


ヒストグラムは、データを一連の順序付けられたバケットに格納することで、列のデータ分布特性を記述する特殊な種類の列統計情報です。オプティマイザーはヒストグラムに基づいて、より正確な行数を推定することができます。
デフォルトでは、オプティマイザーは列のデータが均等に分布していると仮定し、その特性に基づいて行数を推定します。しかし、実際のシナリオでは、ほとんどのテーブルのデータ分布は均一ではありません。このような場合には、ヒストグラムを使用する必要があります。
OceanBaseデータベースのオプティマイザーでは、列のヒストグラム情報はビュー ALL_TAB_HISTOGRAMS、DBA_TAB_HISTOGRAMS、および USER_TAB_HISTOGRAMS に格納され、以下の情報を含みます:
機能の適用範囲
現在、OceanBaseデータベースCommunity Editionは ALL_TAB_HISTOGRAMS および USER_TAB_HISTOGRAMS ビューをサポートしていません。
ヒストグラムの基本情報(
tenant_id、table_id、partition_id、column_idを含む)ヒストグラムの統計情報タイプ(情報レベルは
GLOBAL、PARTITION、SUBPARTITIONに分類されます)ヒストグラム内の各バケットに累積されたデータ量(現在のバケットとそれ以前のバケットの合計を含む)
ヒストグラム内の各バケットにおける最大値
ヒストグラム内の各バケットにおける最大値の頻度
ヒストグラムの種類
OceanBaseデータベースのオプティマイザーは、頻度ヒストグラム、Topkヒストグラム、および混合ヒストグラムの3種類のヒストグラムをサポートしています。
頻度ヒストグラムでは、各異なる列値がヒストグラムの個々のバケットに対応し、指定されたバケット数は列のNDV値以上である必要があります。
Topkヒストグラムは頻度ヒストグラムの変種であり、Lossy Countingアルゴリズムに基づいて、一部のデータ特徴を取得することで全体のデータ分布を推定します。記録されるデータ数と総データ数の比率は 1-(1/bucket_size) 以上である必要があります。
混合ヒストグラムは、指定されたデータ量を収集してヒストグラムを構築するもので、頻度ヒストグラムとTopkヒストグラムの機能を補完します。
頻度ヒストグラム
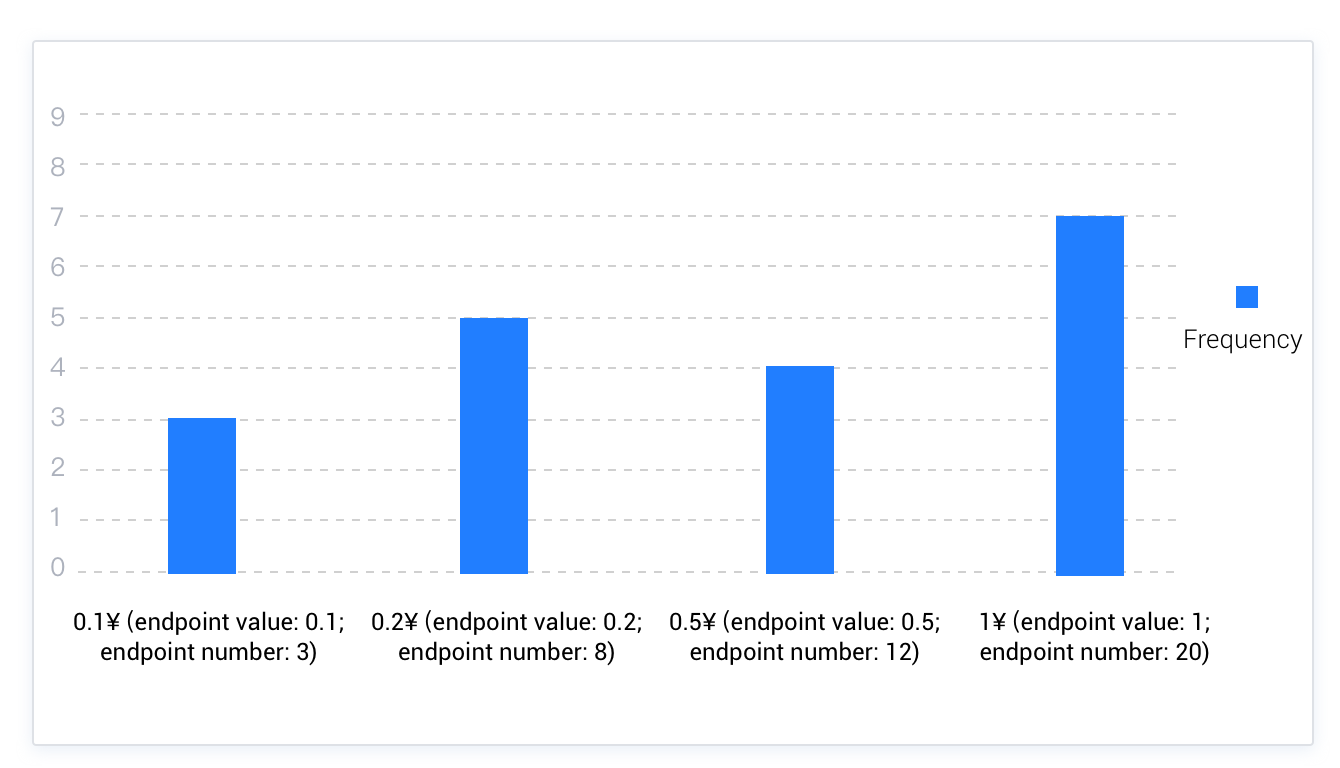
頻度ヒストグラムでは、各異なる列値がヒストグラムの個々のバケットに対応します。各値には専用のバケットが割り当てられているため、一部のバケットには多くの値が含まれ、他のバケットには少ない値しか含まれない場合があります。頻度ヒストグラムの類推としては、硬貨を分類することが挙げられます。例えば、ある財布に0.1元、0.2元、0.5元、1元の4種類の異なる額面の硬貨が合計20枚入っているとします。分類に従って、すべての0.1元硬貨を最初のバケットに、すべての0.2元硬貨を2番目のバケットに、すべての0.5元硬貨を3番目のバケットに、すべての1元硬貨を4番目のバケットに入れると、以下のような頻度ヒストグラムが得られます。頻度ヒストグラムの特性から、指定されたバケット数は列のNDV値以上である必要があります。
Topkヒストグラム
Topkヒストグラムは頻度ヒストグラムの変種であり、指定したバケット数がすべてのNDVを収容するには不十分な場合に選択されます。Topkヒストグラムは本質的に頻度が低いデータを無視し、主に頻度が高いデータの分布を考慮します。例えば、前述のシナリオで、財布に0.1元、0.2元、0.5元、1元の4種類の異なる額面の硬貨が合計100枚入っているとします。そのうち0.1元硬貨はわずか1枚しかありません。また、硬貨を収容するためのバケットは3つしかありません。この場合、0.1元硬貨を無視し、残りの3種類の硬貨の分布のみを考慮することができ、以下のようなTopkヒストグラムが得られます。
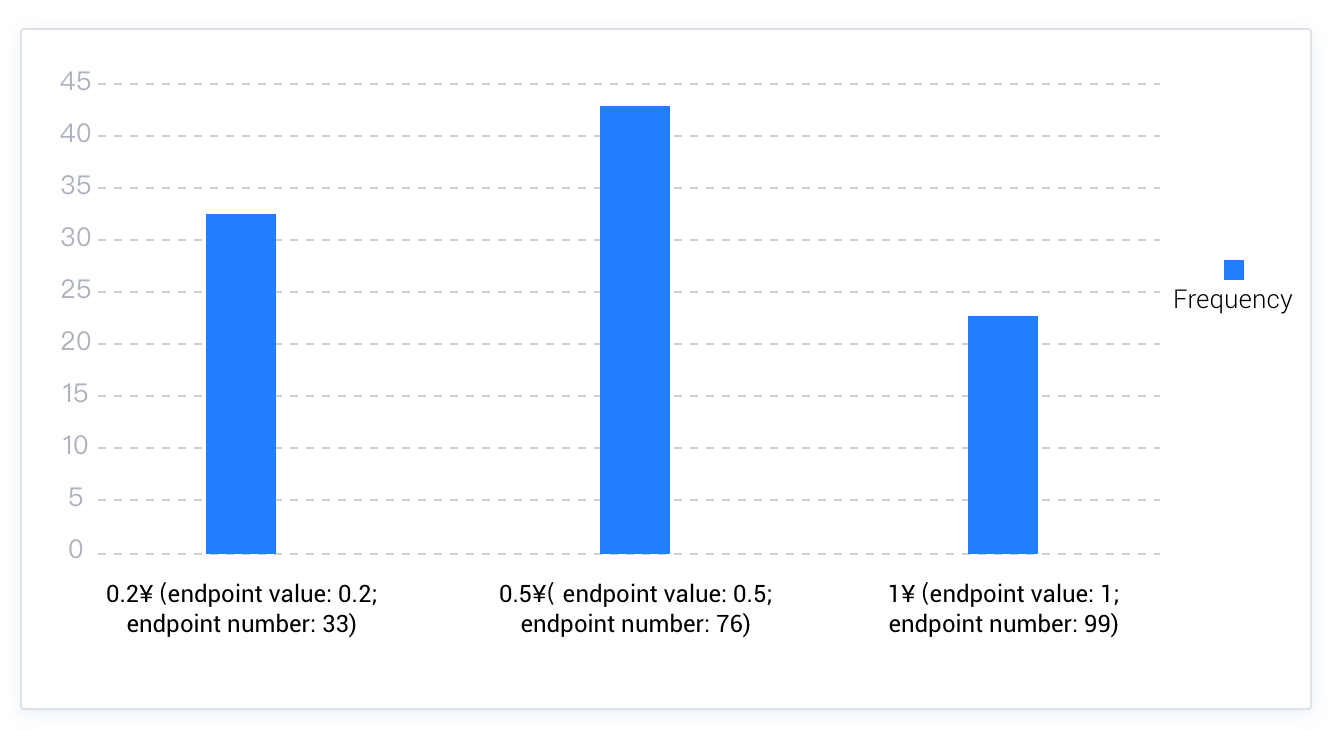
Topkヒストグラムは、一部のデータ特徴を取り出して全体のデータ分布を推定するため、誤差が大きくなりすぎないようにするためには、Topkヒストグラムが記録するデータ数と総データ数の比率が 1–(1/bucket_size) 以上である必要があります。例えば、上記のシナリオで、指定したバケット数が3、硬貨の総数が100枚の場合、Topkヒストグラムが99枚のデータを記録していれば、明らかに 99/100 > 2/3 となり、要件を満たしています。現在、OceanBaseデータベースのオプティマイザーは主にLossy Countingアルゴリズムを用いてTopkヒストグラムを実装しています。
ハイブリッドヒストグラム
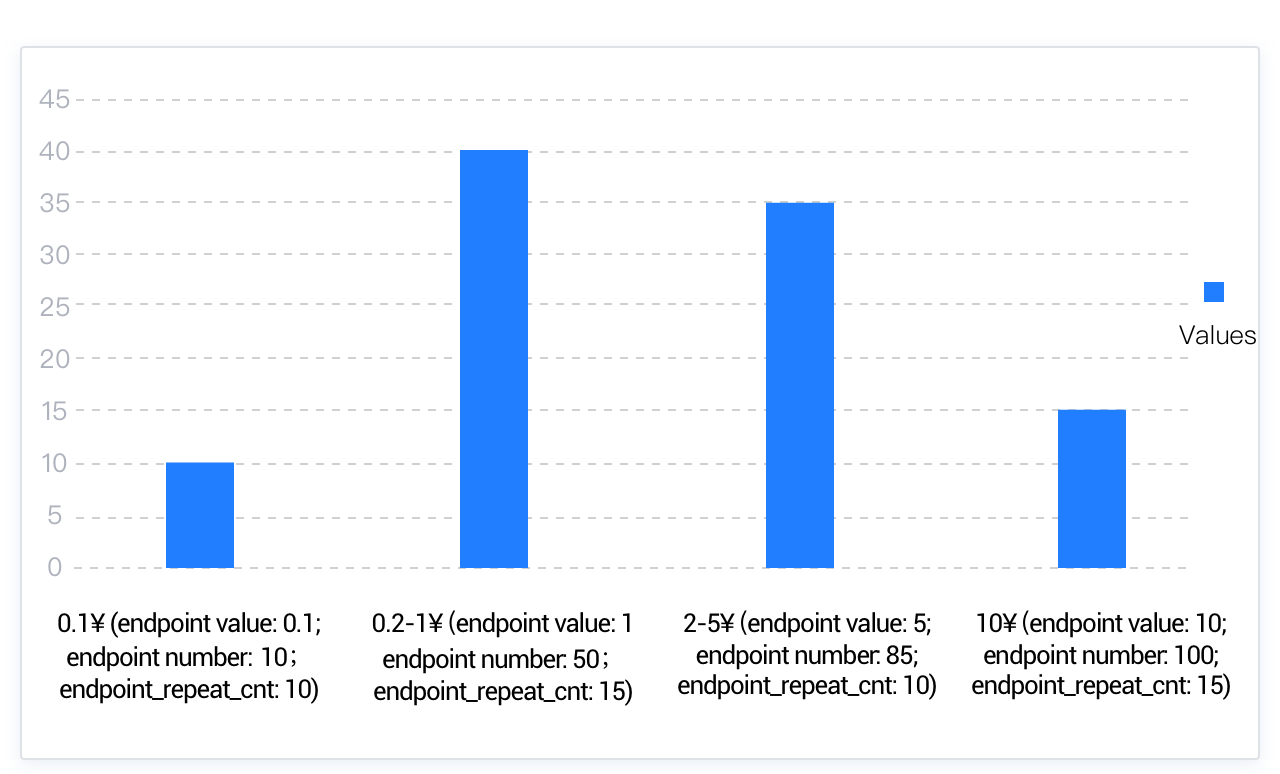
データ量が非常に多い大規模テーブルのシナリオでは、指定されたヒストグラムのバケット数がNDV値を下回り、同時にTopkヒストグラムも最小データ割合を満たせない場合があります。このような場合、データ分布の特徴をより均等に記述するためのヒストグラムが必要となり、ハイブリッドヒストグラムが導入されました。ハイブリッドヒストグラムは、指定されたデータ量を収集してヒストグラムを構築します。頻度ヒストグラムやTopkヒストグラムとは異なり、一つのバケットに複数の異なるValue値を含めることができます。収集したデータ量をバケット数で分割し、各区間内のすべてのデータを対応するバケットに配置することで、より少ないバケット数でより大量のデータ分布を記述できます。バケット内の最大Value値がendpoint_valueとして扱われ、endpoint_repeat_cntが追加されてendpoint_valueの頻度を記録します。
例えば、同じく100枚のコインがある場合:0.1元が10枚、0.2元が10枚、0.5元が15枚、1元が15枚、2元が25枚、5元が10枚、10元が15枚です。これにより計算されるTopkヒストグラムのデータカバー率は(25+15+15+15)/100=0.7であり、Topkがカバーするデータ割合の最小しきい値は1-1/N =3/4=0.75です。このしきい値に達していないため、Topkヒストグラムの条件を満たさない場合、バケット数を4に指定した場合(バケット数が列のNDV値を下回り、頻度ヒストグラムの条件を満たさない)に構築されるハイブリッドヒストグラムは以下のとおりです。
ヒストグラムの選択戦略
OceanBaseデータベースのオプティマイザーは、列から情報を収集してヒストグラムを作成する際、バケット数がオプティマイザーのパフォーマンスに与える影響を考慮します(バケット数が多すぎると、検索性能とデータストレージに負の影響を及ぼします)。そのため、一般的にデフォルトでは、列のNDV値はヒストグラムのバケット数(bucket_size)以下であることが望ましく、デフォルト値は254です。
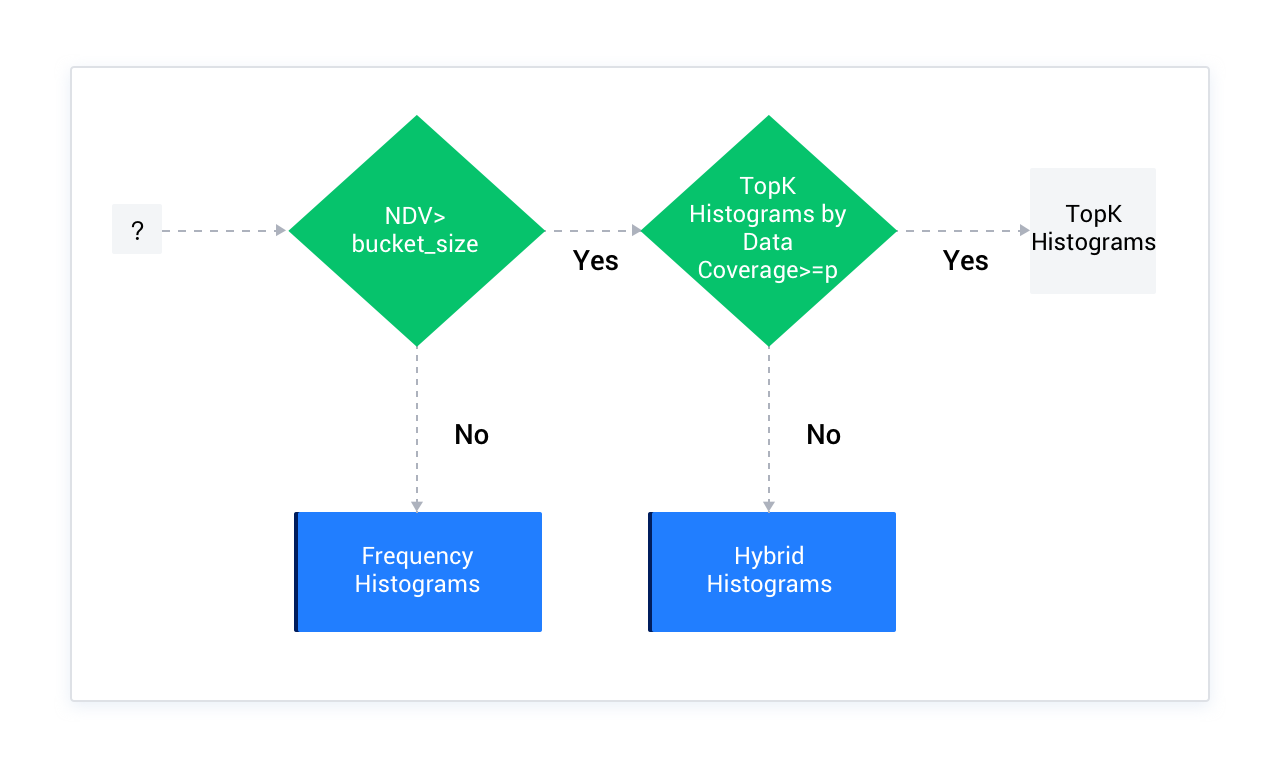
指定された列における異なる値のNDV(Number of Distinct Values)の数が254以下の場合、頻度ヒストグラムを使用します。
254を超える場合、TopKヒストグラムを優先的に使用します。具体的な方法は、列の情報を統計した後、バケットに対応する頻度の降順で並べ替え、番号が254を超えるバケットを除外します。ただし、この254個のバケットで統計されたデータ量が全体のデータ量に対する割合が1 - (1/bucket_size)以上であることを保証する必要があります。デフォルト値は99.6%です。
2の条件を満たさない場合、混合ヒストグラムを使用します。バケットを再定義することで、各バケットがより多くのデータを表現できるようにし、同時にバケットの端点値(endpoint_value)とその頻度(endpoint_repeat_cnt)を含む新しい値を導入して、バケットの定義を詳細に記述します。