


OceanBase APとは
データベースのシナリオにおいて、トランザクション処理(TP) は高並行性と強整合性を求めるオンライン取引を対象とし、分析処理(AP) は大量データのリアルタイム分析と複雑なクエリを対象とします。これら二つが企業のデータ管理および分析ニーズを支えています。OceanBaseは長年にわたりTP分野で技術的リーダー性を維持しており、独自開発の分散アーキテクチャ、金融級の高可用性、そして極めて高い弾力性により、数多くのコア業務を支えてきました。企業レベルでのリアルタイム分析ニーズが急増する中、OceanBaseはV4.3バージョンから機能をTPからAPへと継続的に拡張し、ネイティブカラムストアと行・列統合ストアを導入し、実行層ではベクトル化エンジンを備えました。オプティマイザー側では、カラムストア向けにコストモデルと統計情報を補完し、行と列のアクセスパスをコストに基づいて自動選択できるようにしました。上記のストレージ、実行、最適化機能が相互に連携することで、同一のエンジンが取引負荷を担いながらも、リアルタイム分析を効率的にサポートし、企業に統合されたデータ管理とリアルタイム分析の価値を提供します。
 動画でOceanBase APのコア機能と顧客事例を学ぶ
動画でOceanBase APのコア機能と顧客事例を学ぶ 主な特徴
統合ストレージベース、行ストア/カラムストア/行列混合を同時サポート: ユーザーはテーブル作成時に行ストア、カラムストア、または行列混合を柔軟に指定でき、異なる業務タイプに対応します。カラムストアテーブルは、ストレージエンジン内でベースラインカラムストアと増分行ストアの方式を採用して実装され、ベースラインカラムストアが複雑なクエリのパフォーマンスを最適化し、増分行ストアは依然として高並行性のデータ書き込みをサポートします。
リアルタイム分析における強力なトランザクションと高並行性の保証: 分散ACIDとマルチレプリカの強整合性アーキテクチャを継承し、分析系シナリオでもデータの強整合性要件を満たせます。スムーズなスケーリングとノード間の動的ロードバランシングをサポートし、システム性能はリソース拡張に応じて線形に拡張します。多次元的なリソース分離機能をサポートします:マルチテナント間のリソース分離;テナント内ではリソースグループを通じてユーザーレベル、SQLレベル、フロントエンド/バックエンドタスクレベルのリソース分離を実現可能;読み取り専用カラムストアレプリカのデプロイメント形態では、TPとAPトラフィックを異なるレプリカに分流し、ノードレベルでの物理的強分離を実現します。
ベクトル化実行エンジン、大規模データ分析の高速化: ベクトル化実行はバッチ処理でデータを処理し、効率的な列指向データ記述形式を採用するとともに、その上で演算子と式のバッチ反復実装を最適化します。ストレージ層はこの形式に対応し、SIMDなどの手法を用いて投影、述語、集計などのダウンプッシュパスを高速化し、負荷に応じてバッチサイズを自動調整することをサポートします。従来の行単位処理のヴォルカノモデルと比較して、分析系クエリのパフォーマンスは約1桁向上します。
エンタープライズ向けクエリオプティマイザー、リアルタイム分析性能の向上: オプティマイザーはHTAPとリアルタイム分析向けに設計されています:より大きな計画空間でクエリのリライトと戦略選択を行います;一段階分散計画生成を採用し、接続順序とアルゴリズムの列挙時にデータ分布と並列度を同時に考慮することで、単一マシン最適・分散環境での非最適という問題を回避します;アクセス特性に基づき、行ストアパスとカラムストアパスの間で自動的に選択を行い、カラムストアスキャンに対してコストモデルと統計情報を構築し、SkipIndexなどのメカニズムがもたらすスキャンの利益を評価します。スキャンコストが高いクエリについては、**自動並列(AUTO DOP)**を有効にして応答時間を短縮できます;**SQL計画管理(SPM)**を通じて、データ量、統計情報、またはバージョン変更時の計画進化を管理し、実際のトラフィックを用いたグレースケール検証により計画の逆戻りを抑制し、長期的な安定稼働を保証します。
インテリジェントマテリアライズドビュー、多層の事前計算と高頻度のリアルタイム更新: ユーザーは宣言型SQLで事前計算結果を定義し、OceanBaseが自動的に更新メカニズムとテーブル間依存関係を管理します。複雑なETLやデータパイプラインは不要です。一方で、リアルタイムマテリアライズドビューをサポートし、目標の新鮮度(例:30秒、5分)に応じて更新をスケジュールできます;自動増分ビュー維持により、前回の更新以降の変更のみに対して増分計算を行い、更新コストを削減しつつ新鮮度を保証します。他方、クエリオプティマイザーが利用可能なマテリアライズドビューを検出すると、ベーステーブルへのクエリを自動的にマテリアライズドビューへの読み取りにリライトします。業務側はSQLを変更することなく複雑なクエリを高速化できます。
マルチモーダルデータ型、AI融合分析を支援: Array、Roaring Bitmap、Map、JSON、Vectorなどの複雑なデータ型をネイティブサポートし、JSON複数値インデックス、ベクトルインデックス、全文インデックスなどの機能を提供することで、スキャン範囲を狭め、検索を高速化します。これにより、ラベル分析やターゲットオーディエンスの選別などの典型的な分析シナリオをサポートするだけでなく、多様なデータ型の統一ストレージとハイブリッド検索機能を活用して、知識検索やセマンティック検索などのAI関連のニーズにも対応できます。
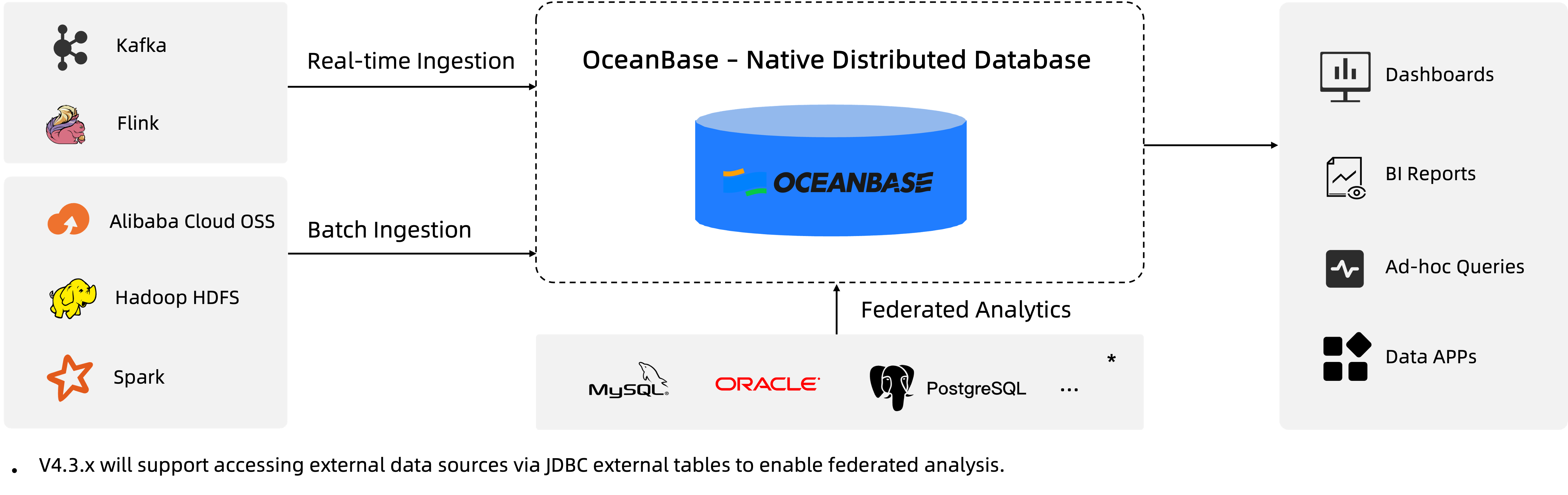
オープンエコシステムとのシームレス連携、ビジネスイノベーションを促進: OceanBaseは多様な外部システムからデータを取得でき、上流・下流ツールと連携します。KafkaやFlinkなどのストリーミングシステムとの連携をサポートし、リアルタイムデータの取得と処理を実現します;OMSなどのツールを利用して既存のデータベースやデータウェアハウスへの移行と同期をサポートします;外部テーブルを通じて多様なファイルおよびオブジェクトストレージ形式にアクセスでき、Hive MetastoreやIcebergなどのカタログをサポートし、統一メタデータアクセスを実現します。SQL層はMySQL/Oracleと高い互換性を持ち、BI、ETL、各種分析ツールの連携を容易にします。DolphinSchedulerやAirflowなどのスケジューリングシステムとの連携をサポートするほか、PrometheusやGrafana、Tableau、QuickBIなどの監視・可視化・分析ツールとの連携もサポートし、データパイプラインのガバナンスとビジネスインサイトを支援します。
適用シナリオ
シナリオ1:HTAP混合ワークロードシナリオ
- 一体化されたシンプルなアーキテクチャ:同一のエンジンと同一のデータセットで、トランザクションと分析のワークロードを同時にサポートします。また、ビジネスニーズに応じて、行ストアとカラムストアのハイブリッド構成や、カラムストアのみのレプリケーション構成を選択できます。
- 低コストでの大量ストレージ:LSM-Treeと高度な圧縮技術により、従来のソリューションと比較してストレージコストを70%~90%削減できます。
- 高並行計算のサポート:OceanBaseの対等アーキテクチャは、生まれながらにしてマルチマシン並列計算をサポートしており、最大でPBレベルの容量をサポートします。これにより、ビジネスの全域データに対して安定したストレージ基盤を容易に提供できます。
- 複数シナリオの分離:基盤となるリソース分離技術およびユーザーリソースグループ技術により、複数シナリオや複数ユーザーにおけるタスクのリソース分離を実現します。

シナリオ2:リアルタイムデータ分析シナリオ
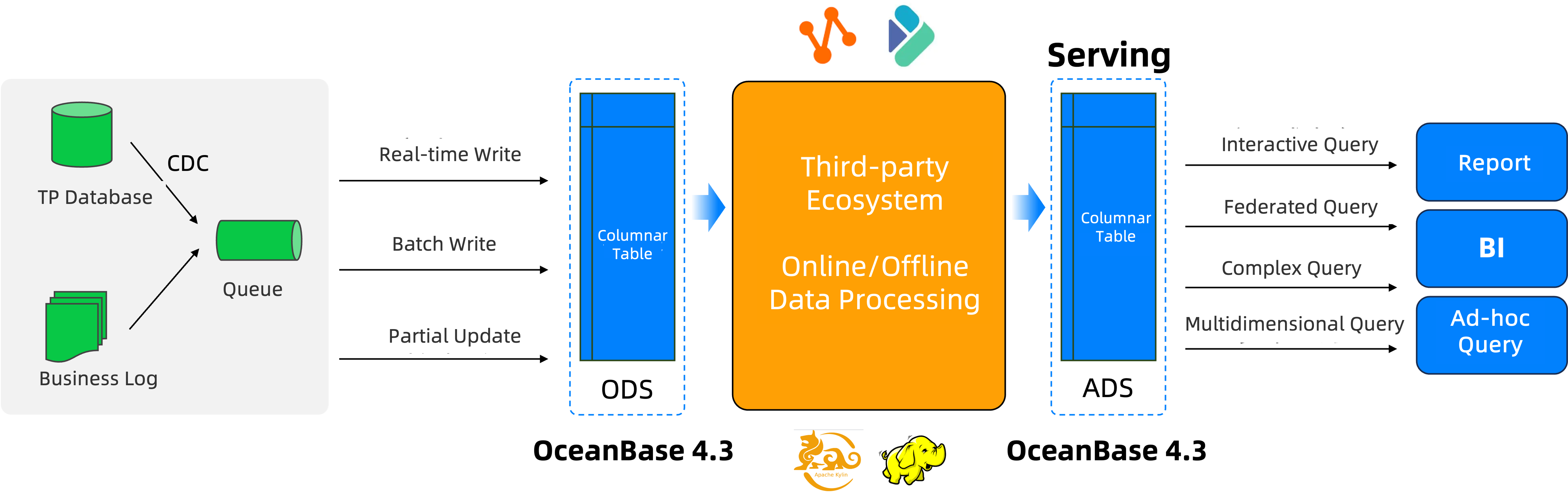
- リアルタイムデータ更新:LSM-Treeアーキテクチャに基づき、効率的なリアルタイム書き込みをサポートします。増分データは行ストア、ベースラインデータはカラムストアとして格納し、定期的または適応的にメジャーコンパクションを実行して新しいカラムストアのベースラインを生成します。データは書き込まれ次第外部へのクエリ提供が可能となり、データのリアルタイム性を保証します。
- 高精度と強整合性:Multi-Paxosプロトコルを用いて複数レプリカ間のデータ整合性を実現します。MVCCモデルを採用し、ノンブロッキングな読み書きをサポートするとともに、読み取りデータのトランザクション整合性を保証します。プライマリレプリカに基づく強力な読み取りと、他のレプリカに対する弱い読み取りをサポートします。また、WALメカニズムに基づき、データの永続性と原子性を保証します。
- 高性能計算:カラムストア技術、計算の下押し、圧縮データに基づくクエリ処理により、高性能なデータクエリを実現します。オプティマイザーのクエリ再構成機能、ルール/コストに基づく実行計画の選択能力、並列実行エンジンやベクトル化エンジンによる実行最適化を活用し、高い計算性能を得ます。マテリアライズドビュー機能を提供し、さらに大量データのクエリ分析を支援します。
- 高可用性:TP形態の高可用性を継承し、RPO=0、RTO<8秒です。単一データセンターから三地域五中心への柔軟なデプロイメントをサポートし、システムの自動ディザスタリカバリをサポートします。クラウドデータベースは、共有ストレージと独立したログサービスに基づく単一レプリカ形態もサポートしており、コストを削減しつつシステムの高可用性を最大限に保証します。
- スムーズなスケーリング:サービスを中断することなく、水平方向および垂直方向へのスムーズなスケーリングが可能です。水平方向のスケーリングでは、組み込みのデータ動的均等化メカニズムにより、データとサービスの負荷がノード間で均等に分散されます。
- マルチモーダル統合:Btreeインデックス、JSON複数値インデックス、全文インデックス、ベクトルインデックスなど、マルチモーダルな型を全面的にサポートし、技術を統合します。
- ストレージと計算の分離:複数の計算ノードが同一のストレージデータにアクセスすることをサポートし、ローカル永続化キャッシュとオブジェクトストレージを組み合わせることで、高コストパフォーマンスのストレージと計算の分離アーキテクチャを実現します。


シナリオ3:PL/SQLバッチ処理シナリオ
- 性能の極限的向上による処理ボトルネックの解消。OceanBaseのカラムストアエンジンは分析シナリオ専用に設計されており、データを列単位で格納することで、圧縮率が高く、I/Oが大幅に削減されます。ベクトル化実行エンジンと組み合わせることで、CPUは一度にメモリ内の一括データ(一行ではなく)に対して計算を行うことができ、CPUキャッシュヒット率と計算効率を大幅に向上させます。典型的なバッチ処理タスクでは、10倍以上の性能向上を実現し、ビジネスのバッチ処理ウィンドウを容易に満たすか短縮することができ、準リアルタイム分析を可能にします。
- 感じさせないスムーズな移行によるビジネスリスクの最小化。OceanBaseはOracleとの高い互換性を備えており、一般的なSQL構文やデータ型だけでなく、PL/SQLストアドプロシージャとの高い互換性も備えています。これにより、顧客はOracleに蓄積された多くのビジネスロジックを持つストアドプロシージャを、ほとんど修正を加えることなくOceanBaseに移行できます。アプリケーション層のコードは一切変更不要であり、移行のリスク、コスト、期間を大幅に削減し、「不可能」とされたシステムの近代化改革を可能にします。
- 一体化アーキテクチャによるコスト削減と効率向上。従来の「OLTPデータベース + データウェアハウス/ビッグデータプラットフォーム」の分離アーキテクチャでは、2つのシステムをメンテナンスする必要があり、データは複雑なETL/CDCを経由して同期する必要があるため、アーキテクチャが複雑でコストが高額です。OceanBaseの一体化アーキテクチャは、1つのシステムでオンライントランザクションとバッチ処理分析を同時に担います。組み込みのリソース分離メカニズムにより、分析タスクがカラムストア上で実行される際に、行ストア上のトランザクションタスクと激しいリソース競合が発生するのを防ぎます。これにより、技術スタックが簡略化され、運用保守の複雑さが低減するだけでなく、データの冗長ストレージやシステム間の同期にかかるオーバーヘッドも回避され、企業の総所有コスト(TCO)を大幅に削減します。
技術アーキテクチャ
- OceanBaseデータベースの技術アーキテクチャについては、OceanBaseシステムアーキテクチャを参照してください。
- OceanBaseデータベースの技術原理の詳細については、OceanBaseシステム原理の章を参照してください。