


本ガイドは、Apache FlinkとOceanBaseデータベースを使用して効率的なデータパイプラインを構築したい開発者を対象としています。Flink初心者であっても上級ユーザーであっても、本記事は以下の点で役立ちます:
- Flinkのコアな使い方をすぐにマスターする
- OceanBaseデータベースが提供する各種Flink Connectorについて詳しく理解する
- 実際のビジネスシナリオに基づいて、最適な統合ソリューションを選択する
適用バージョン
- Flink V1.15以降
- JDBCコネクタはOceanaBase V3.x、V4.x以降に対応している必要があります。
- Flink Connector OceanBase Direct Load、OBKV-HBase Connector、OBKV-HBase2 ConnectorはOceanaBase V4.2.x以降に対応している必要があります。
Flinkの基礎
Apache Flinkとは
Apache Flinkは、オープンソースのストリーム・バッチ統合型計算エンジンであり、リアルタイムデータストリームとバッチデータを効率的に処理できます。データ統合シナリオにおいて、Flinkは強力な機能を提供し、システム間のデータ同期、変換、処理をサポートします。
なぜFlink SQLを推奨するのか
Flink SQLは、Flinkを使用する最もシンプルで効率的な方法です。SQLに似た構文を使用して、以下のことが可能です:
- さまざまなデータソース(Kafka、MySQL、OceanBaseデータベースなど)に接続する。
- フィルタリング、集計、変換などの操作を実行する。
- 結果をターゲットシステムに書き込む。
Java/Scalaコードを記述する必要はなく、数行のSQLで複雑なタスクを実行できます。
KafkaからOceanBaseデータベースへのリアルタイム同期
以下のFlink SQLスクリプトは、Flink SQL ClientまたはFlinkジョブで直接実行でき、Kafkaから注文データを消費し、OceanBaseデータベースにリアルタイムで同期することができます。
説明
CREATE TABLE でソースとターゲットを定義し、次に INSERT INTO ... SELECT ステートメントを使用することで、変換を伴うリアルタイムデータ同期を実現できます。
Kafkaのソーステーブルを定義します。
CREATE TABLE kafka_orders ( order_id BIGINT, user_id BIGINT, amount DECIMAL(10, 2), order_time TIMESTAMP(3) ) WITH ( 'connector' = 'kafka', 'topic' = 'orders', 'properties.bootstrap.servers' = 'localhost:9092', 'properties.group.id' = 'flink-consumer', 'format' = 'json', 'scan.startup.mode' = 'latest-offset' );OceanBaseデータベースのターゲットテーブルを定義します。
CREATE TABLE oceanbase_orders ( order_id BIGINT, user_id BIGINT, amount DECIMAL(10, 2), order_time TIMESTAMP(3), PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'connector' = 'oceanbase', 'url' = 'jdbc:mysql://127.0.0.1:2881/test', 'username' = 'root@test', 'password' = 'password', 'table-name' = 'orders' );データフロー(変換とフィルタリングを含む)を実行します。
INSERT INTO oceanbase_orders SELECT order_id, user_id, amount * 1.1 AS amount, -- データ変換が可能 order_time FROM kafka_orders WHERE amount > 100; -- データフィルタリングが可能
主要な概念の概要
概念 |
説明 |
|---|---|
| Source | データソース(例:Kafka、OceanBase CDC)。 |
| Sink | データの宛先(例:OceanBaseデータベース、Kafka)。 |
| Connector | Flinkと外部システムをつなぐ橋渡し役です。 |
| SQL DDL | CREATE TABLE を使用してデータソース/ターゲットを宣言します。 |
| SQL DML | INSERT INTO ... SELECT を使用してデータフローを駆動します。 |
Flink SQLの実行方法
方法1:SQLクライアント(対話型)
# Flink SQLクライアントを起動する ./bin/sql-client.sh # Flink SQL> プロンプトでコマンドを実行する Flink SQL> CREATE TABLE ... Flink SQL> INSERT INTO ...方法2:SQLファイルの提出
# SQLをファイル(例:job.sql)に保存して提出する ./bin/sql-client.sh -f job.sql方法3:Web UIまたはプログラミングAPI
Flink Web UIを使用してSQLタスクを提出するか、Table API/DataStream APIを使用してJava/Scalaプログラムを作成します。
OceanBase Flink Connectorの概要と選定ガイド
上記の例では、'connector' = 'oceanbase' を使用しています。実際には、OceanBaseはFlink向けに読み取り、書き込み、CDCなど、あらゆるシナリオをカバーする複数の専用Connectorを提供しています。
コネクタ一覧
注意
- 異なるコネクタは互換性がないため、シナリオに応じて正確に選択する必要があります。
- OceanBaseデータベースのMySQLテナントとの互換性は高いため、Flink MySQL Connectorを再利用できます。Oracleテナントでは、Flink OceanBase Connectorを使用する必要があります。
シナリオ |
推奨コネクタ |
主な機能 |
ドキュメント |
|---|---|---|---|
| リアルタイムストリーミング書き込み、データ量が中程度の場合 | Flink Connector OceanBase | JDBCベース、汎用性が高い | Flink Connector OceanBase公式ドキュメント |
| Lookup次元テーブルの関連付け | Flink Connector JDBC (Lookupモード) | 標準JDBC | Flink Connector JDBC公式ドキュメント |
| フルテーブルのバッチ読み取り | Flink Connector JDBC (バッチ読み取り、単一並列度) | 標準JDBC | Flink Connector JDBC公式ドキュメント |
CDCデータ同期
注意OceanBaseデータベースのMySQLモードテナントのみサポートしています。Oracleモードテナントは現在対応していません。 |
Flink CDC (OceanBase CDC) | 並列フル + 増分読み取り | OceanBase CDC公式ドキュメント |
| 大規模データのインポート、TBレベルのデータ移行 | Flink Connector OceanBase Direct Load | ダイレクトロードベース、高スループット | Flink Connector OceanBase Direct Load |
| 固定列KVの高性能書き込み(簡易) | Flink Connector OBKV HBase | OBKV APIベース、ネスト構造 | Flink Connector OBKV HBase |
| 高性能KV書き込み(高度な機能) | Flink Connector OBKV HBase2 | フラット構造、動的列/部分的更新をサポート | Flink Connector OBKV HBase2 |
プロトコル選定の意思決定プロセス
以下の意思決定フローチャートに従って、適切なコネクターを選択できます。
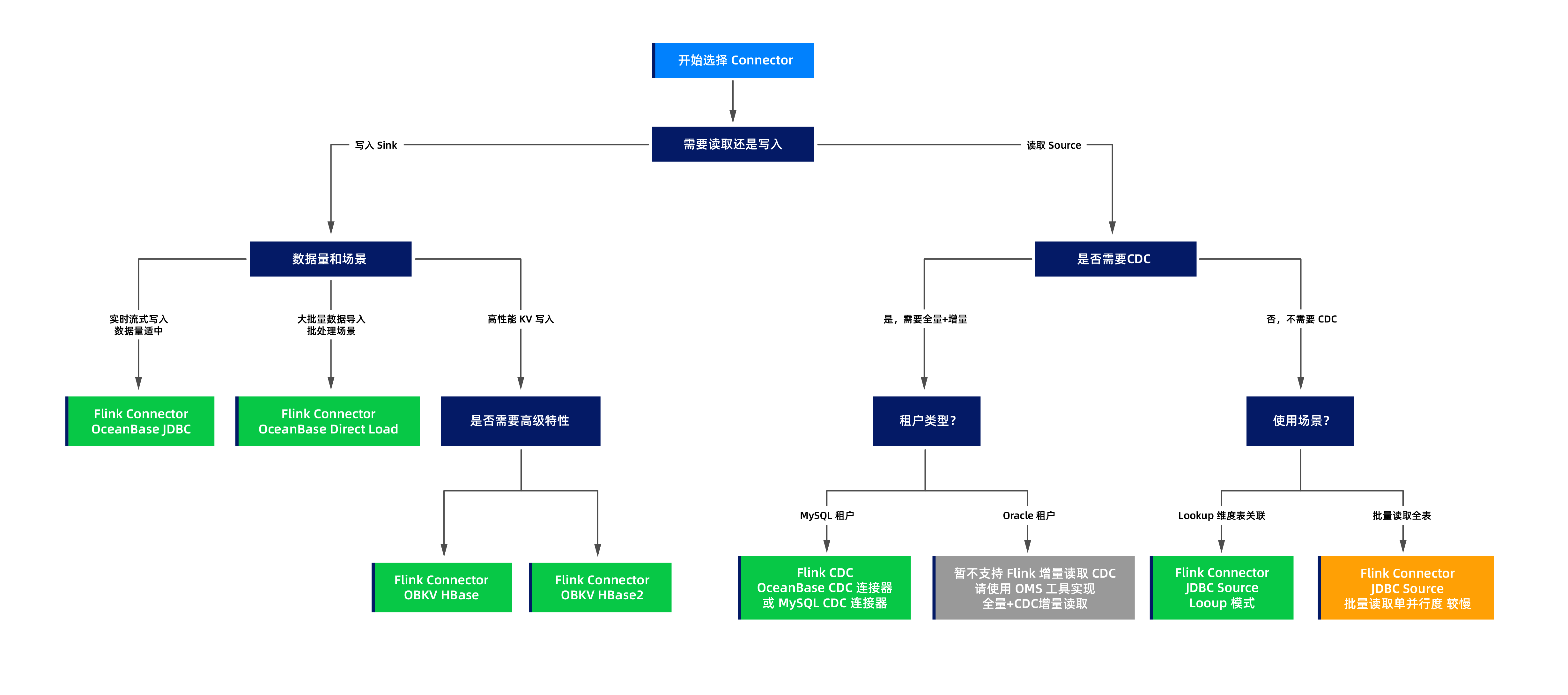
典型的なユースケースの詳細
シナリオ1:OceanBaseデータベースへのリアルタイムストリーミング書き込み
要件:
Kafka/PulsarのリアルタイムデータをOceanBaseデータベースに書き込む。
ソリューション:
Flink Connector OceanBase。詳細については、Flink Connector OceanBaseを参照してください。
利点:
- 無限ストリーム(Unbounded Stream)をサポートします。
- MySQL/Oracleモードと互換性があります。
- バッチ書き込みとバッファ最適化をサポートします。
例:
OceanBase Sinkテーブルを作成します。
CREATE TABLE orders_sink ( order_id BIGINT, user_id BIGINT, amount DECIMAL(10, 2), order_time TIMESTAMP(3), PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'connector' = 'oceanbase', 'url' = 'jdbc:mysql://127.0.0.1:2881/test', 'username' = 'root@test', 'password' = 'password', 'table-name' = 'orders', 'buffer-flush.interval' = '1s', 'buffer-flush.buffer-size' = '1000' );データをインポートします。
INSERT INTO orders_sink SELECT * FROM kafka_source;
シナリオ2:大量データの移行
要件:
TBレベルの履歴データをOceanBaseデータベースに移行する。
ソリューション:
Flink Connector OceanBase Direct Load。詳細については、Flink Connector OceanBase Direct Loadを参照してください。
利点:
- ダイレクトロードに基づいており、スループットが非常に高いです。
- 複数ノードで並列書き込みを行います。
- Batchモードに適しています。
注意事項:
- 有界ストリーム(Bounded Stream)をサポートしますが、リアルタイムストリームはサポートしません。
- インポート中、ターゲットテーブルはロックされます(読み取り専用)。
- より良いパフォーマンスを得るため、Flink Batchモードの使用を推奨します。
例:
Direct Load Sinkテーブルを作成します。
CREATE TABLE large_table_sink ( id BIGINT, name STRING, data STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'oceanbase-directload', 'url' = 'jdbc:mysql://127.0.0.1:2881/test', 'username' = 'root@test', 'password' = 'password', 'schema-name' = 'test', 'table-name' = 'large_table', 'parallel' = '8' -- パラレル度 );ソーステーブルから結果テーブルへバッチ書き込みを行います。
INSERT INTO large_table_sink SELECT * FROM source_table;
シナリオ3:高性能なKV書き込み(シンプルなシナリオ)
要件:
KVデータの高性能な書き込みが必要で、列構造はシンプルかつ固定されている。
ソリューション:
Flink Connector OBKV HBase。詳細については、Flink Connector OBKV HBaseを参照してください。
利点:
- OBKV HBase APIに基づいており、パフォーマンスが優れています。
- 固定列構造のシナリオに適しています。
制限:
- テーブル定義では、ネストされたROW構造を使用する必要があります。
- 動的列はサポートされていません。
- 一部の列の更新はサポートされていません。
例:
HBase Sinkテーブルを作成します。
CREATE TABLE hbase_sink (
rowkey STRING,
family1 ROW<column1 STRING, column2 STRING>, -- ネストされたROW構造
PRIMARY KEY (rowkey) NOT ENFORCED
) WITH (
'connector' = 'obkv-hbase',
'url' = 'http://127.0.0.1:8080/services?Action=ObRootServiceInfo&ObCluster=obcluster',
'username' = 'root@test#obcluster',
'password' = 'password',
'sys.username' = 'root',
'sys.password' = 'password',
'schema-name' = 'test',
'table-name' = 'htable1'
);
シナリオ4:高性能なKV書き込み(高度な機能)
要件:
高性能な書き込みが必要であり、動的カラム、部分的な列の更新、柔軟なタイムスタンプ制御などの高度な機能が求められます。
ソリューション:
Flink Connector OBKV HBase2。詳細については、Flink Connector OBKV HBase2を参照してください。
利点:
- フラットなテーブル構造で、定義が簡潔です。
- 動的カラムモードをサポートします:列名は実行時に動的に指定できます。
- 部分的な列の更新をサポートします:更新が必要な列のみを定義し、定義されていない列は更新されません。非常に柔軟です。
- タイムスタンプ制御をサポートします:異なる列に対して異なるタイムスタンプ(
tsColumn、tsMap)を設定できます。 - 性能はOBKV HBaseと同等です。
例:
HBase2 Sinkテーブルを作成します。
基本的な使用:フラット構造。
CREATE TABLE hbase2_sink ( rowkey STRING, column1 STRING, -- フラット構造、ROWネストは不要 column2 STRING, PRIMARY KEY (rowkey) NOT ENFORCED ) WITH ( 'connector' = 'obkv-hbase2', 'url' = 'http://127.0.0.1:8080/services?Action=ObRootServiceInfo&ObCluster=obcluster', 'username' = 'root@test#obcluster', 'password' = 'password', 'sys.username' = 'root', 'sys.password' = 'password', 'schema-name' = 'test', 'table-name' = 'htable1', 'columnFamily' = 'f' );部分的な列の更新例。
OceanBaseデータベース内のHBaseテーブルにcolumn1、column2、column3、column4など複数の列があると仮定します。Flinkテーブルでは、更新したい列のみを定義する必要があります。
CREATE TABLE partial_update_sink ( rowkey STRING, column1 STRING, -- 更新が必要な列のみを定義 column2 STRING, -- ここで定義されていない列(column3、column4など)は更新されません PRIMARY KEY (rowkey) NOT ENFORCED ) WITH ( 'connector' = 'obkv-hbase2', 'url' = 'http://127.0.0.1:8080/services?Action=ObRootServiceInfo&ObCluster=obcluster', 'username' = 'root@test#obcluster', 'password' = 'password', 'sys.username' = 'root', 'sys.password' = 'password', 'schema-name' = 'test', 'table-name' = 'htable1', 'columnFamily' = 'f' );
データを書き込み、column1とcolumn2のみを更新し、他の列(column3、column4など)は変更しません。
INSERT INTO partial_update_sink VALUES ('1', 'new_value1', 'new_value2');
シナリオ5:CDCデータ同期(MySQLテナント)
要件:
OceanBaseデータベースのデータ変更をリアルタイムでキャプチャし、フル+増分同期を実現する
ソリューション:
Flink CDC (OceanBase CDC)。詳細については、OceanBase CDC公式ドキュメントを参照してください。
利点:
- パラレルなフル読み取り(パフォーマンスはJDBCを大幅に上回る)。
- Binlogに基づく増分同期。
- 統合されたフル+増分プロセス。
制限:
MySQLモードのテナントのみサポートします。
使用例:
OceanBase CDCソーステーブルを作成します。
CREATE TABLE orders_cdc ( order_id BIGINT, user_id BIGINT, amount DECIMAL(10, 2), order_time TIMESTAMP(3), PRIMARY KEY (order_id) NOT ENFORCED ) WITH ( 'connector' = 'oceanbase-cdc', 'hostname' = '127.0.0.1', 'port' = '2881', 'username' = 'root@test', 'password' = 'password', 'database-name' = 'mydb', 'table-name' = 'orders', 'scan.startup.mode' = 'initial' -- フル+増分 );CDCデータを読み取り、処理します。
SELECT * FROM orders_cdc;
シナリオ6:ルックアップ次元テーブルの関連付け
要件:
ストリーム処理において、ユーザー次元情報を補完する。
ソリューション:
Flink Connector JDBC(ルックアップソースとして)。詳細については、Flink JDBC Connector公式ドキュメントを参照してください。
特長:
- ルックアップ結合をサポートします。
- キャッシュ最適化をサポートします。
注意
全表スキャンは単一並列度ですが、ルックアップシナリオは通常ポイントクエリであり、この制限を受けません。
例:
JDBCルックアップテーブルを作成します。
CREATE TABLE dim_user ( user_id BIGINT, user_name STRING, city STRING, PRIMARY KEY (user_id) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://127.0.0.1:2881/test', 'username' = 'root@test', 'password' = 'password', 'table-name' = 'dim_user', 'lookup.cache.max-rows' = '10000', -- キャッシュ設定 'lookup.cache.ttl' = '1 hour' );ストリームテーブルと次元テーブルを関連付けます。
SELECT o.order_id, o.user_id, u.user_name, -- 次元テーブルから補完 u.city, o.amount FROM orders_stream o LEFT JOIN dim_user FOR SYSTEM_TIME AS OF o.proc_time AS u ON o.user_id = u.user_id;
詳細な比較分析
以下では、混同しやすいいくつかのコネクターについて詳しく分析します。
OBKV HBaseとOBKV HBase2
比較項目 |
OBKV HBase |
OBKV HBase2 |
|---|---|---|
| データモデル | ネストされたROW構造 | 平坦化モデル |
| テーブル定義の複雑さ | 比較的複雑(ROW<...> のネストが必要) |
シンプル(列を直接定義する) |
| カラムファミリのサポート | 1つのテーブルに複数のカラムファミリを書き込める | 1つのテーブルは1つのカラムファミリのみをサポートする(複数のカラムファミリが必要な場合は、各カラムファミリごとに別々のテーブルを作成する必要があり、面倒) |
| 動的列のサポート | 不可 | 可 |
| 一部列の更新 | 不可 | 可(更新が必要な列のみを定義する) |
| タイムスタンプ制御 | 不可 | 可(tsColumn + tsMap) |
| 柔軟性 | 低い | 高い |
| パフォーマンス | 高い | 高い |
| 学習コスト | 低い(HBaseに精通している場合) | 中等(新機能を理解する必要がある) |
| 適用シナリオ | 複数のカラムファミリが必要なシナリオ、単純で固定された列 | 単一カラムファミリのシナリオ、動的列、一部更新、タイムスタンプ制御が必要な場合 |
テーブル定義の比較例:
OBKV HBase:ネストされたROW構造を採用しており、1つのテーブルで複数のカラムファミリをサポートします。
CREATE TABLE hbase_sink ( rowkey STRING, family1 ROW<column1 STRING, column2 STRING>, -- カラムファミリ1 family2 ROW<column3 STRING, column4 STRING>, -- カラムファミリ2(複数のカラムファミリをサポート) PRIMARY KEY (rowkey) NOT ENFORCED ) WITH ( 'connector' = 'obkv-hbase', ... );書き込み時には、複数のカラムファミリに同時に書き込むことができます。
INSERT INTO hbase_sink VALUES ('row1', ROW('val1', 'val2'), ROW('val3', 'val4'));OBKV HBase2:フラット構造を採用しており、1つのテーブルで指定できるのは1つのカラムファミリのみです。
複数のカラムファミリに書き込む必要がある場合、各カラムファミリごとに個別のテーブルを作成する必要があります(面倒です)。
カラムファミリ family1 のテーブル:
CREATE TABLE hbase2_family1_sink ( rowkey STRING, column1 STRING, column2 STRING, PRIMARY KEY (rowkey) NOT ENFORCED ) WITH ( 'connector' = 'obkv-hbase2', 'columnFamily' = 'family1', -- 1つのカラムファミリのみ指定可能 ... );カラムファミリ family2 のテーブル(個別に作成する必要があります)
CREATE TABLE hbase2_family2_sink ( rowkey STRING, column3 STRING, column4 STRING, PRIMARY KEY (rowkey) NOT ENFORCED ) WITH ( 'connector' = 'obkv-hbase2', 'columnFamily' = 'family2', -- 異なるカラムファミリ ... );
書き込み時には、2つのテーブルに分けて書き込む必要があります。
カラムファミリ family1 のテーブルに書き込む:
INSERT INTO hbase2_family1_sink VALUES ('row1', 'val1', 'val2');カラムファミリ family2 のテーブルに書き込む:
INSERT INTO hbase2_family2_sink VALUES ('row1', 'val3', 'val4');
説明
選定の推奨事項は以下の通りです:
- 複数のカラムファミリが必要な場合:OBKV HBaseを強く推奨します。
- HBase:1つのテーブルで複数のカラムファミリを管理でき、シンプルで便利です。
- HBase2:各カラムファミリごとに個別のテーブルを作成し、それぞれに書き込む必要があり、面倒です。
- 動的な列の追加・削除、部分的な列の更新、タイムスタンプの制御などの高度な機能が必要な場合:必ずOBKV HBase2を選択してください。
- シンプルなシナリオ(固定列、単一カラムファミリ):どちらも可能ですが、HBase2のテーブル定義の方が簡潔なため、優先的に使用することを推奨します。
- 新規プロジェクトの推奨:単一カラムファミリのシナリオではOBKV HBase2を、複数カラムファミリのシナリオではOBKV HBaseを推奨します。
OceanBase CDCとJDBCによる読み取り
比較項目 |
OceanBase CDC |
JDBC Connector |
|---|---|---|
| フル読み取りの並列度 | 並列読み取りをサポート(高並列度) | 単一並列度(低速) |
| 増分読み取り | Binlogの増分読み取りをサポート | サポートなし |
| Lookup Join | サポートなし | サポート(主な用途) |
| バッチ全テーブル読み取り | サポート(並列、高速) | サポート(単一スレッド、低速) |
| テナントサポート | MySQLテナントのみ | MySQLおよびOracleテナント |
| 主な用途 | CDCによるフル+増分同期 | Lookupによる次元テーブルの関連付け |
| データのリアルタイム性 | 准リアルタイム(Binlog遅延) | クエリ時リアルタイム |
説明
選定の推奨事項は以下の通りです。
- CDCシナリオ(フル+増分同期):OceanBase CDCを優先的に選択します(MySQLテナントのみ)。
- Lookup Joinシナリオ(次元表の関連付け):JDBC Connectorを選択します。
- 一括全表読み取り:OceanBase CDCを優先的に選択します(MySQLテナント)。OracleテナントはJDBC Connectorのみ使用可能で、パフォーマンスが低下します。
シンクへの書き込み比較
特性 |
JDBC |
Direct Load |
OBKV HBase |
OBKV HBase2 |
|---|---|---|---|---|
| データストリームタイプ | 無限/有界 | 有界のみ | 無限/有界 | 無限/有界 |
| スループット | 中 | 非常に高い | 高 | 高 |
| レイテンシ | 低 | 高(バッチ) | 低 | 低 |
| テーブルロック | なし | インポート中のテーブルロック | なし | なし |
| 互換モード | MySQL/Oracle | MySQL/Oracle | MySQL | MySQL |
| 複雑さ | シンプル | シンプル | 中 | 中 |
| 典型的なユースケース | リアルタイム書き込み | バッチインポート | KV高性能書き込み | KV高性能書き込み + 機能拡張 |
よくある質問(FAQ)
質問1:Direct Load SinkとJDBC Sinkの違いは何ですか?どちらを選択すべきですか?
主な違い:
- JDBC Sink:標準JDBCプロトコルに基づいており、リアルタイムストリーミング書き込みに適しています。無限ストリームをサポートし、テーブルのロックは不要です。
- Direct Load Sink:ダイレクトロードAPIに基づいており、大量データのインポートに適しています。スループットが非常に高いですが、有限ストリームのみをサポートし、インポート中はテーブルをロックします。
選択の推奨事項:
- リアルタイムストリーミング書き込み(例:KafkaからOceanBaseデータベースへ):JDBC Sinkを使用することを推奨します。
- 大量の履歴データのインポート(例:データ移行):Direct Load Sinkを使用することを推奨します。
質問2:OBKV HBaseとOBKV HBase2の違いは何ですか?どちらを選択すべきですか?
主な違い:
テーブル定義方法:HBaseはネストされたROW構造を使用し、HBase2はフラット構造(よりシンプル)を使用します。
カラムファミリーのサポート:
- HBase:1つのFlinkテーブルに複数のカラムファミリーを書き込むことができ、非常に便利です。
- HBase2:1つのFlinkテーブルでは1つのカラムファミリーのみを指定できます。複数のカラムファミリーに書き込む必要がある場合は、各カラムファミリーごとに個別のテーブルを作成して書き込む必要があり、やや面倒です。
上級機能:HBase2は動的カラム、部分的カラム更新、タイムスタンプ制御をサポートしますが、HBaseはサポートしません。
適用シナリオ:HBaseは複数のカラムファミリーが必要なシナリオに適しており、HBase2は上級機能が必要な単一カラムファミリーシナリオに適しています。
選択の推奨事項:
複数のカラムファミリーが必要な場合:OBKV HBaseを強く推奨します(HBase2では各カラムファミリーごとにテーブルを作成する必要があり、面倒です)。
動的カラム、部分的カラム更新、タイムスタンプ制御が必要なシナリオ:OBKV HBase2を推奨します。
シンプルな固定カラム、単一カラムファミリーシナリオ:どちらも可能ですが、OBKV HBase2を推奨します(テーブル定義がよりシンプル)。
新規プロジェクトの推奨:
- 単一カラムファミリーには OBKV HBase2 を使用します。
- 複数カラムファミリーには OBKV HBase を使用します。
質問3:JDBC Sourceの使用シナリオは何ですか?CDCとの違いは何ですか?
JDBC Sourceには主に2つの使用シナリオがあります:
Lookup Join(次元テーブルの結合)- 推奨用途
- ストリーム処理において、主キーに基づいて次元テーブルをリアルタイムにクエリします。
- キャッシュ最適化をサポートし、パフォーマンスが高いです。
- これがJDBC Sourceの主な用途です。
フルテーブルのバッチ読み取り。
- OceanBaseデータベースの全テーブルデータを読み取ることができます。
- 単一並列度ではパフォーマンスが遅く、大規模テーブルでの使用は推奨されません。
- 少量データのバッチ読み取りに適しています。
JDBC SourceとCDCの比較:
- OceanBase CDC:並列フル読み取りとbinlog増分読み取りをサポートし、パフォーマンスが高く、CDCシナリオに適しています(MySQLテナントのみ)。
- JDBC Source:主にLookup Joinに使用されますが、バッチ読み取りも可能ですがパフォーマンスは低いです(単一並列度)。
選択の推奨事項:
- Lookup 次元テーブルの結合:JDBC Sourceを選択します(必須)。
- CDC フル + 増分読み取り(MySQLテナント):OceanBase CDCを選択します(推奨)。
- フルテーブルのバッチ読み取り:OceanBase CDCを優先的に選択します。サポートされない場合(Oracleテナント)、次に JDBC Source を選択します。
質問4:OceanBase CDCはなぜMySQLテナントのみをサポートするのですか?Oracleテナントはどうすればよいですか?
OceanBase CDCはMySQL互換のbinlogサービスをサポートしています。Oracleテナントでは、OMSツールを使用してCDC増分読み取りを実現してください。
Binlogの詳細については、Binlogサービスの概要を参照してください。
質問5:適切なバッチサイズと並列度はどのように選択しますか?
バッチサイズ(Buffer Size):
- 小バッチ(100-500):低遅延シナリオに適しており、データを迅速に書き込みます。
- 中バッチ(1000-5000):遅延とスループットのバランスが取れており、デフォルト値を推奨します。
- 大バッチ(5000+):高スループットシナリオに適していますが、遅延が増加します。
並列度(Parallelism):
- 一般的には CPUコア数 またはその倍数に設定します。
- ダイレクトロードシナリオでは、テナントのリソースに応じて高い並列度(例:8-16)を設定することで、ダイレクトロードの機能を最大限に活用できます。
- OceanBaseクラスタの負荷能力を考慮する必要があります。
質問6:異なるコネクターを混在して使用できますか?
可能です。1つのFlinkタスク内で複数の異なるコネクターを同時に使用できます。
一般的な組み合わせ:
- Flink CDC (MySQL) Source + OceanBase JDBC Sink:MySQLからOceanBaseデータベースへのリアルタイム同期。
- OceanBase CDC Source + Kafka Sink:OceanBaseからKafkaメッセージキューへ。
- Kafka Source + JDBC Lookup + OceanBase Sink:Kafkaデータを関連するディメンションテーブルと結合した後、OceanBaseデータベースに書き込む。