


本記事では、OceanBaseデータベースのパス選択ルール体系について説明します。
現在、OceanBaseデータベースのパス選択ルール体系は、前置きルール(順方向ルール)とSkyline剪枝ルール(逆方向ルール)に分かれています。前置きルールはクエリがどのインデックスを使用するかを直接決定し、強いマッチングを持つルール体系です。
Skyline剪枝ルールは2つのインデックスを比較し、一方のインデックスが定義された次元でもう一方のインデックスより優れている場合(Dominates)、劣るインデックスは除外されます。最終的に除外されなかったインデックスの中からコスト比較を行い、最適な実行計画を選択します。
現在、OceanBaseデータベースのオプティマイザーは、まず前置きルールを優先してインデックスを選択します。一致するインデックスがない場合、Skyline剪枝ルールが一部の劣るインデックスを除外し、最後にコストモデルが除外されなかったインデックスの中からコストが最も低いパスを選択します。
以下の例のように、OceanBaseデータベースの実行計画表示では、対応するパス選択のルール情報が出力されます。
テーブル
t1を作成します。obclient> CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, d INT, e INT, UNIQUE INDEX k1(b), INDEX k2(b,c), INDEX k3(c,d) );実行計画を確認します。クエリ条件は
b = 1です。obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE b = 1;結果は次のとおりです:
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Query Plan | +--------------------------------------------------------------------------------------------------------------------------------------------------------------+ | =========================================== | | |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| | | ------------------------------------------- | | |0 |TABLE GET|t1(k1)|1 |10 | | | =========================================== | | Outputs & filters: | | ------------------------------------- | | 0 - output([t1.a(0x7f35a049b280)], [t1.b(0x7f35a049b000)], [t1.c(0x7f35a049b410)], [t1.d(0x7f35a049b5a0)], [t1.e(0x7f35a049b730)]), filter(nil), rowset=16 | | access([t1.a(0x7f35a049b280)], [t1.b(0x7f35a049b000)], [t1.c(0x7f35a049b410)], [t1.d(0x7f35a049b5a0)], [t1.e(0x7f35a049b730)]), partitions(p0) | | is_index_back=true, is_global_index=false, | | range_key([t1.b(0x7f35a049b000)], [t1.shadow_pk_0(0x7f35a04c25e0)]), range[1,NULL ; 1,NULL], | | range_cond([t1.b(0x7f35a049b000) = 1(0x7f35a049ad60)(0x7f35a049aeb0)]) | | Used Hint: | | ------------------------------------- | | /*+ | | | | */ | | Qb name trace: | | ------------------------------------- | | stmt_id:0, stmt_type:T_EXPLAIN | | stmt_id:1, SEL$1 | | Outline Data: | | ------------------------------------- | | /*+ | | BEGIN_OUTLINE_DATA | | INDEX(@"SEL$1" "test_db"."t1"@"SEL$1" "k1") | | OPTIMIZER_FEATURES_ENABLE('4.4.2.0') | | END_OUTLINE_DATA | | */ | | Optimization Info: | | ------------------------------------- | | t1: | | table_rows:1 | | physical_range_rows:1 | | logical_range_rows:1 | | index_back_rows:1 | | output_rows:1 | | table_dop:1 | | dop_method:Table DOP | | avaiable_index_name:[k1, k2, k3, t1] | | pruned_index_name:[k2, k3, t1] | | stats info:[version=1970-01-01 08:00:00.000000, is_locked=0, is_expired=0] | | dynamic sampling level:0 | | estimation method:[DEFAULT] | | Plan Type: | | LOCAL | | Parameters: | | :0 => 1 | | Note: | | Degree of Parallelisim is 1 because of table property | +--------------------------------------------------------------------------------------------------------------------------------------------------------------+ 50 rows in set実行計画を確認します。クエリ条件は
c < 5、ソートはORDER BY cです。obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE c < 5 ORDER BY c;結果は次のとおりです:
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+ | Query Plan | +--------------------------------------------------------------------------------------------------------------------------------------------------------------+ | ================================================== | | |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| | | -------------------------------------------------- | | |0 |TABLE RANGE SCAN|t1(k3)|1 |5 | | | ================================================== | | Outputs & filters: | | ------------------------------------- | | 0 - output([t1.a(0x7f35a239d650)], [t1.b(0x7f35a239d7e0)], [t1.c(0x7f35a239d3d0)], [t1.d(0x7f35a239d970)], [t1.e(0x7f35a239db00)]), filter(nil), rowset=16 | | access([t1.a(0x7f35a239d650)], [t1.c(0x7f35a239d3d0)], [t1.b(0x7f35a239d7e0)], [t1.d(0x7f35a239d970)], [t1.e(0x7f35a239db00)]), partitions(p0) | | is_index_back=true, is_global_index=false, | | range_key([t1.c(0x7f35a239d3d0)], [t1.d(0x7f35a239d970)], [t1.a(0x7f35a239d650)]), range(NULL,MAX,MAX ; 5,MIN,MIN), | | range_cond([t1.c(0x7f35a239d3d0) < 5(0x7f35a239d130)(0x7f35a239d280)]) | | Used Hint: | | ------------------------------------- | | /*+ | | | | */ | | Qb name trace: | | ------------------------------------- | | stmt_id:0, stmt_type:T_EXPLAIN | | stmt_id:1, SEL$1 | | Outline Data: | | ------------------------------------- | | /*+ | | BEGIN_OUTLINE_DATA | | INDEX(@"SEL$1" "test_db"."t1"@"SEL$1" "k3") | | OPTIMIZER_FEATURES_ENABLE('4.4.2.0') | | END_OUTLINE_DATA | | */ | | Optimization Info: | | ------------------------------------- | | t1: | | table_rows:1 | | physical_range_rows:1 | | logical_range_rows:1 | | index_back_rows:1 | | output_rows:1 | | table_dop:1 | | dop_method:Table DOP | | avaiable_index_name:[k1, k2, k3, t1] | | pruned_index_name:[k1, k2] | | unstable_index_name:[t1] | | stats info:[version=1970-01-01 08:00:00.000000, is_locked=0, is_expired=0] | | dynamic sampling level:0 | | estimation method:[DEFAULT, STORAGE] | | Plan Type: | | LOCAL | | Parameters: | | :0 => 5 | | Note: | | Degree of Parallelisim is 1 because of table property | +--------------------------------------------------------------------------------------------------------------------------------------------------------------+ 51 rows in set
前提条件
現在、OceanBaseデータベースの前提条件は、単純な単一テーブルスキャンにのみ使用されます。前提条件は強力なマッチングルールであり、マッチした場合はそのインデックスを直接選択するため、誤った実行計画が選択されるのを避けるために、その使用シナリオを制限する必要があります。
現在、OceanBaseデータベースは、「クエリ条件がすべてのインデックスキーをカバーできるかどうか」と「そのインデックスを使用するために再テーブルアクセスが必要かどうか」という2つの情報に基づいて、前提条件を優先順位に応じて以下の3種類のマッチングタイプに分類しています:
「一意性インデックス完全一致 + 再テーブルアクセス不要(主キーは一意性インデックスとして処理される)」にマッチする場合、そのインデックスを選択します。複数のこのようなインデックスが存在する場合、インデックス列数が最も少ないものを選択します。
「通常インデックス完全一致 + 再テーブルアクセス不要」にマッチする場合、そのインデックスを選択します。複数のこのようなインデックスが存在する場合、インデックス列数が最も少ないものを選択します。
「一意性インデックス完全一致 + 再テーブルアクセスあり + 再テーブルアクセス数が一定のしきい値未満」にマッチする場合、そのインデックスを選択します。複数のこのマッチングタイプのインデックスが存在する場合、再テーブルアクセス数が最も少ないものを選択します。
ここで注意が必要なのは、インデックスの完全一致とは、インデックスキーすべてに等しい条件(getまたはmulti-getに対応)が存在することを指します。
以下の例では、クエリQ1はインデックスuk1(一意性インデックス完全一致 + 再テーブルアクセス不要)にマッチし、クエリQ2はインデックスuk2(一意性インデックス完全一致 + 再テーブルアクセスあり + 再テーブル行数が最大4行)にマッチします。
テーブル
testを作成します。obclient> CREATE TABLE test(a INT PRIMARY KEY, b INT, c INT, d INT, e INT, UNIQUE KEY UK1(b,c), UNIQUE KEY UK2(c,d) );クエリの例です。
Q1:
obclient> SELECT b,c FROM test WHERE (b = 1 OR b = 2) AND (c = 1 OR c =2);Q2:
obclient> SELECT * FROM test WHERE (c = 1 OR c =2) AND (d = 1 OR d = 2);
Skyline剪枝ルール
Skyline演算子は、2001年に学術界で提案された新しいデータベース演算子です(標準のSQL演算子ではありません)。それ以来、学術界ではSkyline演算子に関する多くの研究が行われています(構文、意味論、実行などを含む)。
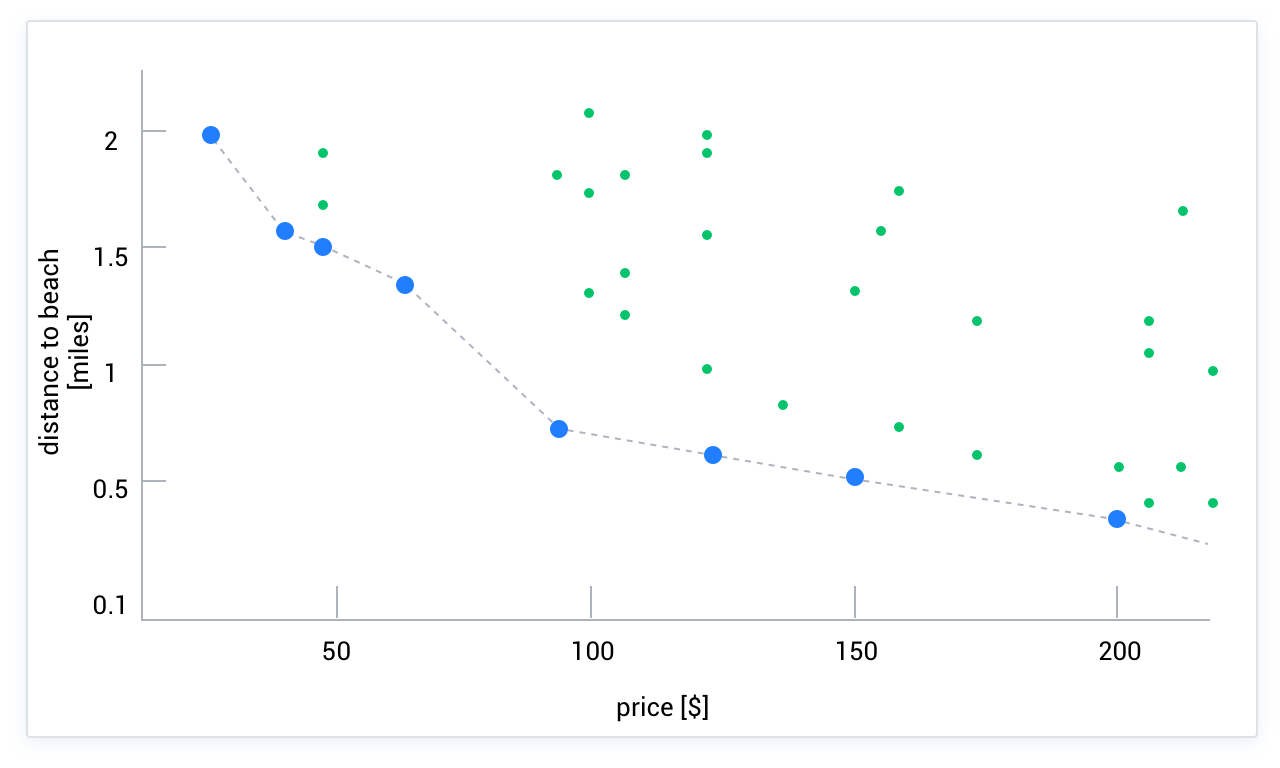
Skylineという言葉は文字通り、空の中のいくつかの境界点を指します。これらの点が探索空間における最適解の集合を形成します。例えば、価格が最も安く、距離が最も短いホテルを探す場合、二次元空間を想像することができます。横軸は価格、縦軸は距離を表し、二次元空間上の各点が一つのホテルを表します。下図のように、最適解は必ずこの空の境界線上にあります。点AがSkyline上にないと仮定すると、Skyline上にはAよりも二つの次元で優れた点Bが必ず存在します。このシナリオでは、それは距離が近く、価格が安いホテルであり、点Bが点Aを支配する(point B Dominate A)と呼ばれます。したがって、ユーザーが複数の次元の重みを測定できない場合、または複数の次元を総合的に定量化できない場合(総合的に定量化できる場合は、「SQL関数+ ORDER BY」を使用すれば解決できます)、Skylineアルゴリズムを使用できます。
Skylineの原理は、与えられたオブジェクト集合Oから、他のオブジェクトに支配されていないオブジェクトの集合を見つけることです。あるオブジェクトAがすべての次元で別のオブジェクトBに支配されておらず、かつAが少なくとも一つの次元でBを支配する場合、AはBを支配すると言います。したがって、Skylineでは次元の選択と、各次元における支配関係の定義が重要です。N個のインデックスのパス<idx_1,idx_2,idx_3...idx_n>がオプティマイザーの選択肢としてある場合、クエリQに対してインデックスidx_xが定義された次元でインデックスidx_yを支配するならば、インデックスidx_yを事前に削除し、最終的なコスト計算に参加させないことができます。
次元の定義
Skylineプルーニングルールは、各インデックス(主キーもインデックスの一種です)に対して以下の3つの次元を定義します:
テーブルへの再アクセスが必要かどうか
興味深い順序(Interesting Order)が存在するかどうか
インデックスのプレフィックスからクエリ範囲を抽出できるかどうか
以下の例を用いて説明します:
obclient> CREATE TABLE skyline(pk INT PRIMARY KEY,
a INT,
b INT,
c INT,
KEY idx_a_b(a, b),
KEY idx_b_c(b, c),
KEY idx_c_a(c, a)
);
テーブルへの再アクセス:このクエリで主テーブルに再アクセスする必要があるかどうかを示します。
/* インデックス idx_a_b を使用する場合、主テーブルに再アクセスする必要があります。インデックス idx_a_b には列 c がないため*/ obclient>SELECT /*+INDEX(skyline idx_a_b)*/ * FROM skyline;興味深い順序:適切な順序を利用できるかどうかを考慮します。
/* インデックス idx_b_c はORDER BYステートメントを省略できます*/ obclient>SELECT pk, b FROM skyline ORDER BY b;インデックスのプレフィックスからクエリ範囲を抽出できるかどうか。
/* インデックス idx_c_a を使用すると、必要な行の範囲を迅速に特定でき、全表スキャンを回避できます*/ obclient>SELECT pk, b FROM skyline WHERE c > 100 AND c < 2000;
これら3つの次元に基づき、Skylineはインデックス間の支配関係(Dominate relationship)を定義しています。インデックスAが3つの次元すべてでインデックスBより劣っておらず、少なくとも1つの次元でBより優れている場合、インデックスBに基づいて最終的に生成される実行計画はインデックスAより優れている可能性がないと推測できます。そのため、インデックスBを直接削除できます。判断基準は以下の通りです:
インデックス
idx_Aでテーブルへの再アクセスが不要であり、インデックスidx_Bで再アクセスが必要な場合、この次元ではインデックスidx_Aがidx_Bを支配します。インデックス
idx_Aから抽出される興味深い順序がベクトルVa<a1, a2, a3 ...an>であり、インデックスidx_Bから抽出される興味深い順序がベクトルVb<b1, b2, b3...bm>で、かつn > mである場合、ai = bi (i=1..m)に対して、この次元ではインデックスidx_Aがidx_Bを支配します。インデックス idx_A でクエリ範囲を抽出できる列の集合が
Sa<a1, a2, a3 ...an>であり、インデックスidx_Bでクエリ範囲を抽出できる列の集合がSb <b1, b2, b3...bm>である場合、SaがSbの超集合(Super Set)であれば、この次元ではインデックスidx_Aがidx_Bを支配します。
リトリーブ
リトリーブとは、クエリに必要な列がインデックスに含まれているかどうかを確認することです。主表とインデックス表の両方にInteresting Orderがなく、Query Rangeも抽出できないような特定のシナリオでは、直接主表を参照するのが最適解とは限りません。
obclient> CREATE TABLE t1(pk INT PRIMARY KEY,
a INT,
b INT,
c INT,
v1 VARCHAR(1000),
v2 VARCHAR(1000),
v3 VARCHAR(1000),
v4 VARCHAR(1000),
INDEX idx_a_b(a, b)
);
obclient>SELECT a, b,c FROM t1 WHERE b = 100;
インデックス |
Index Back |
Interesting Order |
Query Range |
|---|---|---|---|
| primary | no | no | no |
| idx_a_b | yes | no | no |
主表は非常に幅広く、インデックス表は非常に狭いため、次元から分析すると主表がインデックスidx_a_bを支配します。しかし、インデックススキャンに続くリトリーブが必ずしも主表の全表スキャンよりもコストが高いわけではありません。簡単に言えば、インデックス表は1つのマクロブロックしか読み取らなくて済む場合がありますが、主表は10個のマクロブロックを必要とするかもしれません。このような場合は、ルールを緩和し、具体的なフィルタ条件を総合的に考慮する必要があります。
Interesting Order
オプティマイザーはInteresting Orderを利用して基盤となる順序を活用することで、基盤レベルでスキャンされた行をソートする必要がなくなり、ORDER BYを省略したり、MERGE GROUP BYを実行したり、パイプラインを向上させたり(マテリアライズが不要な場合)することができます。
obclient> CREATE TABLE skyline(pk INT PRIMARY KEY,
v1 INT,
v2 INT,
v3 INT,
v4 INT,
v5 INT,
KEY idx_v1_v3_v5(v1, v3, v5),
KEY idx_v3_v4(v3, v4)
);
obclient> CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
obclient> (SELECT DISTINCT v1, v3 FROM skyline JOIN tmp
WHERE skyline.v1 = tmp.c1
ORDER BY v1, v3)
UNION (SELECT c1, c2 FROM tmp);

実行計画を見ると、ORDER BYが省略されており、MERGE DISTINCTが使用されていることがわかります。また、UNIONでもSORTが行われていません。これは、基盤レベルのTABLE SCANで得られた順序が、上位の演算子で利用できることを示しています。言い換えれば、idx_v1_v3_v5が出力する行の順序を保持することで、後続の演算子が順序を保ちながらより優れた操作を実行できます。オプティマイザーは、これらの順序を認識できた場合にのみ、より優れた実行計画を生成できます。
したがって、Skyline剪枝におけるInteresting Orderの判断では、各インデックスが最大限に活用できる順序を十分に考慮する必要があります。例えば、前述の例で最大の順序は実際には(v1, v3)であり、単にv1だけではありません。MERGE JOINで得られた順序(v1, v3)は、MERGE DISTINCT演算子を経て、最終的にUNION DISTINCT演算子に至ります。
クエリ範囲の指定
クエリ範囲を指定することで、ストレージ層のI/Oが削減されます。これは、抽出された範囲に基づいて基盤となるシステムが直接特定のマクロブロックを特定しやすくなるためです。
例えば、SELECT * FROM t1 WHERE pk < 100 AND pk > 0 のようなクエリは、一次インデックスの情報に基づいて直接特定のマクロブロックを特定でき、クエリを高速化します。クエリ範囲が正確であればあるほど、データベースがスキャンする行数を少なく抑えることができます。
obclient> CREATE TABLE t1 (pk INT PRIMARY KEY,
a INT,
b INT,
c INT,
KEY idx_b_c(b, c),
KEY idx_a_b(a, b)
);
obclient> SELECT b FROM t1 WHERE a = 100 AND b > 2000;
インデックス idx_b_c から抽出できるクエリ範囲のインデックスプレフィックスは (b) であり、インデックス idx_a_b から抽出できるクエリ範囲のインデックスプレフィックスは (a, b) です。したがって、この観点から見ると、インデックス idx_a_b は idx_b_c よりも優れています。
総合例
obclient> CREATE TABLE skyline(pk INT PRIMARY KEY,
v1 INT,
v2 INT,
v3 INT,
v4 INT,
v5 INT,
KEY idx_v1_v3_v5(v1, v3, v5),
KEY idx_v3_v4(v3, v4)
);
obclient> CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
obclient> SELECT MAX(v5) FROM skyline WHERE v1 = 100 AND v3 > 200 GROUP BY v1;
インデックス |
Index Back |
Interesting order |
Query range |
|---|---|---|---|
| primary | Not need | No | No |
| idx_v1_v3_v5 | Not need | (v1) | (v1, v3) |
| idx_v3_v4 | Need | No | (v3) |
インデックス idx_v1_v3_v5 は、3つの次元すべてにおいて主キーインデックスやインデックス idx_v3_v4 より劣っていないことがわかります。そのため、Skylineプルーニングのルールにより、主キーインデックスとインデックス idx_v3_v4 は直接削除されます。次元の適切な定義は、Skylineプルーニングが適切に行われるかどうかを決定します。誤った次元設定では、そのインデックスが早期に削除され、最適な実行計画が生成されない可能性があります。