形式であり、TP/APの物理的または論理的分離および読み取り専用分析トラフィックに使用され、「カラムストアテーブルを作成できるかどうか」とは依存関係がありません。
OceanBaseは直接に純粋なカラムストアテーブルを作成することをサポートしていますか? 行指向テーブルに基づく必要がありますか?
直接に純粋なカラムストアテーブルを作成することをサポートしており、行指向テーブルに基づく必要はありません。
テーブル作成時に WITH COLUMN GROUP (each column) を指定するだけで純粋なカラムストアテーブル(列指向ベースラインのみ、行指向ベースラインなし)を取得できます。例:
CREATE TABLE t (pk INT PRIMARY KEY, c1 INT, c2 INT) WITH COLUMN GROUP (each column);
パーティションテーブルでは、主キー列についてはポイントルックアップ検索のために行指向形式が追加で保持されますが、全体としては依然として純粋なカラムストアテーブルと見なされます。また、まず行指向テーブルを作成し、その後 ALTER TABLE ... ADD COLUMN GROUP (each column); などのDDLを使用してカラムストアテーブルに変換することもできます。詳細は本文の「カラムストアテーブルの作成方法」を参照してください。
カラムストアと行指向間のデータ整合性はどのように保証されますか? 非同期の場合、遅延はどの程度ですか?
2つのシナリオがあります:
- カラムストアテーブル(F/Rレプリカ上):ベースラインは列指向または行列混合レイアウト、増分データは行単位で組織されます(MemTable/ダンプ)。読み取り時には増分データとベースラインデータが統合され、F/Rのデフォルトセマンティクスでは強整合性が保証され、レプリカ間の追加的な遅延はありません。
- カラムストアレプリカ(Cレプリカ):CレプリカはPaxosに参加せず、非同期ログを用いてF/Rレプリカを追従・再生します。データはログソースに対して遅延が生じます。V4.6.0以前では、Cレプリカにアクセスする分析読み取りは、多くの場合 弱い整合性 で計画されました。V4.6.0以降では、Cレプリカ上で 強い整合性 を設定できます:強い整合性読み取りはレプリカが読み取り可能なポイントに追従するのを待ち、遅延は弱い整合性よりも高くなります。TPと完全に同一のログ、Cレプリカの遅延なし を要求する場合、分析は依然として F/Rレプリカ上の列指向テーブルまたは行列混合テーブル で優先的に完了させる方が適しています。
TPとAPのトラフィックを分離する方法は何ですか?APに障害が発生した場合、ディザスタリカバリの対策はありますか?
トラフィック分離:
- Cレプリカなし:TPとAPは同じF/Rレプリカとアクセスエントリを共有し、オプティマイザーが自動的に行ストア/カラムストアのパスを選択します。TP/APのキャビネットやリンクレベルでの物理的隔離は行いません。
- Cレプリカあり(OceanBase V4.6.0以前):一般的な方法は、TPがF/Rへのアクセスエントリ(強力読み書き)を経由し、APが独立ODPを経由することです。ODP側で弱い読み取りを設定し、リクエストをCレプリカにルーティングします(
proxy_primary_zone_name、route_target_replica_type = 'ColumnStore'、init_sql='set @@ob_route_policy = COLUMN_STORE_ONLY'など)。これにより、TP/APとCレプリカ間のリンクレベルでの隔離が実現されます。運用保守およびレプリカ管理については、カラムストアレプリカの使用を参照してください。 - Cレプリカあり(V4.6.0以降):上記の独立ODP(方法1)に加えて、OBServerに直接接続する(またはカラムストア専用線が設定されていない通常のODPを経由する)こともできます。
ap_query_route_policyなどを通じて、オプティマイザーが自動的にカラムストア計画を試みます(方法2)。これにより、Cレプリカ用に別途ODPルーティングアイテムを維持する必要がなくなります。
AP(Cレプリカ)側のディザスタリカバリと制限:
- Cレプリカはリーダーに復元できません。物理復元ではCレプリカの復元はサポートされていません(テナントのローカリティにCレプリカが含まれている場合、復元は失敗します)。プライマリデータベースにCレプリカがデプロイされていない場合、スタンバイデータベースにもCレプリカのデプロイは推奨されません。
- Cレプリカが存在するゾーンまたはODPに障害が発生した場合、APのクエリはF/Rレプリカにフォールバックできます:APクライアントをプライマリODPに接続するか、ルーティングを調整して、分析リクエストをF/R上で強力読み取りで実行させます(TPとリソースを共有します)。
- V4.3.5 BP1からは複数のCレプリカのデプロイがサポートされています(最大3個を推奨)。複数のゾーンにCレプリカをデプロイし、ODPルーティング(方法1)または自動ルーティング(方法2)を組み合わせてAPの読み取り負荷を分散し、冗長性と高可用性を実現できます。
カラムストアテーブルとカラムストアレプリカに関するよくある質問
カラムストアテーブルとカラムストアレプリカの違いは何ですか? それらの関係はどうなっていますか?
両者は同じ概念ではありません。
- カラムストアテーブル:テーブルのストレージ形式を指します。テナントのF(Full)/R(Read)レプリカ上で、テーブルのベースラインデータがカラムストア形式で保存されます(行ストア、カラムストア、行列冗長の3種類のテーブルレベルストレージモードを選択可能)。カラムストアテーブルが存在するパーティションのプライマリ・セカンダリレプリカはどちらもカラムストア形式であり、OLAPクエリは強整合性読み取りを利用できます。
- カラムストアレプリカ(Cレプリカ):レプリカタイプの一種で、独立したZoneにデプロイされます。そのZone上のユーザーテーブルのベースラインデータはカラムストア形式で保存されます。CレプリカはPaxosの選挙や投票には参加せず、観察者としてF/Rのログを非同期で追従し、ローカルで再生します。読み取り専用および弱整合性読み取りサービスのみを提供します。
関係:両者は独立しています。カラムストアレプリカがないテナント上にカラムストアテーブルを作成することも可能です(テーブルはF/Rレプリカ上でのみカラムストア形式で存在します)。また、Cレプリカを持つテナント内では、F/R上のテーブルが行ストア形式である一方で、Cレプリカ上の同一テーブルをカラムストア形式で保存し、APの弱い整合性読み取りに利用することもできます。
カラムストアテーブルを作成するには、カラムストアレプリカが必要ですか? Fullレプリカ上にカラムストアテーブルを作成できますか?
カラムストアレプリカは不要で、Full(F)レプリカ上にカラムストアテーブルを作成できます。
カラムストアテーブルはテーブルレベルのストレージ形式設定であり、テーブル作成時の WITH COLUMN GROUP またはテナントレベル構成パラメータ default_table_store_format で指定します。テナントにF/Rレプリカがあればよく、任意のローカリティ(例えば F@zone1, F@zone2 のみ)でカラムストアテーブルや行列混合テーブルを作成できます。データはF/Rレプリカ上にカラムストア(または行列冗長)形式で保存されます。カラムストアレプリカ(Cレプリカ)はオプションの独立デプロイメントであり、TP/APの物理的分離や弱い整合性読み取りのためのAPトラフィック処理に使用され、「カラムストアテーブルを作成できるかどうか」とは依存関係がありません。
OceanBaseは、純粋なカラムストアテーブルを直接作成することをサポートしていますか? 行ストアテーブルに基づいて作成する必要がありますか?
純粋なカラムストアテーブルを直接作成することをサポートしており、行ストアテーブルに基づいて作成する必要はありません。
テーブル作成時に WITH COLUMN GROUP (each column) を指定することで、純粋なカラムストアテーブル(カラムストアベースラインのみ、行ストアベースラインなし)を取得できます。例:
CREATE TABLE t (pk INT PRIMARY KEY, c1 INT, c2 INT) WITH COLUMN GROUP (each column);
パーティションテーブルでは、主キー列に対してポイントルックアップ検索のために行ストアが追加で保持されますが、全体としては純粋なカラムストアテーブルと見なされます。また、行ストアテーブルを作成した後、ALTER TABLE ... ADD COLUMN GROUP (each column); などのDDLを使用してカラムストアテーブルに変換することもできます。詳細は本文の「カラムストアテーブルの作成方法」を参照してください。
カラムストアと行ストア間のデータ一貫性はどのように保証されますか? 非同期の場合、遅延はどの程度ですか?
シナリオは2つです:
- カラムストアテーブル(F/Rレプリカ上):ベースラインデータはカラムストア、増分データは行ストア(MemTable/ダンプ)です。読み取り時に行ストアの増分データとカラムストアのベースラインデータをリアルタイムで統合し、強整合性を提供します。追加の遅延はありません。
- カラムストアレプリカ(Cレプリカ):CレプリカはPaxosに参加せず、非同期ログを使用してF/Rを追従し再生します。外部には弱整合性読み取りを提供します。ドキュメントでは具体的な遅延値は示されていませんが、実際の遅延はネットワーク、負荷、追従の進捗状況によって異なります。Cレプリカは観察者として「リアルタイムでログを追従」するため、一般的には秒単位またはミリ秒単位に達しますが、実際の環境によって異なります。強整合性分析が必要な場合は、Cレプリカを読むのではなく、F/R上のカラムストアテーブルまたは行列混合テーブルを使用する必要があります。
TPとAPのトラフィックを分離する方法はありますか?また、APに障害が発生した場合のディザスタリカバリ対策はありますか?
トラフィック分離:
- Cコピーなし:TPとAPは同じF/RコピーとODPを共有し、オプティマイザーが自動的に行ストア/カラムストアのパスを選択します。物理的な分離はできません。
- Cコピーあり:TPトラフィックはプライマリODPを経由してF/Rコピーにアクセスします(強い読み込み/書き込み)。APトラフィックは独立ODPを経由し、弱い読み込み(例:
obproxy_read_consistency = 1)を設定して、リクエストをCコピーが存在するゾーン(例:proxy_primary_zone_name、route_target_replica_type = 'ColumnStore'、init_sql='set @@ob_route_policy = COLUMN_STORE_ONLY'など)にのみルーティングすることで、TPとAPの物理的な分離を実現します。カラムストアコピーの使用を参照してください。
AP(Cコピー)側のディザスタリカバリと制限:
- Cコピーはリーダーに復元できません。物理的復元ではCコピーの復元はサポートされていません(テナントのローカリティにCコピーが含まれる場合、復元は失敗します)。プライマリデータベースにCコピーがデプロイされていない場合、スタンバイデータベースにもCコピーのデプロイは推奨されません。
- Cコピーが存在するゾーンまたはODPに障害が発生した場合、APクエリはF/Rコピーにフォールバックできます。APクライアントをプライマリODPに接続するよう変更するか、ルーティングを調整することで、分析リクエストをF/R上で強い読み込みで実行します(これにより、TPとリソースを共有します)。
- V4.3.5 BP1からは、複数のCコピーのデプロイがサポートされています(最大3個を推奨)。複数のゾーンにCコピーをデプロイし、ODPを通じて異なるCコピーにルーティングすることで、APの読み取りの冗長性と高可用性を実現できます。
カラムストアテーブルを作成するにはどうすればよいですか?
まず、行と列のハイブリッドテーブルを作成します。
- 非パーティションテーブル:
create table t1(
c1 TINYINT,
c2 SMALLINT,
c3 MEDIUMINT
) with column group (all columns, each column);
- パーティションテーブル:
create table t2(
pk int,
c1 int,
c2 int,
primary key (pk)
)
partition by hash(pk) partitions 4
with column group (all columns, each column);
行と列のハイブリッドカラムストアテーブルを作成する際は、常に with column group (all columns, each column) 構文を使用します。その意味は以下の通りです:
all columns:すべての列をグループ化して1つのワイドカラムとし、行ごとに格納します。これは元の行ストアと同じです。each column:テーブル内の各列をそれぞれカラム形式で格納します。
all columns と each column が一緒に現れる場合、デフォルトではカラムストアテーブル作成後も行ストアが冗長的に存在し、各レプリカが2つのベースラインデータを格納します。ただし、各テーブルのベースラインデータの数に関係なく、メモリテーブルおよびダンプにおける増分データは依然として同一のものを共有します。
次に、純粋なカラムストアテーブルを作成します。
- 非パーティションテーブル:
create table t3(
c1 TINYINT,
c2 SMALLINT,
c3 MEDIUMINT
) with column group (each column);
- パーティションテーブル:
create table t4(
pk1 int,
pk2 int,
c1 int,
c2 int,
primary key (pk1, pk2)
)
partition by hash(pk1) partitions 4
with column group (each column);
t4 テーブルの場合、pk1、pk2、c1、c2 に対してそれぞれカラムストアを作成すると同時に、(pk1, pk2) の組み合わせに対して行ストアも作成します。
テナントが作成するテーブルをデフォルトでカラムストアテーブルに設定する方法は?
テナントレベルのパラメータを設定するだけです。
alter system set default_table_store_format = "column";
同様に、デフォルトのテーブル作成形式を行ストアに設定するか、行ストアとカラムストアのデュアルスタイルに設定することもできます。
alter system set default_table_store_format = "row"; // 行ストア
alter system set default_table_store_format = "compound"; // 行ストアとカラムストアのデュアルスタイル
カラムストア版の推奨設定は何ですか?
# collationをutf8mb4_binに設定すると、パフォーマンスが瞬時に15%向上します。
set global collation_connection = utf8mb4_bin;
set global collation_server = utf8mb4_bin;
set global ob_query_timeout= 10000000000;
set global ob_trx_timeout= 100000000000;
set global ob_sql_work_area_percentage=30;
set global max_allowed_packet=67108864;
# CPU数の10倍を推奨します。
set global parallel_servers_target=1000;
set global parallel_degree_policy = auto;
set global parallel_min_scan_time_threshold = 10;
# parallel_degree_policy = autoの場合の最大DOPを制限します。
# DOPが大きくなりすぎるとパフォーマンスに影響を与える可能性があります。以下の値はCPU数 × 2に設定することを推奨します。
set global parallel_degree_limit = 0;
alter system set compaction_low_thread_score = cpu_count;
alter system set compaction_mid_thread_score = cpu_count;
alter system set default_table_store_format = "column";
説明
上記コードにおいて、cpu_count はテナント作成時に指定した min_cpu を表します。
カラムストアに到達したかどうかの判断方法
スキャンがカラムストアを経由する場合、EXPLAINにはTABLE FULL SCANと表示されます。カラムストアに到達した場合はCOLUMN TABLE FULL SCANと表示されます。以下のt5テーブルへのアクセスを例にします。
create table t5(
c1 TINYINT,
c2 SMALLINT,
c3 MEDIUMINT,
c4 INT,
c5 INT,
PRIMARY KEY(c1, c2)
) with column group(all columns, each column);
OceanBase(admin@test)>explain select c1,c2 from t5;
+------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------+
| =============================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------- |
| |0 |TABLE FULL SCAN|t5 |1 |3 | |
| =============================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t5.c1], [t5.c2]), filter(nil), rowset=16 |
| access([t5.c1], [t5.c2]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t5.c1], [t5.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------+
11 rows in set (0.011 sec)
OceanBase(admin@test)>explain select c1 from t5;
+------------------------------------------------------------------------+
| Query Plan |
+------------------------------------------------------------------------+
| ====================================================== |
| |ID|OPERATOR |NAME|EST.ROWS|EST.TIME(us)| |
| ------------------------------------------------------ |
| |0 |COLUMN TABLE FULL SCAN|t5 |1 |3 | |
| ====================================================== |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([t5.c1]), filter(nil), rowset=16 |
| access([t5.c1]), partitions(p0) |
| is_index_back=false, is_global_index=false, |
| range_key([t5.c1], [t5.c2]), range(MIN,MIN ; MAX,MAX)always true |
+------------------------------------------------------------------------+
11 rows in set (0.003 sec)
カラムストアテーブルでの列の追加と削除は可能ですか?
列の追加と削除は可能です。
Varchar型の列の最大文字数の増減をサポートします。
カラムストアは、行ストアテーブルと同様に、さまざまなオフラインDDLをサポートしています。
カラムストアの変更に関する詳細情報については、テーブルの行ストアからカラムストアへの変換(MySQLモード)およびテーブルの行ストアからカラムストアへの変換(Oracleモード)を参照してください。
カラムストアテーブルのクエリにはどのような特徴がありますか?
リダンダント行ストアテーブルでは、カラムストアテーブルのクエリロジックはデフォルトでRange Scanを採用し、列ストアモードで実行されますが、Point Getクエリは行ストアモードに戻ります。
純粋なカラムストアテーブルでは、すべてのクエリが列ストアモードで実行されます。
カラムストアはトランザクションをサポートしますか?トランザクションのサイズに制限はありますか?
行ストアテーブルと同様に、トランザクションをサポートしており、トランザクションのサイズに制限はありません。高い一貫性を備えています。
カラムストアテーブルのログ同期やバックアップ・リカバリには特別な点がありますか?
特に変わりはなく、行ストアテーブルと同じです。同期されるログはすべて行ストアモードのものです。
行ストアテーブルをDDLでカラムストアテーブルに変更できますか?
可能です。カラムストアの追加や行ストアの削除によって実現します。関連する構文例は以下のとおりです:
create table t1( pk1 int, c2 int, primary key (pk1));
alter table t1 add column group(all columns, each column);
alter table t1 drop column group(all columns, each column);
alter table t1 add column group(each column);
alter table t1 drop column group(each column);
説明
alter table t1 drop column group(all columns, each column); を実行しても、データを格納するGroupが存在しない心配はありません。すべての列は、DEFAULTL COLUMN GROUP というデフォルトのGroupに配置されます。
カラムストアでは複数の列をまとめて格納できますか?
OceanBaseデータベースV4.3.0バージョンでは、各列は独立して格納するか、すべての列を1行としてまとめて格納するかのどちらか一方のみがサポートされています。任意の数の列を選択してまとめて格納することは現在サポートされていません。
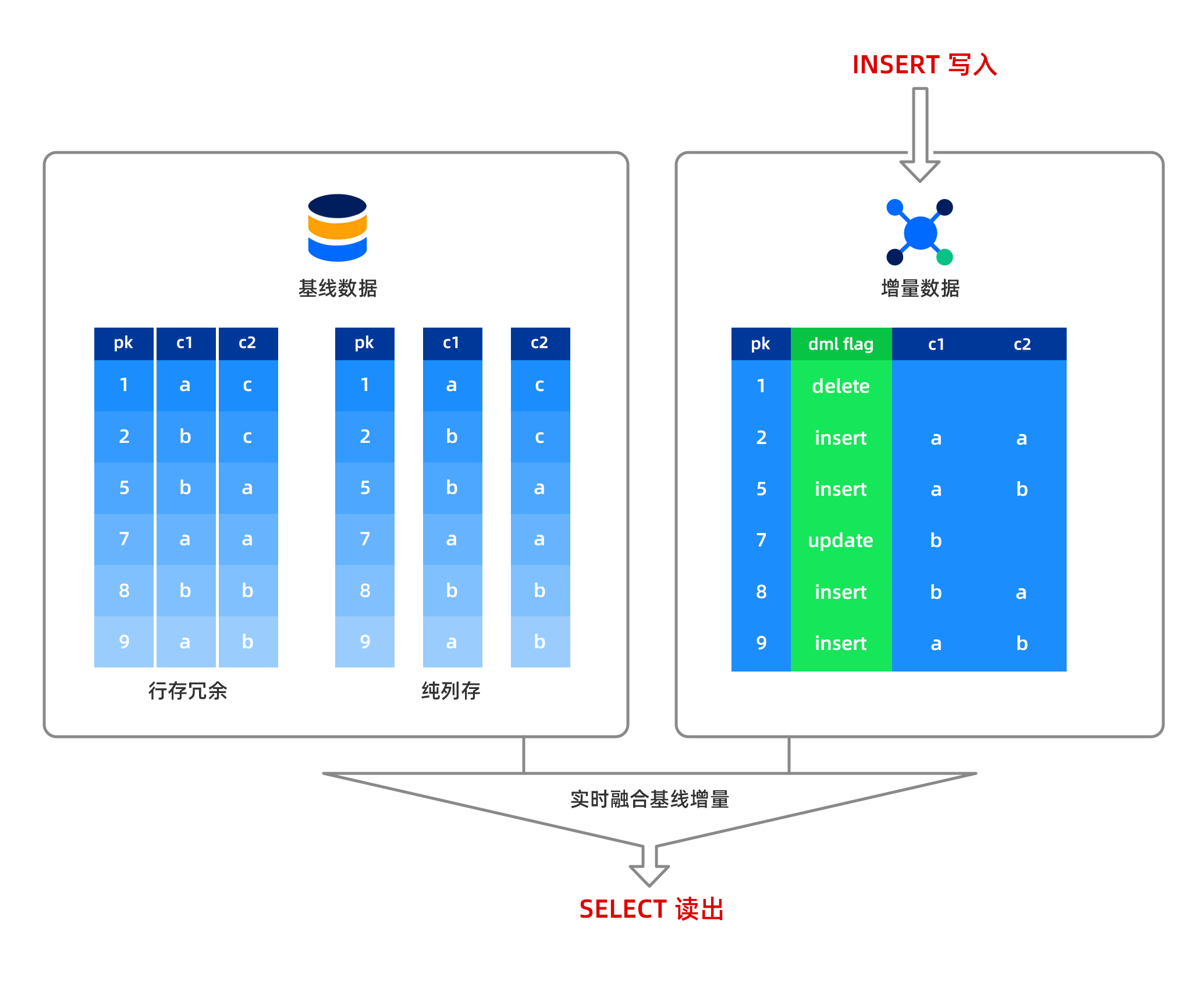
カラムストアは更新をサポートしますか?また、MemTable内の構造はどのようになっていますか?
OceanBaseデータベースでは、追加、削除、変更の各操作はすべてメモリ内で完了し、データはMemTableに行ストア形式で保存されます。一方、ベースラインデータは読み取り専用であり、ディスク上にカラムストア形式で保存されます。列データを読み取る際、MemTable内の行ストアデータとディスク上のカラムストアデータがリアルタイムで統合され、ユーザーに出力されます。これにより、OceanBaseデータベースは強整合性の読み取りをサポートしており、データの遅延は発生しません。MemTableに書き込まれたデータはダンプをサポートしており、ダンプされたデータも引き続き行ストア形式で保存されます。メジャーコンパクション後、行ストアデータとベースラインカラムストアデータが統合され、新しいベースラインカラムストアデータが形成されます。
注意
カラムストアテーブルにおいて、大量の更新操作が存在し、かつタイムリーにメジャーコンパクションが行われない場合、クエリのパフォーマンスに影響が出ます。そのため、バッチデータインポート後に一度メジャーコンパクションを実行することで、最適なクエリパフォーマンスを得られます。一方、少量の更新操作はパフォーマンスに大きな影響を与えません。
カラムストアテーブルのクエリにはどのような特徴がありますか?
冗長行ストアテーブルでは、カラムストアテーブルのクエリロジックはデフォルトで範囲スキャンをカラムストアモードで実行しますが、ポイントゲットは引き続き行ストアモードに戻ります。
純粋なカラムストアテーブルでは、すべてのクエリがカラムストアモードで実行されます。
カラムストアの特定の列にインデックスを作成できますか?
可能です。OceanBaseデータベースでは、カラムストアにインデックスを作成する場合でも行ストアにインデックスを作成する場合でも、作成されるインデックス構造は同じです。
カラムストアの1列または複数の列にインデックスを作成する意義は、カバリングインデックスを構築してポイントクエリのパフォーマンスを向上させたり、特定の列に対してソートを行ってソート性能を向上させたりすることができる点にあります。
最大で何列をサポートしますか?
現在、1つのカラムストアテーブルは最大4096列をサポートします。
カラムストアの使用にあたっての注意点は何ですか?
第一:データを一括インポートした後、メジャーコンパクションを実行することを推奨します。これにより、読み取り性能が向上します。データインポート後、テナント内で一度メジャーコンパクションをトリガーし、すべてのデータがベースラインに入ることを保証します。その後、テナント内で alter system major freeze; を実行し、システムテナントで select STATUS from CDB_OB_MAJOR_COMPACTION where TENANT_ID = テナントID; を実行して、メジャーコンパクションが完了したかどうかを判断します。STATUS が IDLE に変わったら、メジャーコンパクションが完了したことを意味します。
第二:メジャーコンパクション後、統計情報の収集を行うことを推奨します。統計情報の収集方法は以下のとおりです:
業務テナントでワンクリックですべてのテーブルの統計情報を収集し、16個のスレッドを起動して並行して収集します:
CALL DBMS_STATS.GATHER_SCHEMA_STATS ('db', granularity=>'auto', degree=>16);統計情報の進捗状況は、ビュー
GV$OB_OPT_STAT_GATHER_MONITORで確認できます。
第三:フルダイレクトロードロジックを使用してデータを一括インポートできます。この方法でデータをインポートしたテーブルは、メジャーコンパクションを行わなくても最適なカラムストアのスキャン性能を達成できます。フルダイレクトロードをサポートするツールには、obloaderやネイティブのload dataコマンドが含まれます。
第四:大ワイドテーブルの場合ではない限り、カラムストアを使用しなくても、カラムストアと同等の性能を達成できる可能性があります。これは、OceanBaseの行ストアバージョンにおけるマイクロブロックレベルの行と列のハイブリッドストレージアーキテクチャのおかげです(このような場合には驚かないでください)。
第五:大規模データテーブルでは、cold runとhot runの性能に差があります。
第六:オプティマイザーはコスト見積もりに基づき、行ストアとカラムストアのどちらを使用して列データにアクセスするかを自動的に選択します。
第七:カラムストアテーブルのメジャーコンパクション速度は遅くなります。
カラムストアテーブルのログ同期やバックアップ・リカバリには特別な点がありますか?
特に変わりはなく、行ストアテーブルと同じです。同期されるログはすべて行ストアモードのものです。
データインポート/移行 FAQ
ダイレクトロードとは何ですか?ダイレクトロードの方法を教えてください。
ダイレクトロードは、データインポートを高速化し、データクエリも高速化できるデータインポート方式です。大規模テーブルのデータインポートには、ダイレクトロード方式の使用を推奨します。現在、load data コマンドと insert into select ステートメントがダイレクトロードをサポートしています。ダイレクトロードの詳細な使用方法については、ダイレクトロードの概要を参照してください。
Flink CDCを使用して他のデータベースからOceanBaseにデータを同期することはできますか?
可能です。公式ドキュメントMySQLからOceanBaseへのFlink CDCによるデータ同期を参照してください。
Flink ConnectorによるOceanBaseへのアクセスはサポートされていますか?
サポートされています。詳細は https://github.com/oceanbase/flink-connector-oceanbase。 を参照してください。
パフォーマンスチューニング FAQ
AP Queryのパフォーマンスをさらに向上させる方法はありますか?
実践経験から得た知見によると、まず特別なソート要件がない限り、テーブル作成時に文字セットとしてutf8mb4ではなくbinaryを使用することでパフォーマンスが向上します。例:
create table t5(c1 TINYINT, c2 VARVHAR(50)) CHARSET=binary with column group (each column);
次に、ユーザーまたは業務上許容される場合、MySQLテナントでテーブル作成時にutf8mb4_bin文字セットを指定し、CHARSET = utf8mb4 collate=utf8mb4_binを指定します。
さらに、UNITのIOPSを増やすことで、ダイレクトロードを高速化できます。
カラムストア向けオプティマイザーにはどのような特徴がありますか?
カラムストア向けオプティマイザーは、行ストア向けオプティマイザーと比較して、以下の点が追加されています:
- オプティマイザーが行と列のストアを自律的に選択する能力。
- 行と列のストアの選択を制御するHint機能(テーブルレベル)。
- カラムストアに適応した計画コスト計算。
- カラムストアの遅延マテリアライゼーション最適化の追加。