


OceanBaseデータベースのモニタリングは現在、主にOCPのモニタリング機能に依存しています。データベースクラスタ、テナント、ノードの各レベルで、パフォーマンス、容量、稼働状態などの指標を7×24時間モニタリングし、グラフで可視化して表示します。これにより、ユーザーはOceanBaseクラスタの利用状況を包括的に把握し、クラスタの異常を迅速に検出し、イベント発生時に即座に警告を受けることで、データベースの安定かつ効率的な正常運用を確保できます。
モニタリング
OceanBaseデータベースのモニタリングは、処理パスに基づいて以下の部分に分けられます:
メトリクスパス(一般的なモニタリング指標):OBServerノードの状態監視、obproxyの状態監視、ホストメトリクス監視。
OB SQLパス:OceanBaseデータベース関連のSQL、Plan指標を含みます。
OBリソース使用状況パス:OceanBaseクラスタ、テナントのリソース使用状況を収集します。
Metric リンク
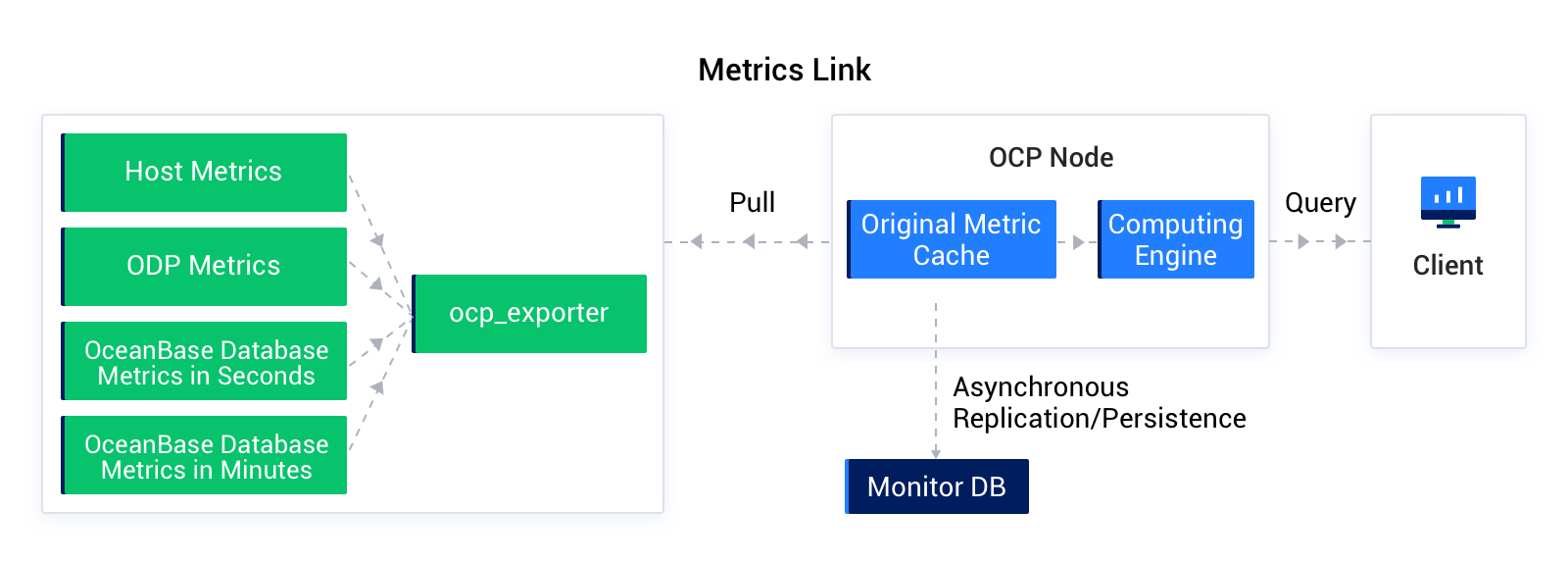
このリンクは、以下の種類のメトリクスを収集します:
ホストメトリクス:ホスト、およびホスト上にデプロイされた関連サービス(例:OBServerノード、obproxy)のCPU、ディスク、I/O、LOADなどの情報。
obproxyメトリクス:obproxyの関連するリクエスト、セッション、トランザクションなどの情報。
OB秒(分)レベルメトリクス:OBノードのリソース状態、QTPSなどのパフォーマンス監視情報に対応します。
Metric リンクは、OCPで管理されるホスト上のOCP Agentのocp_exporterプログラムに依存して収集を行います。ocp_exporterは、監視収集のための一連のRESTfulサービスを外部に提供し、インターフェースはPrometheus仕様の監視メトリクスを提供します。内部では、NodeExporter(ホスト監視)、OBProxyExporter(obproxy監視)、OBCollector(OceanBase監視)に依存して多様なメトリクスを収集します。OCPは、指定されたタイプの監視メトリクスを収集した後、それらを集計・変換して監視データベース(MonitorDB)に保存します。監視計算エンジンは、監視式(Prometheusベースの式)に基づいて監視データベースから監視データを照会・計算し、クライアントに返します。クライアントは、返された計算済み情報に基づいて監視グラフを表示します。
OB SQL リンク

このリンクは、各OBクラスタのSQLデータとSQL実行計画データを収集するために使用されます。主に以下のビューからデータを収集します:
v$sql_audit:SQLの実行監査情報を記録します。
v$plan_cache_plan_explain:実行計画の各演算子の情報を記録します。
v$plan_cache_plan_stat:実行計画の監査情報を記録します。
SQLデータとSQL実行計画のデータ量が非常に多いことを考慮し、パフォーマンスを向上させ、リソース消費を削減するために、このリンクの収集プログラムであるobstat2は、C++で開発された高性能で軽量なプログラムです。収集頻度の設定に基づき、収集サイクル中にビューからSQLと実行計画情報を収集し、ローカルで集計計算した後、OCPの監視データベース(MonitorDB)に保存します。OCPのバックグラウンドタスクは定期的に監視データベースにアクセスし、最小粒度のSQL auditとSQL planデータを大きな時間粒度の結果に集計して保存します。Webページからクエリを実行する際、選択した時間区間が短い場合は、元のレポートテーブルを直接クエリし、時間粒度が大きい場合は集計テーブルをクエリします。
OBリソース使用状況の連携
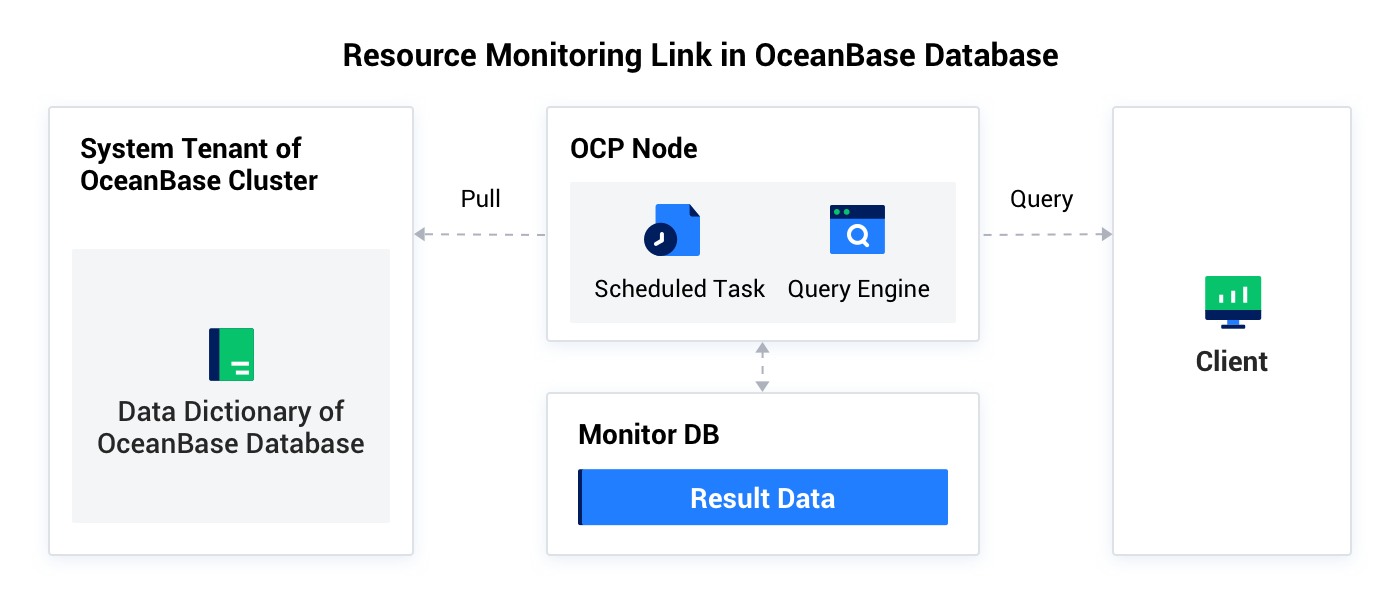
この連携は、OceanBaseクラスタのリソース使用状況を収集する役割を担い、主に以下のデータソースからデータを収集します:
CPU情報:
- GV$OB_SERVERS:CPUの総コア数、割り当て済みコア数。
メモリ情報
- GV$OB_SERVERS:メモリの総サイズ、使用済みサイズ。
ディスク情報
- GV$OB_SERVERS:ディスクの総サイズ、使用済み情報。
システムイベント情報
- oceanbase.DBA_OB_ROOTSERVICE_EVENT_HISTORY:OceanBaseクラスタのシステムイベント情報。
OBリソース使用状況の連携は、OCPの定期タスクによってトリガーされ、各クラスタのsysテナントがクラスタ、テナント、データベース、テーブルなどの観点からOBServerノード上のCPU、Memory、Diskなどの利用率を収集し、データを監視データベースに保存します。クライアントからクエリリクエストが送信されると、クエリエンジンはクラスタ、テナント、データベース、テーブルなどの観点から統計を行い、統計後のデータをフロントエンドに返して表示します。
アラート
OceanBaseデータベースは主にOCPアラートを通じて、本番環境のホストやデータベースのリスク・障害に対する予警を実現します。データベースおよびそのホスト環境で障害が発生しようとしている場合、または障害が発生した場合、組み込みのアラート項目が異常を検出し、アラートチャネルを通じてアラートサブスクライバーに通知します。本記事では、アラート機能について、アラート項目の設定、アラート検出、アラート集約、アラートサブスクリプションの4つの側面から紹介します。
アラート項目
OCPには約60個のアラート項目が組み込まれており、各アラート項目はアラート名、レベル、概要テンプレート、詳細テンプレートなどの基本情報と、アラート検出に関連するルール情報を記述しています。
アラートのリスクレベルに応じて、5つのアラートレベルが定義されています:サービス停止、重大、警告、注意、リマインダー。アラートが発生すると、関連するテンプレート変数が生成されます。これらの変数は概要テンプレートや詳細テンプレートに設定し、必要なコンテキスト情報を表示できます。アラート検出ルールは、検出期間、検出サイクル、アラート回復サイクル、検出式の設定など、モニタリング式に基づく検出ルールです。
これらの組み込みアラート項目は、データベースリソース、データベースイベント、ホストリソース、OCPイベントなどの観点からアラートを記述しています。例えば、データベースCPU、メモリ、MemStore、ディスク使用率などのデータベースリソースアラート、マージタイムアウト、ハングトランザクションなどのデータベースイベントアラート、ホストネットワーク、ディスクアラート、およびOCPの監視API状態異常、metadb同期OBクラスタなどのアラートが該当します。
アラート検出
アラート検出とは、組み込みのアラート項目を検出してアラートをトリガーするプロセスであり、モニタリング式に基づく検出と定期タスクのロジック検出の2種類があります。アラート検出後、アラートイベントが生成され、アラートが発生したことになります。ただし、このアラートイベントをユーザーに通知するかどうかは、その後のアラート集約ロジックに依存します。大量のアラートメッセージが発生するのを避けるため、アラートを抑制する操作が必要になる場合があります。
モニタリング式に基づくアラートでは、監視APIを通じて異なる次元から監視データを集約し、APIのクエリ結果としきい値を照合します。アラートトリガー条件を満たすとアラートイベントが生成されます。

上図はモニタリング式に基づくアラート検出における状態遷移です。durationはアラートの検出期間を指し、durationの時間内に連続してアラートがトリガーされた場合にアラートイベントが生成されます。durationは異常状態のフォールトトレランスシナリオで一般的に使用されます。偶発的な1回の異常は即座にアラートをトリガーする必要はなく、継続的な異常があった場合にのみアラートをトリガーします。
定期タスクのロジック検出は、いくつかの複雑なシナリオに対応し、スクリプト言語を使用して検出する必要があります。この種の検出方法は、アラートAPIを直接呼び出してアラートイベントを生成するもので、OceanBaseログアラートやOMSアラートなどが該当します。外部システム(OCP以外のシステム)におけるイベントベースのアラートに適しています。
アラートの集約
アラートの集約とは、事前に設定されたルールに従ってアラートメッセージを少数のメッセージ(集約メッセージと呼ばれる)に統合し、アラートストームを防ぐことです。
以下はアラート集約の設定例です。これは深優先マッチングルールであり、例えばOceanBaseログアラート(ob_log_alarm)の集約次元は、alarm_type(アラート項目)+ob_error_code(ログエラーコード)+obregion(OceanBaseクラスタ名)です。
aggregate:
# root層はデフォルトの集約で、アラートタイプ、オブジェクトに基づいて集約されます。
match: {}
group_by:
- "alarm_type"
aggregate_wait_seconds: 10
aggregate_interval_seconds: 60
repeat_interval_seconds: 3600
aggregates:
# OBアラートについては、アラートタイプ、OBクラスタに基づいて集約されます。
- match:
app: "OB"
group_by:
- "alarm_type"
- "obregion"
aggregate_wait_seconds: 10
aggregate_interval_seconds: 60
repeat_interval_seconds: 3600
aggregates:
# OBログアラートについては、アラートタイプ、ログエラーコード、OBクラスタに基づいて集約されます。
- match:
alarm_type: "ob_log_alarm"
group_by:
- "alarm_type"
- "ob_error_code"
- "obregion"
aggregate_wait_seconds: 10
aggregate_interval_seconds: 60
repeat_interval_seconds: 3600
aggregate_wait_secondsは初回アラート発生時の待機時間であり、この時間内に同じ集約次元で発生したアラートは1つのアラートメッセージに集約されます。
aggregate_interval_secondsは同じ集約次元の集約間隔であり、新しい集約アラートメッセージが生成されるまでの時間です。
repeat_interval_secondsは同一アラート(同じアラートID、アラートが回復していない場合IDは増加しない)の送信間隔であり、同一アラートが次のrepeat_interval_secondsサイクルで集約されます。
アラートサブスクリプション
アラートサブスクリプション機能は、アラートメッセージを異なるユーザーに送信するためのものです。
まず、アラート項目を異なるグループに分類し、サブスクリプション時にそのアラートグループを直接購読できます。現在、OCPは以下の6つのアラートグループに分類しています:
ocp:OCP関連のアラート項目。
dba:OceanBaseデータベース関連のアラート項目。
info:操作系(Infoレベル)のアラート項目。
oms:OMSアプリケーションのアラート項目。
backup:バックアップ・リカバリのアラート項目。
dev:運用保守関連のアラート項目。
クラスタやレベルごとにアラートをサブスクライブし、異なるアラートを異なるアラートチャネルに送信できます。アラートチャネルはアラートの送信方法を定義しており、現在はbash/pythonスクリプトによる送信やHTTP APIによる送信をサポートしています。また、チャネルにレート制限ポリシーを設定することで、過剰なアラート送信を防ぐことも可能です。