


カラムナエンジン
大規模データの複雑な分析や膨大なデータのアドホッククエリシナリオにおいて、カラムナストレージはAPデータベースの重要な機能の一つです。カラムナストレージは、行指向ストレージとは異なるデータファイルの編成方法であり、テーブル内のデータを列単位で物理的に配置します。データをカラムナストレージで格納すると、分析シナリオにおいてクエリ計算に使用される列データのみをスキャンでき、行全体のスキャンを回避して、I/Oやメモリなどのリソース使用量を削減し、計算速度を向上させます。また、列単位での格納は本質的にデータ圧縮に適しており、高い圧縮率を得やすく、ストレージ容量とネットワーク転送帯域幅を削減できます。
OceanBaseは、LSM-Tree(Log Structured Merge-Tree)のデータストレージ構造に基づき、高同時実行トランザクション処理(TP)能力の継続的な最適化を通じて、ランダム書き込み、リアルタイム更新、強整合性などのシナリオでのパフォーマンスを向上させ続け、豊富なエンジニアリング実践経験を蓄積し、独自のストレージエンジン技術体系を構築してきました。同時に、LSM-Treeの階層メジャーコンパクション特性とデータの静的組織化能力により、バッチ書き込みと低頻度更新を特徴とするOLAPシナリオに本質的に適合しています。カラムナデータ圧縮、階層メジャーコンパクション戦略、ストレージ断片化の最適化により、分析型ワークロードの効率的なスキャン要件を満たしつつ、TPとAPの混合ワークロードを単一アーキテクチャでサポートすることを実現しています。
V4.3バージョンでは、既存の技術的蓄積に基づき、OceanBaseストレージエンジンをさらに拡張し、カラムナストレージのサポートを実現してストレージの統合を図りました。一つのコード、一つのアーキテクチャ、一つのOBServerで、カラムナデータと行指向データが共存し、TP型とAP型のクエリ性能を真に両立させています。
カラムナエンジンアーキテクチャ
OceanBaseデータベースは、ネイティブ分散型データベースとして、ユーザーデータをデフォルトでマルチレプリカで格納します。マルチレプリカの利点を活用し、ユーザーに強力なデータ検証やデータ移行の再利用などの拡張体験を提供するため、独自開発のLSM-Treeストレージエンジンにも多くの特化設計が施されています。まず、ユーザーデータ全体は大きく二つの部分に分けられます:ベースラインデータと増分データです。
ベースラインデータ
グローバル一貫性バージョン管理: 従来のLSM-Tree設計パラダイムを超え、OceanBaseデータベースは分散マルチレプリカアーキテクチャの基盤を活用して「日次マージ」メカニズムを実現しています。システムは定期的またはオンデマンドでグローバルバージョン番号を選定し、テナントは定期的またはユーザー操作に基づいてグローバルバージョン番号を選択します。すべてのレプリカはこのバージョンに基づいてメジャーコンパクションを完了し、このバージョンのベースラインデータを生成します。すべてのレプリカにおける同一バージョンのベースラインデータは物理的に完全に一致します。
多様なストレージ形式のサポート: ベースラインデータは、行指向、列指向、および行列混合の三つの物理形態をサポートしています。ユーザーはテーブル作成時の設定を通じて柔軟に選択でき、異なるビジネスシナリオのストレージ要件を満たせます。
増分データ
- 動的マルチバージョン管理: 最新のベースラインデータバージョン以降のすべての書き込み(MemTableに書き込まれたばかりのメモリデータ、またはSSTableにフラッシュされたディスクデータ)は増分データに分類されます。各レプリカは独立してマルチバージョンレコードを管理し、一貫性は保たれません。また、ベースラインデータが指定バージョンに基づいて生成されるのとは異なり、増分データにはすべてのマルチバージョンデータが含まれます。
- 行指向優先戦略: 増分データは強制的に行指向モードを採用し、トランザクション処理(TP)のパスがネイティブの行指向アーキテクチャと完全に互換性を持つことを保証します。これにより、トランザクションログやロック機構などのコアコンポーネントを共有できます。
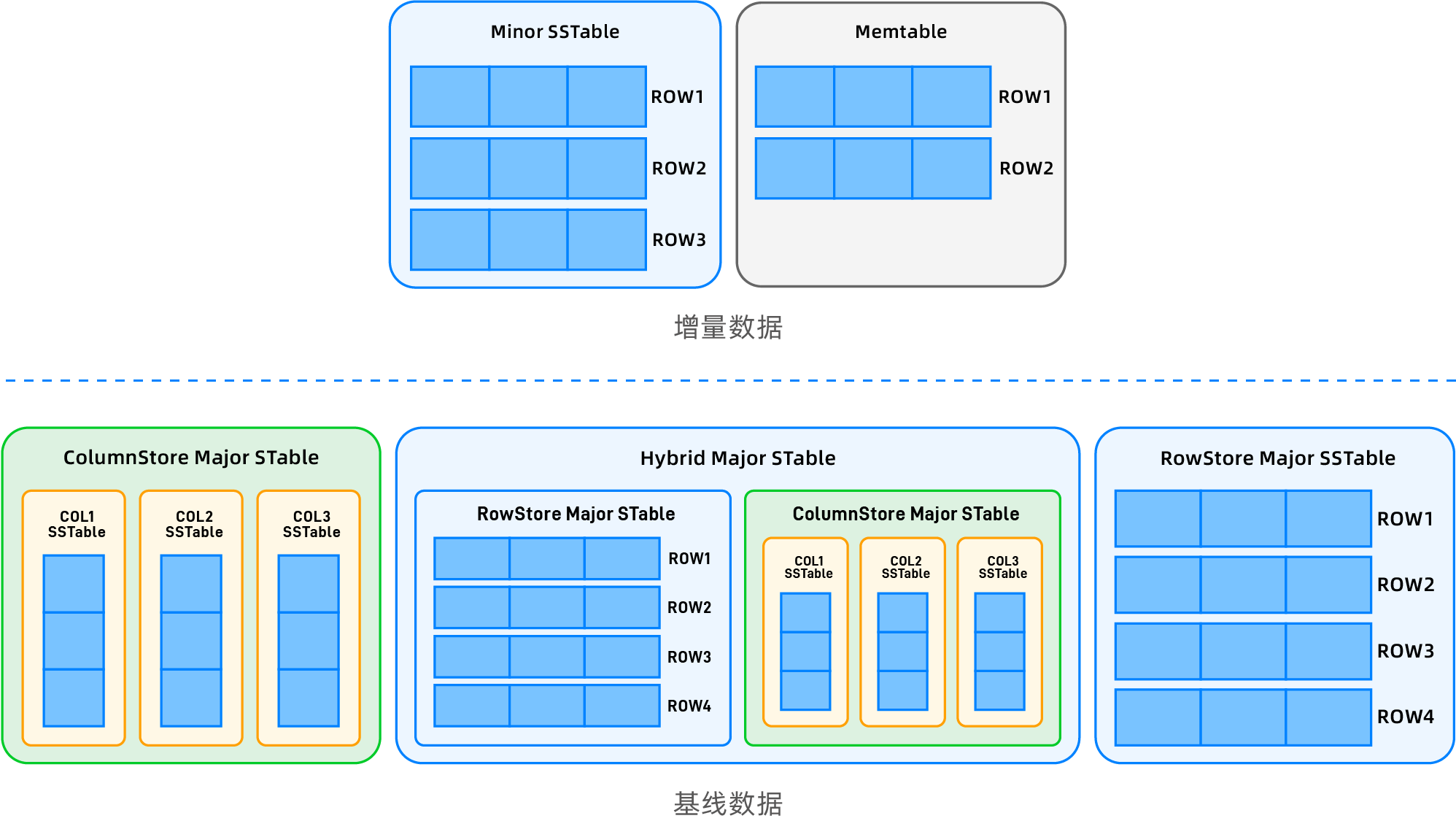
行列混合ストレージ体系
列指向ストレージのシナリオにおける更新制御の特性に基づき、OceanBaseデータベースは自身のベースラインデータと増分データの特性を組み合わせ、上位層に対して透過的な列指向ストレージの実装方法を提案しています:
- ストレージ形態の分離: ベースラインデータは列指向形式で構成され(各列は独立したSSTableとして、仮想的に論理テーブルに組み合わされる)、増分データは行指向形式を維持します。DML操作は上流・下流との同期を完全に意識することなく行われます。
- 動的同期エンジン: ベースとなる行列データの双方向同期パイプラインを構築し、OLAPシステムの移行や行指向から列指向へのアップグレードをスムーズに移行することをサポートします。ビジネス側はストレージ形式の違いを意識する必要はありません。
- インテリジェントなルーティング機構: オプティマイザーから実行エンジンまで、システムは負荷特性に基づいて最適な行/列アクセスパスを自動選択します。これにより、列指向ストレージの性能優位性をAPシナリオで十分に発揮させると同時に、行指向ストレージのTPトランザクションに対するネイティブサポートを維持します。
主要な統合機能
機能の観点 |
主要な技術実装 |
|---|---|
| SQLの統合 |
|
| ストレージの統合 |
|
| トランザクションの統合 |
|
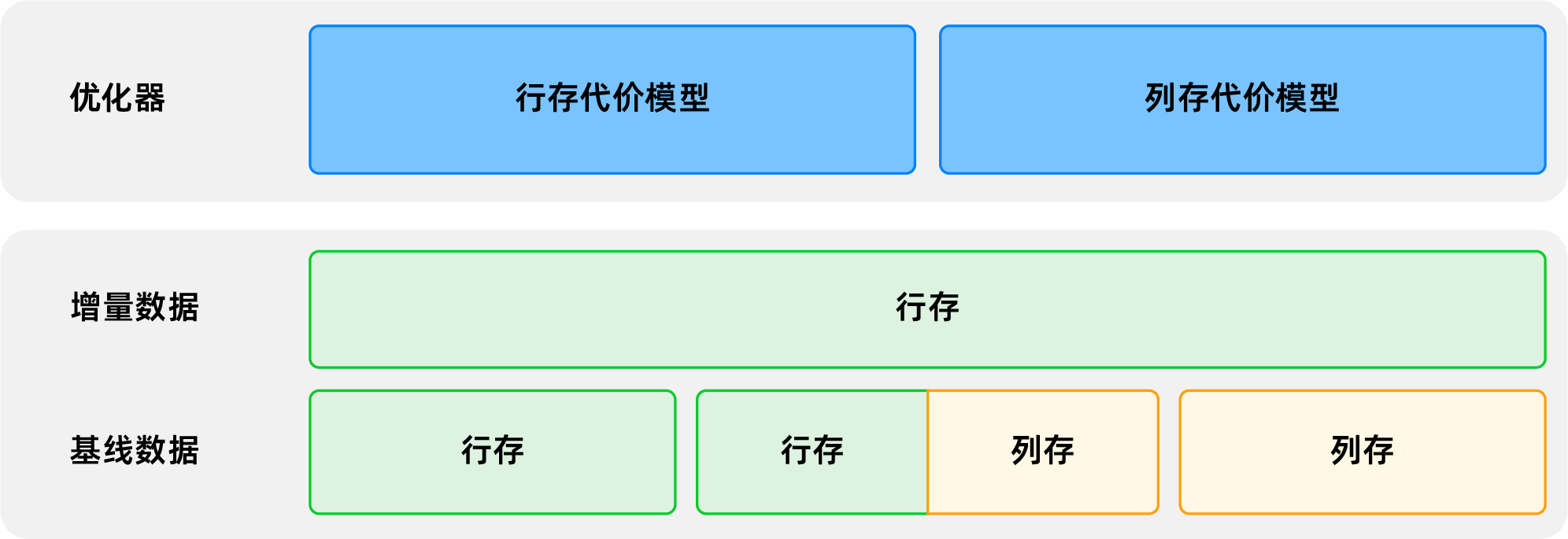
カラムストアの主な特徴
特徴1:適応型Compaction
新しいカラムストアの格納モードが導入されたことにより、データマージの動作は従来の行ストアと大きく異なります。増分データはすべて行ストアであるため、ベースラインデータとマージした後、各列の独立したSSTableに分割する必要があります。そのため、マージ時間とリソース使用量は行ストアに比べて大幅に増加します。カラムストアテーブルのマージを高速化するため、ストレージ層でもCompactionプロセスを最適化しています。カラムストアテーブルでは、行ストアテーブルと同様に水平分割による並列マージの高速化に加え、垂直分割による高速化も追加されました。カラムストアテーブルでは、複数列のマージ処理を1つのマージタスク内で実行し、タスク内の列数はシステムリソースに応じて自動的に調整可能です。これにより、全体としてマージ速度とメモリ消費のバランスをより良く実現します。
特徴2:列指向エンコーディングアルゴリズム
OceanBaseデータベースでは、データ保存時に2段階の圧縮が施されます。第1段階はOceanBase独自の行列混合エンコーディング圧縮であり、第2段階は汎用圧縮です。行列混合エンコーディングはデータベース組み込みアルゴリズムであるため、解凍せずに直接クエリが可能であり、エンコーディング情報を活用してクエリフィルタリングを高速化できます。しかし、従来の行列混合エンコーディングアルゴリズムは依然として行指向であったため、カラムストアテーブル向けに全く新しい列指向エンコーディングアルゴリズムを実装しました。新アルゴリズムは、従来のエンコーディングアルゴリズムと比較して、クエリの全面的なベクトル化実行をサポートし、異なる命令セットに対応したSIMD最適化をサポートします。また、数値型において圧縮率を大幅に向上させ、従来のアルゴリズムに比べて性能と圧縮率の両面で全面的な向上を実現しています。
特徴3:Skip Index
一般的なカラムストアデータベースでは、各列データに対して一定の粒度で事前集計計算を行い、集計結果をデータと共に永続化します。ユーザーがクエリ要求で列データにアクセスする際、データベースは事前集計されたデータを用いてデータをフィルタリングし、データアクセスのオーバヘッドを大幅に削減し、不要なI/O消費を抑えることができます。カラムストアエンジンにおいても、skip indexのサポートを追加しています。各列データに対してマイクロブロック粒度で最大値、最小値、null総数など複数の次元で集計計算を行い、段階的に上方向に集計累積してマクロブロック、SSTableなどのより大きな粒度の集計値を得ます。ユーザークエリはスキャン範囲に応じて適切な粒度の集計値を選択し、フィルタリングや集計出力を行うことができます。
特徴4:クエリのプッシュダウン
OceanBaseデータベースはV4.xバージョン以降、ストレージ層の演算子および式が全面的にベクトル化実行に対応し、一部のシナリオでクエリのプッシュダウンをサポートしています。カラムストアエンジンでは、プッシュダウン機能がさらに強化・拡張され、具体的には以下の通りです:
すべてのクエリfilterのプッシュダウン。同時にfilterのタイプに応じて、skip indexおよびエンコーディング情報を活用した高速化が可能です。
一般的な集約関数のプッシュダウン。non group byシナリオにおいて、現在count/max/min/sum/avgなどの集約関数はストレージエンジンまでプッシュダウン可能です。
group byのプッシュダウン。NDVが少ない列において、group byのストレージ計算をプッシュダウンし、マイクロブロック内のディクショナリ情報を活用して大幅に高速化します。
カラムストアの詳細な紹介と使用方法については、カラムストアを参照してください。
共有ストレージモード
OceanBaseデータベースは、**シェアードナッシング(Shared-Nothing、SN)モードと共有ストレージ(Shared-Storage、SS)**モードの2種類のデプロイメントモードをサポートしています。
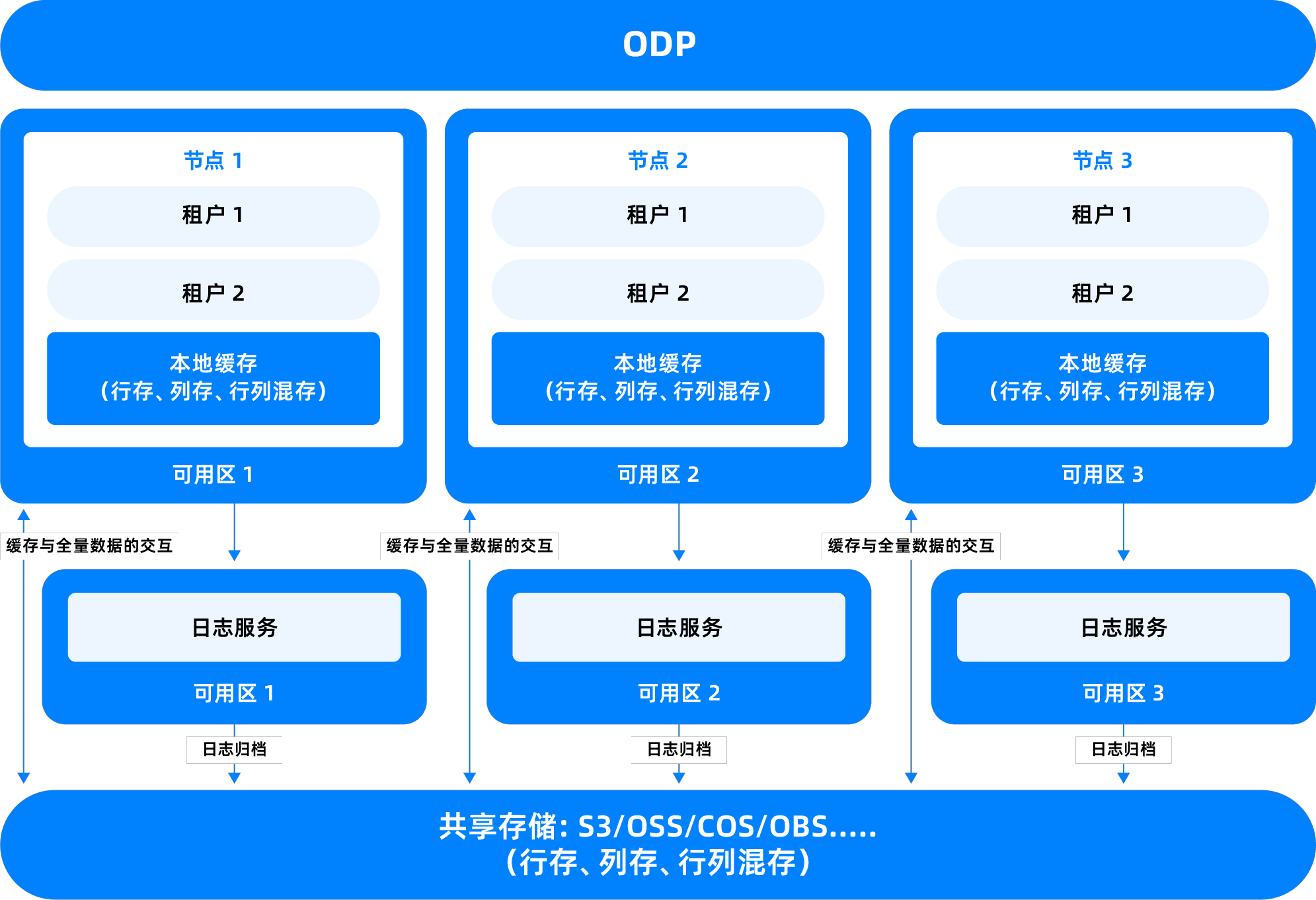
共有ストレージ(Shared-Storage)モードは、データを共有ストレージデバイスに一元化して格納し、複数のデータベースノードが同一データにアクセスできるアーキテクチャであり、パブリッククラウドで利用されます。このモードは主に、ストレージ管理の簡素化、リソース利用率の向上、および特定のシナリオにおけるより柔軟な高可用性フェイルオーバーをサポートするために使用されます。
**ストレージ冗長性の削減:**従来のシェアードナッシングアーキテクチャでは、各ノードが独立したデータレプリカを保持していたため、ストレージリソースの無駄遣いが発生しやすかったです。一方、共有ストレージでは、複数のコンピューティングノードが同一データを読み取ることが可能で、レプリカ数を削減することで、全体のストレージコストを削減できます。
**迅速な障害回復:**あるコンピューティングノードがダウンした場合、他のノードは共有ストレージ内のデータに直接アクセスできるため、複雑なレプリカ同期や移行プロセスに依存せず、より迅速なサービス引き継ぎが実現されます。
**運用保守管理の簡素化:**統一されたストレージプールにより、バックアップ、スナップショット、監視などの操作が容易になり、データベースシステムのメンテナビリティが向上します。
OceanBaseのストレージ・コンピューティング分離型2レプリカアーキテクチャにより、以下が実現されます:
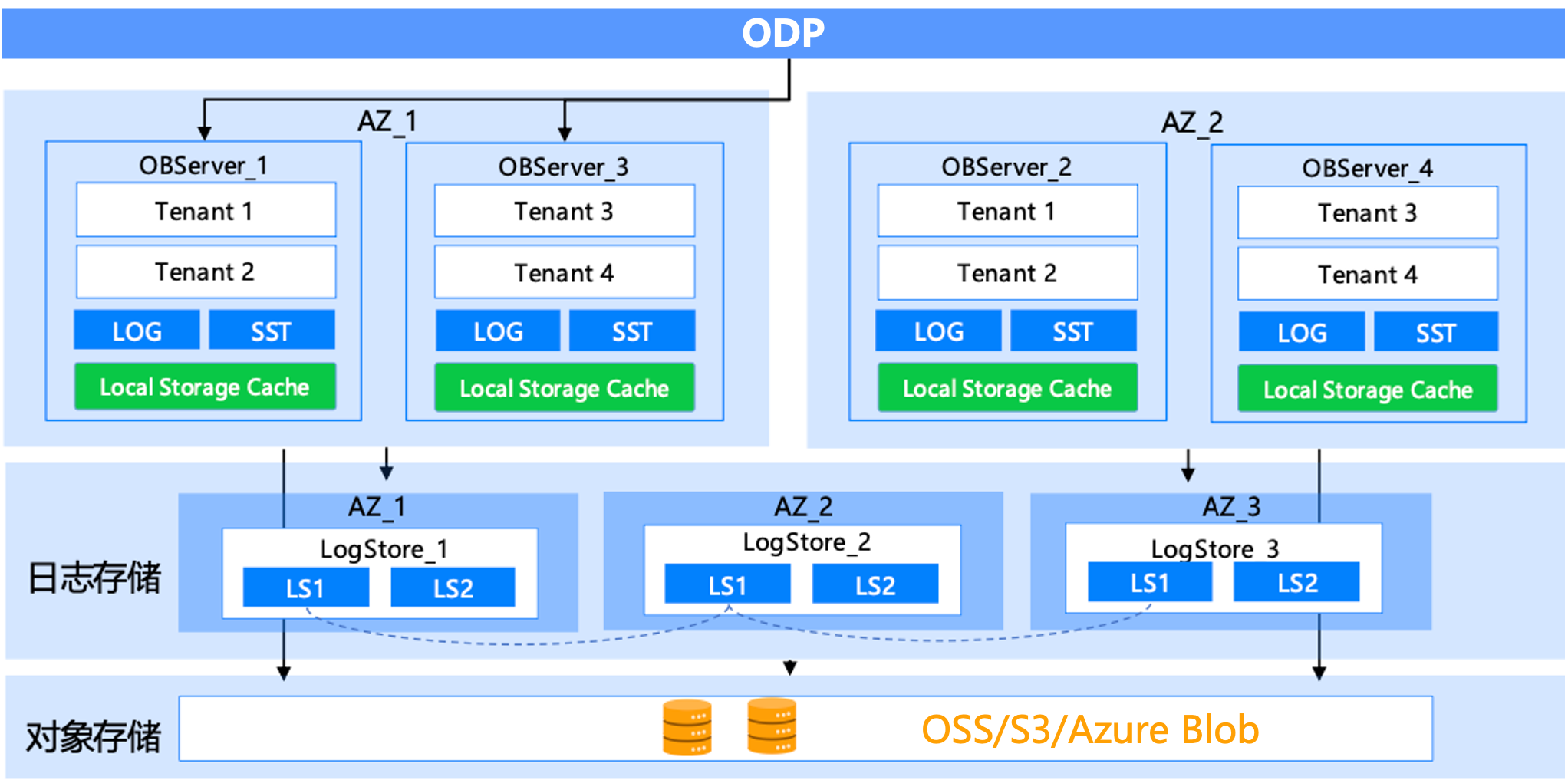
- **低コスト:**全量データをオブジェクトストレージに保存し、ホットデータをローカルディスクにキャッシュすることで、ストレージコストを削減しながらP99クエリ性能を保証します。また、弾力的なスケーラビリティを備えており、コンピューティングとストレージを個別に拡張・縮小できます。性能損失は、シェアードナッシングアーキテクチャと比較して平均で0.3%~1.7%です。
- **高可用性:**2Fデュアルレプリカデプロイメントモードによりコンピューティングノードの高可用性が保証され、Paxosベースの独立ログストレージサービスと組み合わせることで、システムはRPO=0、RTO<8sを保証します。
OceanBaseのストレージ・コンピューティング分離型シングルレプリカアーキテクチャにより、以下が実現されます:
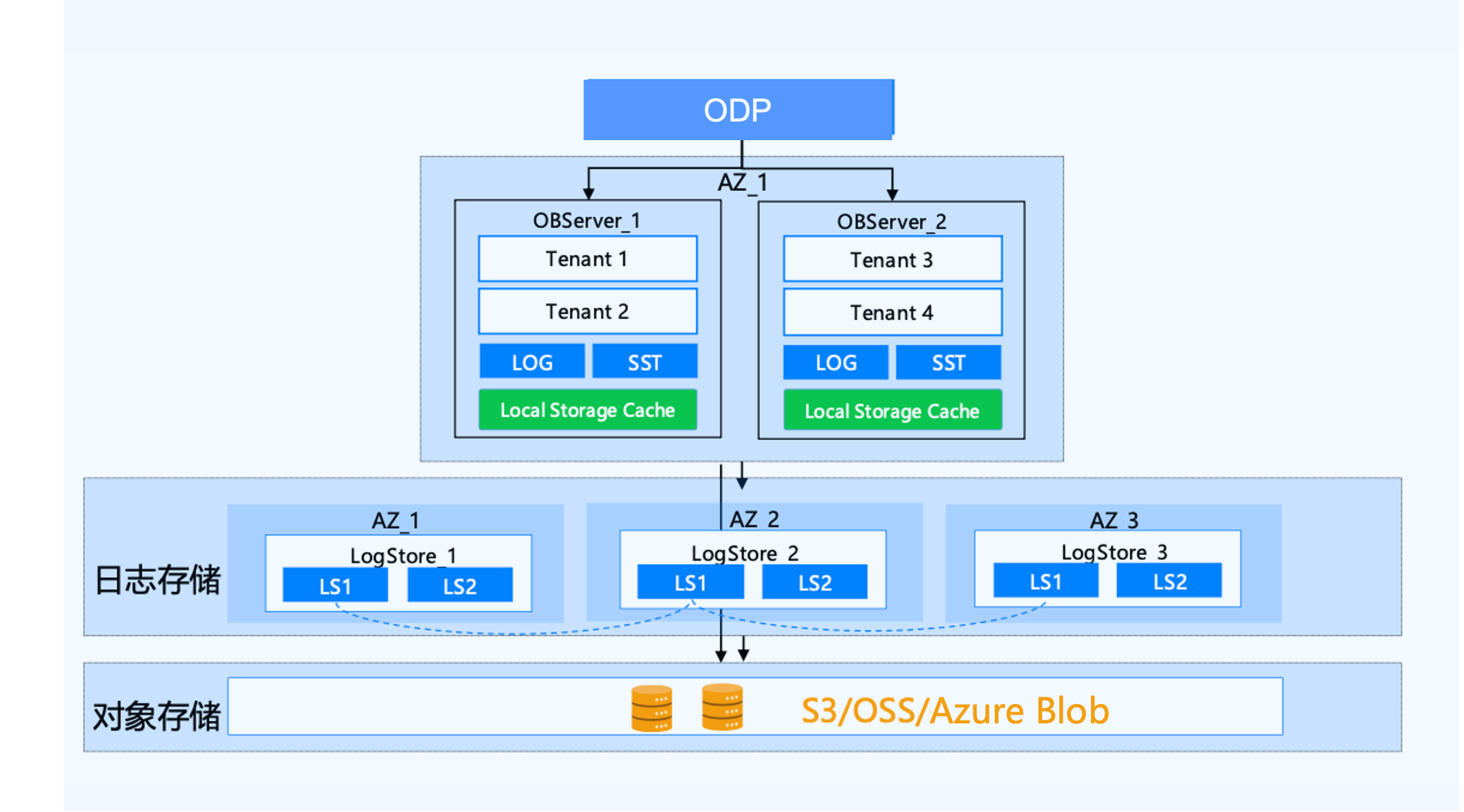
**抜群のコストパフォーマンス:**全量データを低コストのオブジェクトストレージに保存し、ホットデータをローカルディスクにキャッシュします。シングルレプリカ構成により、2F1Aや3Fなどのクラスタ構成と比較して、コンピューティングコストを2~3倍削減できます。単一ゾーン内でも、変化するパフォーマンス要件に応じて、コンピューティングノードの迅速な追加・削除をサポートします。
**高可用性:**同一都市内に冗長化されたオブジェクトストレージにより、データセンターレベルの災害復旧が可能です。シングルレプリカ構成においても、Paxosベースの独立ログサービスおよび共有ストレージと組み合わせることで、コンピューティングノードがダウンした場合でも、新しいコンピューティングノードを迅速に起動し、高可用性を提供します。
ベクトル化実行エンジン
ベクトル化実行は、データを効率的にバッチ処理する技術です。分析系クエリにおいて、ベクトル化実行は実行性能を大幅に向上させることができます。OceanBaseデータベースはV3.2バージョンでベクトル化実行エンジンを導入しましたが、デフォルトでは無効でした。OceanBaseデータベースV4.0バージョンから、ベクトル化実行エンジンはデフォルトで有効になり、OceanBaseデータベースV4.3バージョンではベクトル化エンジン2.0が実装されました。データ形式、演算子の実装最適化、ストレージのベクトル化最適化などにより、ベクトル化エンジンの実行性能が大幅に向上しています。
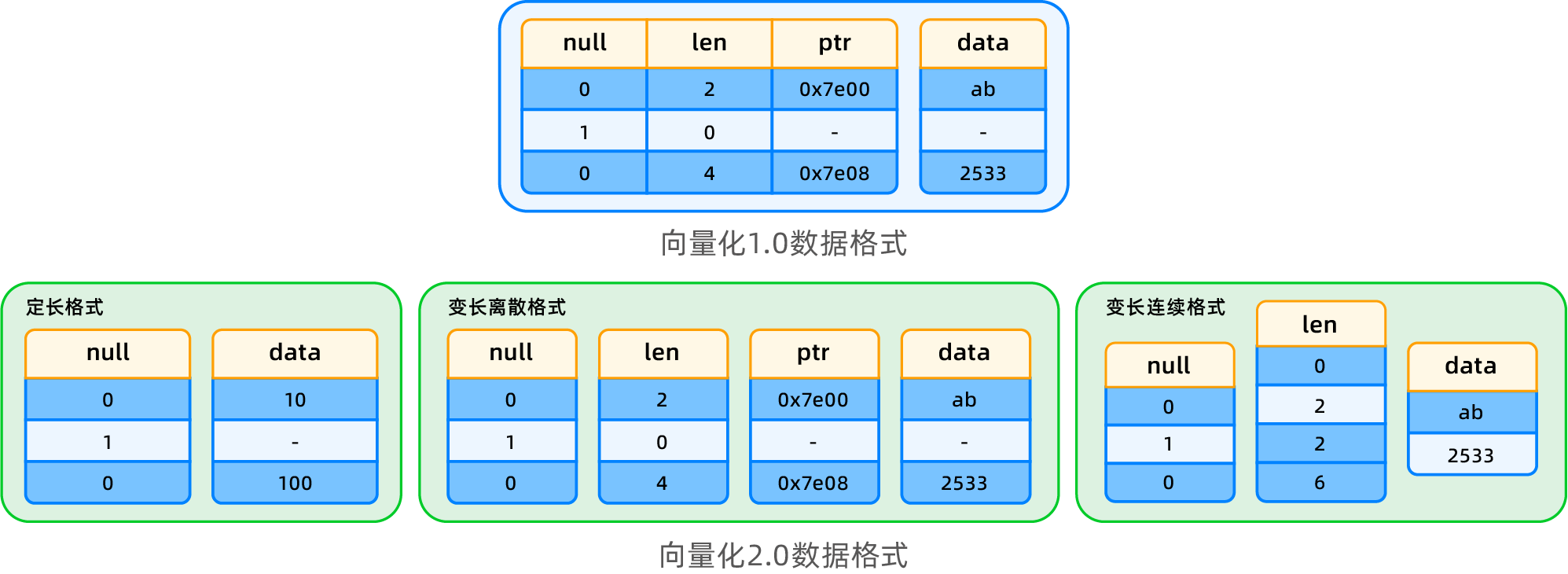
データ形式の概要
ベクトル化エンジン2.0では、新しい列単位のデータ形式が導入され、データ記述情報(NULL、len、ptr)をそれぞれ列ごとに分けて格納することで、冗長なストレージを回避しています。異なるデータ型と使用シナリオに基づき、3種類のデータ形式が設計されています:固定長データ形式、可変長離散形式、可変長連続形式。
- 固定長データ形式: length値は一度だけ格納すればよく、冗長な格納は不要で、直接アクセスが可能です。データの局所性に優れており、1.0バージョンと比較して、スペースの節約、効率の向上が図られ、ポインタのswizzling操作も省略されています。
- 可変長離散形式: 各データはメモリ内で連続していない可能性があり、アドレスポインタと長さで記述されます。この形式では、データをエンコードする際にディープコピーを回避でき、ショートサーキット計算シナリオに適しており、データの再構成を回避します。
- 可変長連続形式: データはメモリ内で連続して格納され、長さ情報とオフセットアドレスはoffset配列によって記述されます。この形式はデータアクセスの効率を向上させますが、ショートサーキット計算や列ストアエンコーディングのプロジェクション時には再構成とディープコピーが必要となります。この形式は主に列単位のマテリアライズシナリオで使用されます。
演算子および式のパフォーマンス最適化
ベクトル化エンジン2.0では、演算子と式が全面的に最適化されています。コアとなる考え方は、新しい形式の情報とデータ構造の特化実装を活用し、CPUキャッシュミスと命令オーバヘッドを削減し、全体の実行性能を向上させることです。主な最適化は以下の通りです:
- batchデータ属性情報の活用: batchデータの特徴情報を維持し、NULLへの特別処理やフィルタリング判断を排除することで、SIMD計算を最適化します。
- アルゴリズムとデータ構造の最適化: 中間結果のマテリアライズ構造を最適化し、行/列マテリアライズをサポートしています。Sort演算子では、ソートキーと非ソートキーの分離マテリアライズを実装し、ソート処理中のキャッシュミスを削減し、全体の効率を向上させています。
- 特化実装による最適化: 具体のシナリオに応じた最適化を行っています。例えば、複数列の固定長join keyを一つの固定長列にエンコードする方法や、集約計算の特化実装により、実行効率が大幅に向上しています。
ストレージのベクトル化最適化
ストレージ層は新しいベクトル化形式を全面的にサポートしており、SIMDによるプロジェクション高速化、述語プッシュダウン、集約プッシュダウン、groupbyプッシュダウンなどの操作を提供します。プロジェクション時には列タイプと長さに応じたカスタマイズテンプレートを使用し、計算を簡略化します。述語計算は列エンコード上で直接行われ、複雑な式の高速計算を実現します。集約プッシュダウンは中間層の事前集約情報を活用し、統計関数を効率的に処理します。groupbyプッシュダウンはエンコードされたデータ情報を活用し、性能を大幅に向上させます。
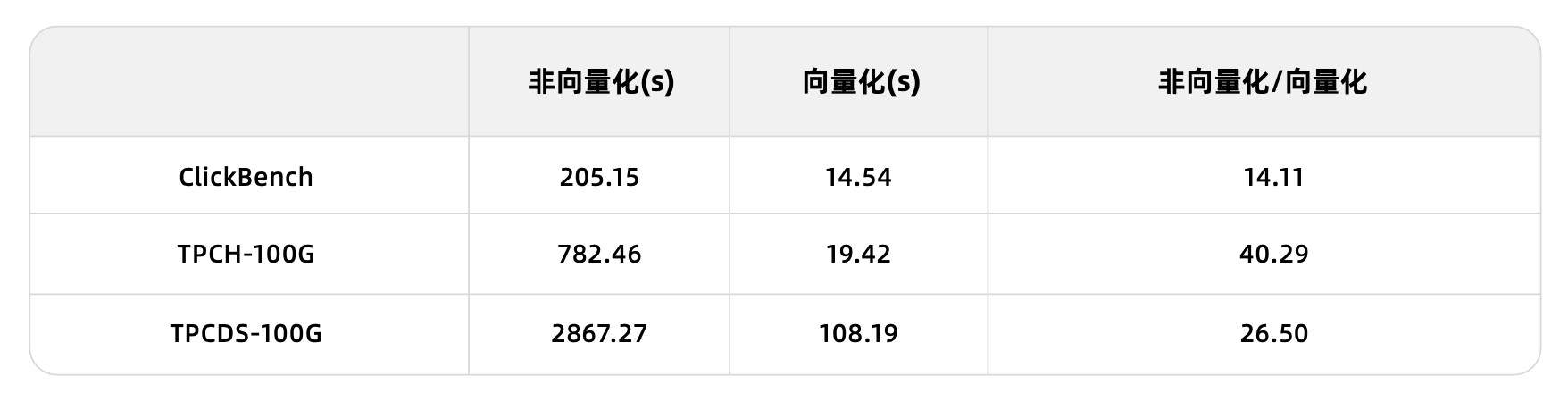
全体的な性能において、OceanBaseデータベースのベクトル化オン/オフでのベンチマーク比較では、ベクトル化エンジンは非ベクトル化エンジンと比較して、性能が1桁向上しています:
リアルタイム書き込み
OceanBaseはLSM-Tree(Log-Structured Merge-tree)アーキテクチャを採用しており、この設計によりデータベースのリアルタイム書き込み機能が保証されています。以下では、OceanBaseデータベースのリアルタイム書き込み機能について詳しく説明します。
コアストレージメカニズム
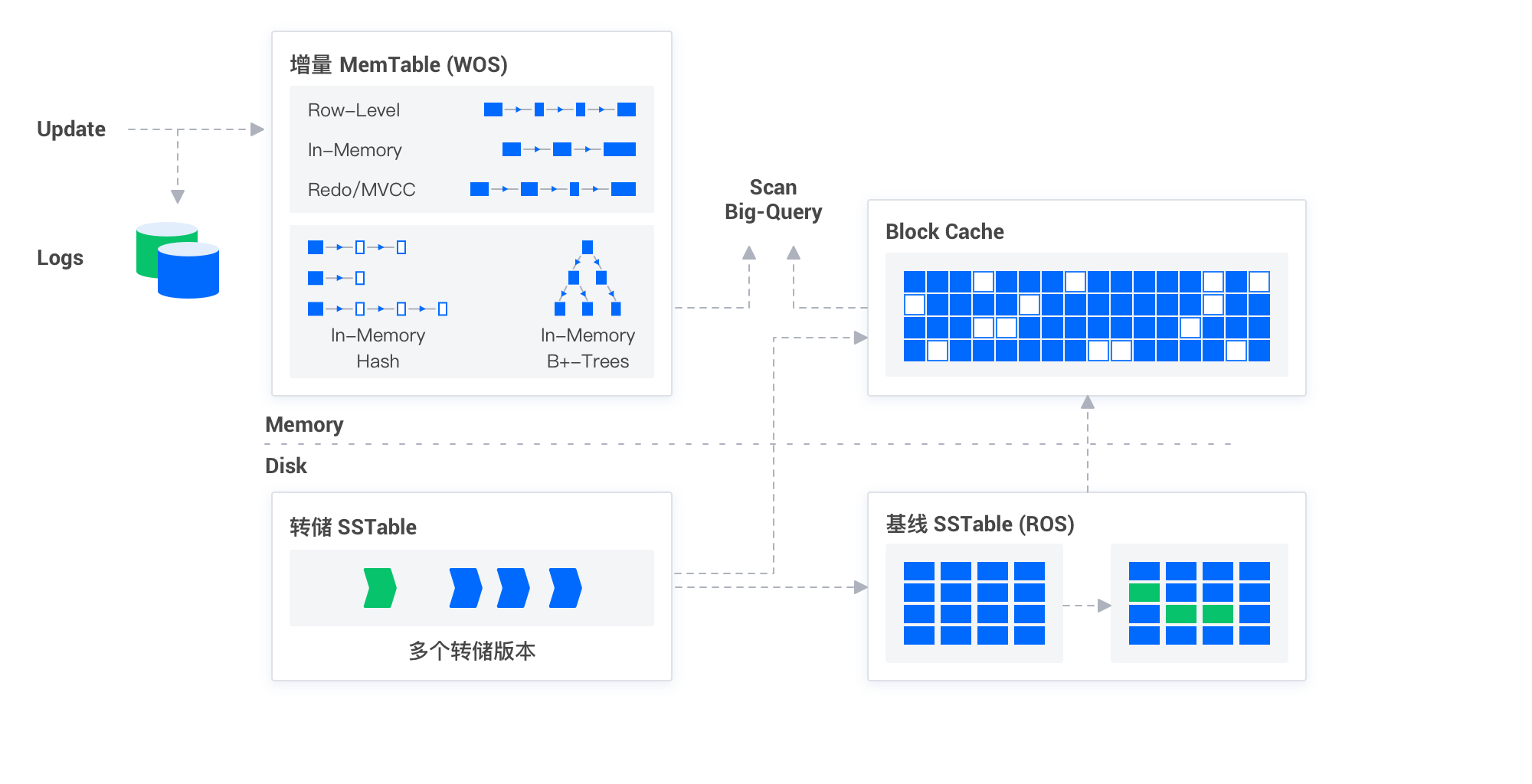
LSM-Tree
効率的なリアルタイム書き込みをサポートするため、OceanBaseはLSM-Tree構造を採用して増分データを格納します。LSM-Treeは書き込み操作を最適化するために特別に設計されたツリー構造です。そのコアとなる考え方は、書き込み操作をまずメモリ内の構造に記録し、一定量に達した後に非同期でバッチ処理としてディスクに書き込むことで、ディスクI/Oの回数を大幅に減らし、書き込み性能を向上させることです。OceanBaseはこれらの増分データを定期的にダンプおよびマージプロセスを通じてベースラインデータと統合し、データの一貫性と完全性を確保します。
リアルタイム書き込み機能
OceanBaseデータベースはLSM-Treeアーキテクチャを採用しており、リアルタイムデータの書き込み処理において優れたパフォーマンスを発揮します。少量のデータ更新であっても大量のデータインポートであっても、OceanBaseデータベースは迅速に応答し、データのリアルタイム書き込みを保証します。主な利点は以下の点です:
- 効率的な書き込み処理: LSM-Treeにより、OceanBaseデータベースは書き込み操作を集中的に処理し、ディスク操作を削減して書き込み効率を向上させます。
- データの即時検索可能性: データがLSM-Treeのメモリ構造に書き込まれると、すぐに外部へのクエリ提供が可能となり、データのリアルタイム性が保証されます。
- 最適化されたデータマージプロセス: インテリジェントなダンプおよびマージ戦略により、効率的なクエリをサポートします。
- 強力な並行処理能力: 分散アーキテクチャを活用することで、OceanBaseデータベースは複数ノード上で書き込み操作を並列処理でき、リアルタイムデータ処理能力を大幅に向上させます。
スマートマテリアライズドビュー
スマートマテリアライズドビューの核心的価値は、ユーザーがSQLを用いてデータ処理結果を定義するだけで、OceanBaseが自動的にデータのリフレッシュと計算依存関係を管理してくれる点にあります。これにより、企業は複雑なETLスクリプトを記述したり、データパイプラインを管理したりする必要がなく、ターゲットデータ構造を定義するだけで、OceanBaseが自動的にデータのリフレッシュ、依存関係管理、パフォーマンス最適化を行います。この方法はデータエンジニアリングのプロセスを大幅に簡素化し、運用コストを削減するとともに、データの鮮度と一貫性を確保します。
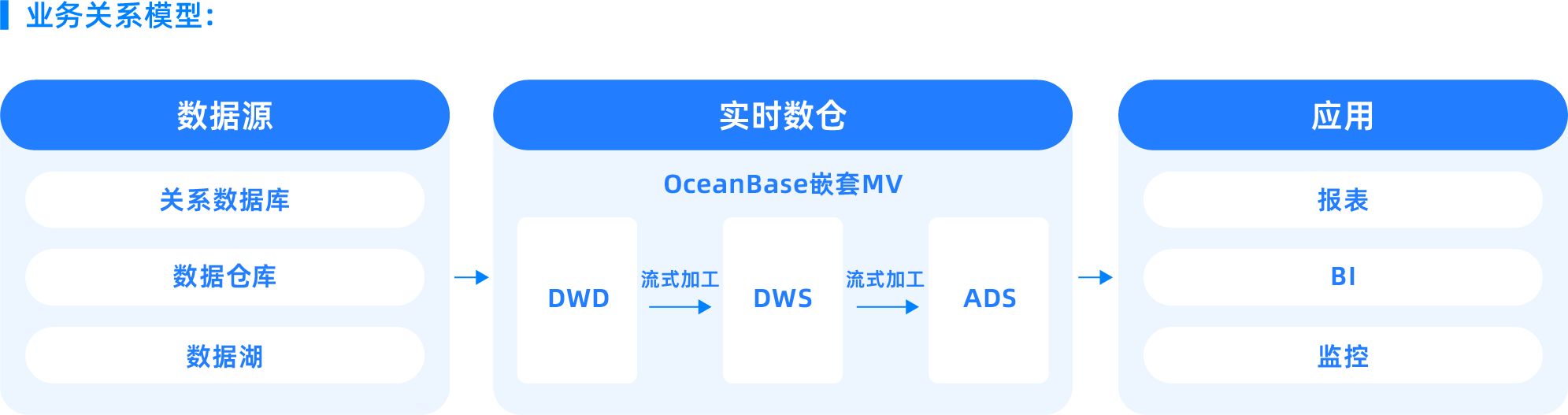
OceanBaseデータベースがサポートするのは非同期マテリアライズドビューです。つまり、ベーステーブルのデータが変更されても、マテリアライズドビューは即座に更新されず、ベーステーブルのDML操作の実行パフォーマンスが保証されます。ただし、マテリアライズドビューのデータはベーステーブルに対して遅延が生じるため、タイムリーなリフレッシュによるデータ更新が必要です。マテリアライズドビューのデータ更新には、全量リフレッシュと増分リフレッシュの2つの戦略がサポートされています。
- 全量リフレッシュは、マテリアライズドビューに対応するクエリステートメントを直接再実行し、既存のビュー結果データを完全に計算して上書きします。これは、遅延要件が低く、ベーステーブルのデータ更新頻度が低い、またはデータ量が少ないシナリオに適しています。例えば、毎日または毎週更新されるデータ集計レポートなどが該当します。
- 増分リフレッシュは、前回のリフレッシュ以降のデータ変更部分のみを処理します。この方法により、リフレッシュに必要な時間とリソースを大幅に削減できます。正確な増分リフレッシュを実現するために、OceanBaseデータベースはOracle MLOG(Materialized View Log)に類似したマテリアライズドビューのログ機能を実装しています。これにより、ベーステーブルの増分更新データを詳細に記録し、マテリアライズドビューが迅速に増分リフレッシュできるようにします。増分リフレッシュ方式は、特に遅延要件が高く、データ量が膨大で変更頻度が高い業務シナリオに適しています。例えば、リアルタイム取引システムでは、データが毎分、あるいは毎秒変化している可能性があります。
OceanBaseデータベースは、リアルタイムマテリアライズドビューもサポートしており、データのリアルタイム分析を可能にします。リアルタイムマテリアライズドビューは、マテリアライズドビューのログメカニズムを利用してベーステーブルデータの変更をキャプチャ・処理し、クエリ時にオンラインで計算・統合します。これにより、マテリアライズドビューに最新の変更データが物理的に格納されていなくても、ユーザーがベーステーブルを直接クエリした場合と一致する結果を確実に得られます。同時に、マテリアライズドビューのクエリリライト機能を活用することで、透過的なクエリ高速化を実現します。
OceanBaseデータベースでは、マテリアライズドビューに主キーを指定したり、インデックスを作成したりすることができ、これにより主キーまたはインデックスに基づく単一行検索、範囲検索、連携シナリオのパフォーマンスを最適化できます。マテリアライズドビューが複数テーブルのJOINによって形成されたワイドテーブルの場合、カラムストア形式のマテリアライズドビューを作成することで、特定のクエリのパフォーマンスを向上させることができます。また、パーティションマテリアライズドビューを作成することで、パーティションプルーニングの機能を活用し、操作対象のデータ量を削減できます。
最新のOceanBase V4.3.5バージョンでは、ネストされたマテリアライズドビュー(Nested Materialized View, Nested MV)機能が導入されました。これにより、既存のマテリアライズドビューを基に新たなマテリアライズドビューを容易に構築できるようになり、データウェアハウスのETLプロセスに適しています。つまり、ネストされたマテリアライズドビューは、データ変換およびロード段階で中間結果を生成し、これらの結果を後続処理の入力として利用することで、データ処理プロセス全体の効率をさらに最適化できます。
マテリアライズドビューの詳細な説明と使用ガイドについては、マテリアライズドビューの概要(MySQLモード)およびマテリアライズドビューの概要(Oracleモード)を参照してください。
スマートマテリアライズドビューの主要な特徴:
- 宣言型SQL定義: スマートマテリアライズドビューは、ユーザーがデータ処理結果を宣言的に定義できるようにし、変換ステップを手動で管理する必要がありません。ユーザーは標準SQLクエリを記述してデータ変換ロジックを指定するだけで、OceanBaseがこれらのクエリの実行とメンテナンスを担当します。
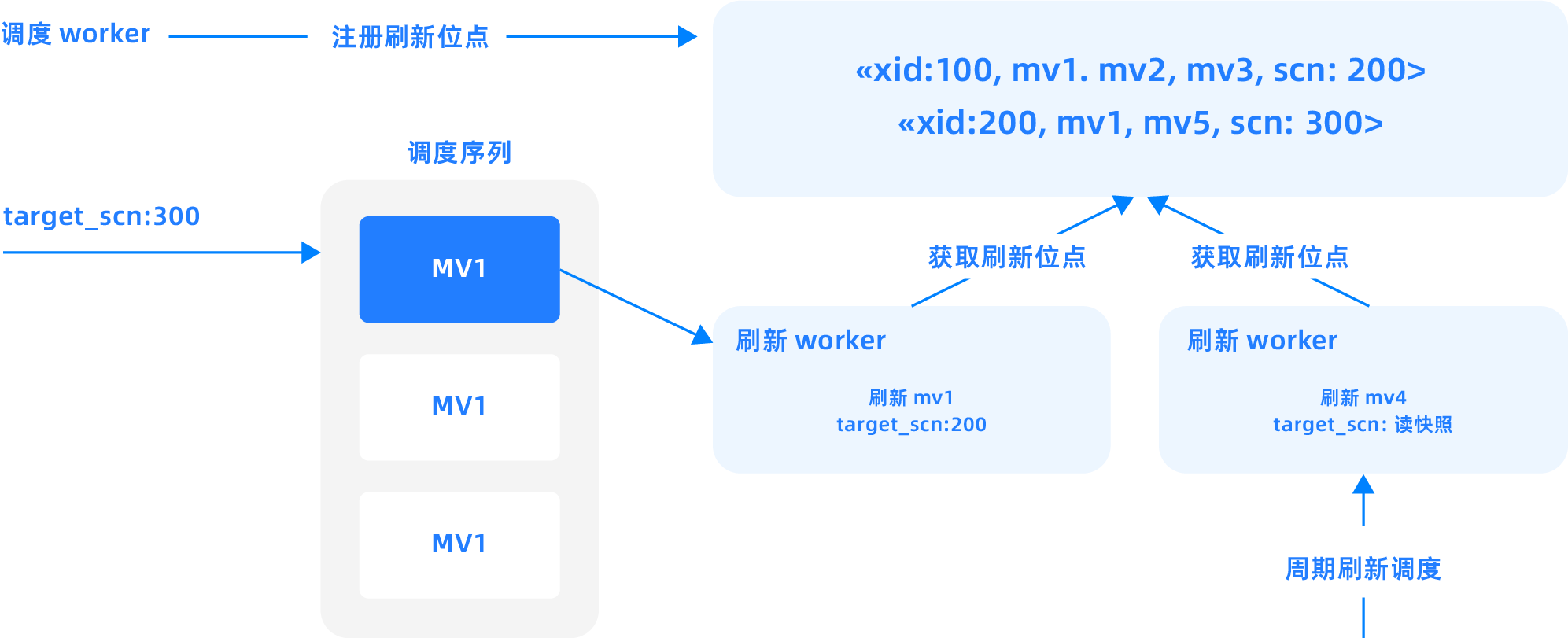
- 自動リフレッシュメカニズム: OceanBaseは、ユーザーが指定したターゲットデータの鮮度要件に基づいて、データリフレッシュの連鎖関係を自動的に処理し、スケジューリングと実行を含みます。ユーザーはデータが保持すべき最新度、例えば30秒または5分の目標遅延を定義するだけで、OceanBaseが自動的にデータがこの要件を満たしていることを保証します。
- 増分処理の最適化: スマートマテリアライズドビューは、自動増分ビュー維持技術を使用し、前回のリフレッシュ以降の変更のみを計算し、全量リフレッシュを実行することはありません。これにより、パフォーマンスが大幅に向上し、計算コストが削減されます。
- 依存関係管理: スマートマテリアライズドビューは、データ依存関係を自動的に追跡し、ベースデータが変更された際に正しい順序でリフレッシュされることを保証します。これにより、複雑なデータパイプラインの依存関係を手動で管理する必要がなくなります。
オプティマイザー
OceanBaseデータベースのクエリオプティマイザーは、HTAP混合ワークロードとリアルタイム分析シナリオ向けに設計されています。一般的に、トランザクション型ワークロードには以下の典型的な特徴があります:単一クエリでアクセスするデータ量が少なく、応答時間(RT)の要件が高く、スループットが高いこと。分析型ワークロードには以下の典型的な特徴があります:単一クエリでアクセスするデータ量が多く、スループットが相対的に低いこと。異なるタイプのワークロードでは、必要とされる実行計画の形態やチューニング方法も大きく異なります。
- トランザクションワークロードでは、通常、ベーステーブルのフィルターパラドックスと結合パラドックスに対して適切なインデックス構造を作成する必要があります。各テーブルについて可能な限り適切なインデックスパスを選択し、データスキャン量を大幅に削減することが求められます。
- 分析ワークロードでは、通常、カラムストアに依存して全表スキャンを行い、skipindexを使用して一部のデータブロックのスキャンを迅速にスキップします。並列度を高めることで、クエリの応答時間を短縮します。
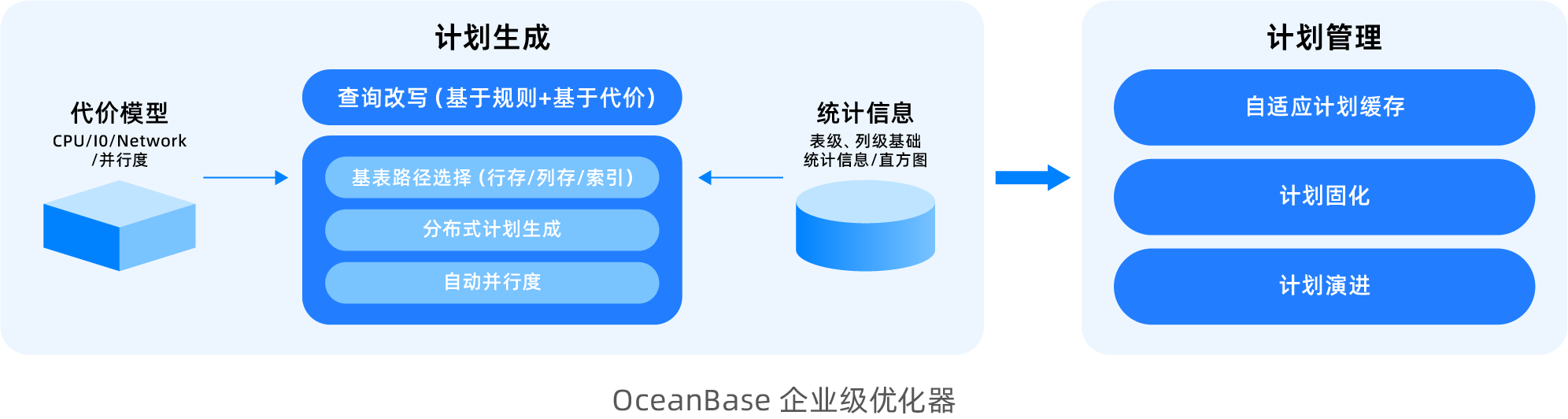
OceanBase APオプティマイザーは、TPオプティマイザーの機能を完全に継承しつつ、さまざまな複雑なクエリシナリオに対して、各モジュールを専門的に強化しています。
より完全なクエリリライト機能: クエリリライトモジュールは豊富なリライトアルゴリズムをサポートしており、異なるリライトアルゴリズムは異なるパターンにマッチし、対応する等価変換を行って、業務SQLをより「良い」方向に変換します。現在、ビューのマージ、サブクエリの向上、内部結合の除去、外部結合の除去、常に真または偽の条件の除去など、ルールベースのリライトアルゴリズムをサポートしているほか、OR Expansion、JAサブクエリの向上、Win Magic、Group-By Placementなど、コストベースのリライトアルゴリズムもサポートしています。
分散計画生成: OceanBaseは、段階的な分散計画生成方式を採用しています。これは、一般的なデータベースシステムが採用する2段階分散計画生成とは大きく異なります。一般的なシステムは通常、まず最適な単一マシン計画を生成し、その後それを分散化することでオプティマイザーの設計を簡略化します。しかし、この方法はHTAPシナリオではより多くの問題に直面します。例えば、結合の列挙過程において、単一マシンシナリオで最適なNEST-LOOP JOINアルゴリズムが、分散化後には大量のマシン間データアクセスを発生させ、全体の実行効率が分散HASH JOINアルゴリズムよりも著しく低下する可能性があります。OceanBaseの段階的計画生成フレームワークは、結合順序や結合アルゴリズムを列挙する過程で、データの分布特性や並列化などの要因が計画選択に与える影響を同時に考慮し、多様な要因を総合的に判断して、全体的により優れた分散実行計画を選択します。
行・列パスの選択: HTAP混合ワークロードを適切に処理するために、クエリオプティマイザーの核心的なインテリジェント最適化機能の一つは、自動的な行・列パスの選択です。これは、あるクエリに対して、オプティマイザーがそのデータアクセス特性に基づき、最適な実行性能を達成するために、行ストア(Row Store)からデータを読み取るか、カラムストア(Column Store)からデータを読み取るかをインテリジェントに決定することを意味します。OceanBaseは、カラムストアスキャンに特化したコストモデルを設計し、新しい統計情報メカニズムを導入して、カラムストアSkipIndexがカラムストアスキャンにもたらすメリットを正確に評価し、行ストアインデックスとカラムストアスキャンの間で正確な選択を保証します。
使いやすいAuto DOP: 通常、データベースは並列実行を使用して複雑なSQLの実行を高速化しますが、実際の業務シナリオでは、並列を有効にするかどうかや並列度の大きさを容易に評価することは難しいです。OceanBaseはAuto DOP機能を提供しており、オプティマイザーは計画生成時にクエリの実行時間を評価し、並列を有効にするかどうかと適切な並列度を自動的に判断します。これにより、SQLはデフォルトで比較的良好な性能を得ることができます。
実行計画管理: OceanBaseのSPM(SQL Plan Management、SQL実行計画管理)技術は、リアルタイム分析型業務の安定した長期運用を保証するための重要な技術です。データ量の急激な変化、統計情報の更新、またはデータベースバージョンのアップグレード後に、オプティマイザーがより劣る新しい実行計画を選択する可能性に対処するため、実行計画の進化をインテリジェントに管理します。実際のトラフィックによるグレースケール検証を通じて、実行計画の逆戻りを防ぎます。
詳細については、統計情報と推定行メカニズムの概要を参照してください。
特殊インデックス
従来のリレーショナルデータベースでは、B-Tree や Hash などのインデックスは、主に構造化データの厳密値検索(数値、日付など)を対象としています。しかし、実際の業務では、半構造化データ(JSON ドキュメントなど)や非構造化テキスト(ログ、長文)、さらに多次元分析シナリオの普及に伴い、OceanBase は以下の 2 種類の特殊インデックスを提供しています:
- 全文インデックス: 逆インデックスに基づいて実装され、分かち書き技術を用いてテキスト内容に対するキーワードマッピングを構築します。ログ分析や文書検索などのシナリオに適しています。
- 複数値インデックス: JSON 配列フィールドに対して要素レベルのインデックスを構築し、配列を仮想行レコードに展開して B-Tree インデックスを作成することで、集合データのクエリ効率を大幅に向上させます。
これら 2 種類のインデックスは、それぞれ異なるデータ構造設計により、異なるデータ型(テキスト/JSON)とクエリパターン(あいまい一致)に対して最適化を提供し、複雑なデータクエリの高速化レイヤーを共同で構成しています。
全文インデックス
リレーショナルデータベースでは、インデックスは通常、厳密値検索のクエリを高速化するために使用されます。しかし、従来の B-Tree インデックスは、大量のテキストデータやあいまい検索を処理する際、性能要件を満たせないことがよくあります。この場合、全表スキャンを実行して各行を順に照合する方法では、特にテキスト量が多くデータ量が膨大なシナリオにおいて、性能ボトルネックが発生します。また、近似一致や相関性ソートなどの複雑なクエリ要件も、単純な SQL の書き換えだけでは実現が困難です。
これらの問題を解決するため、OceanBase は現在、MySQL 互換の全文インデックス機能をサポートしています。全文インデックスは、テキスト内容を事前処理してキーワードインデックスを構築することで、全文検索の効率を大幅に向上させます。
全文インデックスは、テキストデータを迅速に検索するための技術であり、その主な機能は以下の通りです:
- 全文検索: 全文インデックスを構築することで、文書全体や長いテキスト内容を包括的にインデックス化し、より柔軟で効率的な検索を実現します。
- 迅速な検索: ユーザーは入力したキーワードに基づいてデータベース内で一致するテキストを迅速に検索でき、検索時間を大幅に短縮できます。
- 大量のテキストを効率的に処理する: 全文インデックスは、記事、レポート、ウェブページ、電子メールなど、さまざまな種類のテキストデータを効果的に処理でき、ユーザーに正確で迅速な検索体験を提供します。
- 複雑なクエリをサポートする: 基本的なキーワード検索に加え、全文インデックスは近似一致や相関性ソートなどの複雑なクエリ要件もサポートし、データベースの検索機能を大幅に豊かにします。
全文インデックス機能を導入することで、OceanBase は大規模なテキストデータや複雑な検索要件に直面した際に、クエリ性能を大幅に向上させることができ、ユーザーが必要な情報をより効率的に取得できるようにします。
全文インデックスの詳細な説明と使用方法については、全文インデックス(MySQLモード) を参照してください。
複数値インデックス
複数値インデックスは、OceanBase データベースの MySQL モードにおける特殊なインデックス機能であり、主に JSON ドキュメントと集合データ型の処理に使用されます。複数の値や属性を検索する必要があるシナリオに適しています。その主な特徴は以下の通りです:
- 配列や集合にインデックスを作成できます。
- 現在は JSON ドキュメントに適用されます。
- JSON 配列要素に基づく検索のクエリ効率を向上させることができます。
複数値インデックスは AP シナリオで非常に有用です。AP シナリオは通常、複雑なデータ分析やレポート生成を伴いますが、複数値インデックスはこれらの操作を高速化できます。例えば、データウェアハウスでは、複数値インデックスを使用して多次元のデータ分析を高速化し、レポート生成の効率を向上させることができます。具体的な適用シナリオは以下の通りです:
- 多対多関連クエリ:複数値インデックスを使用すると、エンティティ間の多対多関係のクエリを最適化できます。例えば、俳優と映画の関係では、映画のすべての俳優を JSON 配列で保存し、JSON 複数値インデックスを使用して特定の俳優が出演したすべての映画を迅速に検索できます。
- タグと分類のクエリ:エンティティが複数のタグや分類を持つ場合、複数値インデックスは関連するクエリを高速化できます。例えば、商品の複数のタグを JSON 配列に保存し、JSON 複数値インデックスを使用して特定のタグを含む商品を迅速に検索できます。
複数値インデックスの詳細な説明と使用方法については、複数値インデックス を参照してください。
複雑なデータ型
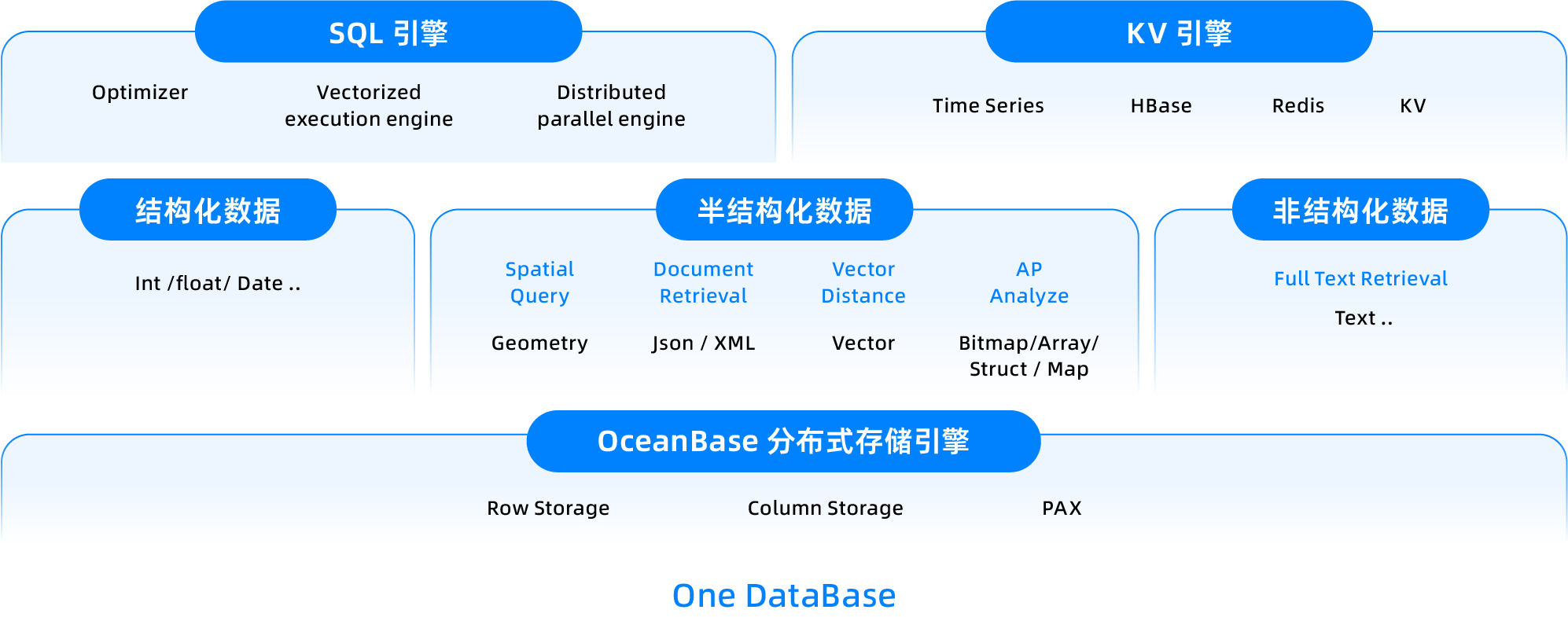
OceanBase データベースは、分散型のマルチモーダル統合データベースであり、リアルタイム分析シナリオにおいて、SQL エンジンを基盤として、単一のデータベース内で構造化データ、半構造化データ、非構造化データを同時に処理できます。
マルチモーダルストレージの基盤は LOB (Large Object) であり、同時に LOB は AI のストレージおよびデータ処理において重要な役割を果たします。AI シナリオにおけるマルチモーダルデータ(画像、テキスト、音声、動画)はすべて大規模なオブジェクトであり、LOB のパフォーマンスは AI プレトレーニングなどのシナリオにおける計算効率にとって非常に重要です。OceanBase はストレージ層で非常に効率的な LOB 実装を提供し、SQL では 512MB のストレージをサポートし、DBMS.Lob パッケージを使用することで、TB レベルの大規模オブジェクトの効率的な格納・取得を支えます。
データ分析シナリオにおいて、OceanBase は Array、Roaring Bitmap、Map などのマルチモーダルデータ型をネイティブでサポートしており、構造化データの効率的なストレージ・クエリだけでなく、半構造化データや複雑な集計分析も直接サポートします。
- Roaring Bitmap/Map:大規模なラベル分析、人口セグメンテーション、重複除去集計などの高度なデータマイニングシナリオに適しています。
- Array:ログ検索、行動軌跡、多次元ラベルなどの複雑な業務において、極めて高い柔軟性を提供し、真の「一つのデータベースで多様な機能を実現」を可能にします。
効率的に圧縮されたビットマップデータ型の詳細な説明と使用方法については、効率的に圧縮されたビットマップデータ型(RoaringBitmap)を参照してください。
配列型の詳細な説明と使用方法については、配列型を参照してください。
JSON は現在最も汎用性の高い半構造化データ型であり、取引、分析、さらには AI シナリオにおいても非常に広範囲に応用されています。
- 取引シナリオにおいて、スキーマレスな弾性列ストレージおよび計算として利用されます。
- 分析シナリオにおいて、JSON の複数値インデックスは多次元ラベルの柔軟な計算に適しています。
- AI シナリオにおいて、JSON はモデルとアプリケーションをつなぐ架け橋となり、同時にエージェント/ワークフローなどのデータ処理パイプラインにおいても、標準的な入出力形式として利用されます。
JSON が多様なワークロードで機能するために、OceanBase JSON は豊富な計算式や JSON ベースの複数値インデックスなどを実装しています。基盤となるストレージ形式では、JSON Binary をサポートし、JSON 内部データのランダム読み書きを最適化するだけでなく、JSON の構造化エンコードもサポートしています。類似した JSON から構造化情報を抽出し、JSON のストレージ圧縮率と JSON Path ベースのクエリ性能を深く最適化しています。JSON データ型の詳細な説明と使用方法については、JSON データ型を参照してください。
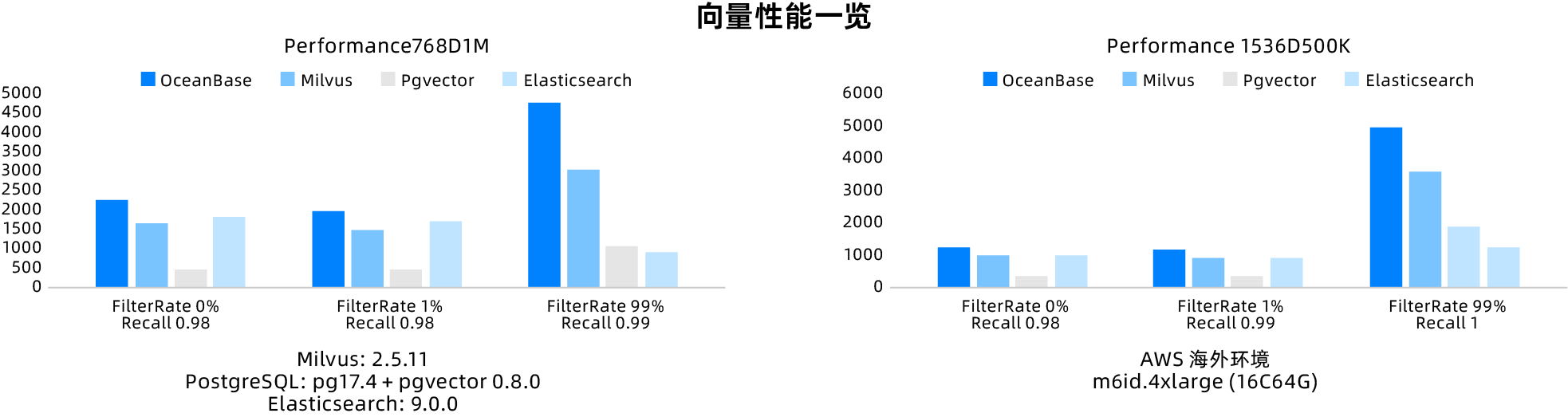
生成系 AI の時代において、マルチモーダルデータの処理はますます重要になっています。OceanBase はベクトル機能および全文検索機能を強化し、知識検索シナリオにおけるハイブリッド検索の要求をより良くサポートしています。ベクトルアルゴリズム + データベースの完全独自開発路線に基づき、OceanBase のベクトルはオープンソースのベクトルデータベースと比較して明確な優位性を持ち、VectorDBbench における性能は典型的なオープンソース競合製品を上回っています。
カラムストアレプリカ
HTAPハイブリッドワークロードシナリオにおいて、TPとAPのリソースを物理的に強力に分離する要件を満たすため、OceanBaseデータベースはカラムストアレプリカ(Column Store Replica、Cレプリカ)をサポートしています。カラムストアレプリカは新しいタイプのレプリカであり、読み取り専用機能を備えており、レプリカ上のすべてのユーザーテーブルのベースラインデータはカラムストア形式でのみ保存されます。カラムストアレプリカは独立したZoneにデプロイされ、OLAP業務は独立したODPエントリポイントを介してカラムストアレプリカにアクセスし、弱い読み取り(weak read)方式で実行されます。これにより、カラムストアのバッチ処理の利点を活用してクエリを高速化できる一方で、既存のOLTP業務に影響を与えません。2F1Aのデプロイメントモードでは、行列混合方式と比較して、2F1A1Cをデプロイすることで、TP/APの物理的強力分離の要件を実現するだけでなく、ストレージコストも削減できます。
カラムストアレプリカは、レプリカの分散戦略と弱い読み取りの解放メカニズムにおいて、通常の読み取り専用レプリカのルールを完全に遵守します。両者の主な違いは基礎データの格納構造にあります。通常の読み取り専用レプリカと同様に、カラムストアレプリカはプライマリノードの選出やログ同期の投票プロセスには参加しませんが、静的データテーブル、コミットログ、メモリデータテーブルなどのコアコンポーネントは完全に含まれています。
カラムストアレプリカの使用方法については、カラムストアレプリカを参照してください。
MySQLエコシステムとの互換性
極めたパフォーマンスと拡張性を追求する一方で、OceanBaseデータベースはMySQLエコシステムとの高い互換性を提供することにも力を入れています。これにより、既存のMySQL環境からOceanBaseデータベースへのシームレスな移行が可能となり、既存のOLAPエコツールや技術スタックを最大限活用して、データ分析とビジネスインサイトの迅速なイテレーションと革新を実現できます。
構文互換性:OceanBaseデータベースは、データ定義言語(DDL)、データ操作言語(DML)、データ制御言語(DCL)を含む、MySQLの標準SQL構文を全面的にサポートしています。つまり、以前MySQLで使用していたデータクエリ、テーブル構造定義、インデックス作成、権限管理などのステートメントは、ほぼそのままOceanBaseデータベースで実行でき、大幅な構文調整が不要であるため、移行コストと学習曲線を大幅に低減できます。
- シームレス移行: 既存のMySQLアプリケーションをOceanBaseデータベースに迅速に移行でき、移行プロセスでのコード修正作業量を削減します。
- スキルの再利用: MySQL開発者やDBAは新しいデータベース構文を追加で学ぶ必要がなく、適応期間を短縮できます。
- エコシステムの統合: MySQLエコシステムと互換性のある構文基盤により、OceanBaseデータベースは既存のBI、ETL、データ可視化などのツールチェーンによりスムーズに統合できます。
ビューの互換性:OceanBaseはMySQLのinformation_schemaビューと互換性があります。例えば:
- テーブル情報のクエリ: TABLESやCOLUMNSビューをサポートしており、ユーザーはデータベース内のすべてのテーブルの構造や列情報をクエリできます。これはデータディクショナリ管理やサードパーティツールとの連携に不可欠です。
- 権限管理: SCHEMATAやSCHEMA_PRIVILEGESなどのビューをサポートしており、管理者がデータベースやテーブルの権限設定を簡単に確認・管理できるようにします。
多くのデータベース管理、監視、分析ツールは、INFORMATION_SCHEMAに依存してデータベースの状態やアーキテクチャ情報を取得します。OceanBaseデータベースのこの互換性により、これらのツールはカスタマイズなしでOceanBaseデータベース上で直接実行できます。OceanBaseデータベースは、さまざまなOLAPエコツールをサポートしています。例えば:
OceanBaseは、バッチ処理からストリーミング処理までのフルスタックのデータ統合を実現しています:
- Flink、Kafka、OMS、OBLOADER、Dataworks、dbtなどの主要なツールとのシームレスな連携をサポートし、企業の既存のETL、リアルタイム同期、データウェアハウス環境への容易な接続を実現します。
- データベースカーネルは、ダイレクトロード、ファイル/ODPS/HDFS外部テーブル、External Catalogなどをサポートしており、マルチソースデータ統合やデータレイク連携の開発・運用のハードルを大幅に下げます。
- MySQL/Oracle構文との高い互換性により、Tableau、PowerBI、Flink、Quick BIなどの主要なBI、分析、ストリーム処理ツールをゼロコードで移行・接続でき、「箱から出してすぐ使える」状態を実現します。
OceanBaseは、コアエンジンだけでなく、多くのエコプロダクトにも対応しています:
- 自動化されたオーケストレーションとスケジューリング:DolphinScheduler、n8n、Airflowなどのスケジューリングプラットフォームと深く統合し、複数のデータ処理タスクの自動オーケストレーションと運用を実現し、大規模なデータガバナンスとシステム間の協働効率を向上させます。
- 可観測性:Prometheus、Grafanaなどの監視ツールとシームレスに統合し、マルチテナント、ノード、クラスタのリアルタイムパフォーマンス監視、アラート、インテリジェントな運用をサポートし、大規模なクラスタと複数のビジネスラインの安定した運用を容易にします。
- データ可視化の強化:Superset、Tableau、QuickBI、觀遠BIなどの主要なBIプラットフォームと完全に互換性があり、マルチロールのセルフサービス分析、インタラクティブなダッシュボード、複雑なビジネスレポートをサポートし、ビジネスインサイトとデータドリブンな意思決定を支援します。

現在のOceanBaseのOLAPエコシステム統合状況については、エコシステム統合を参照してください。