


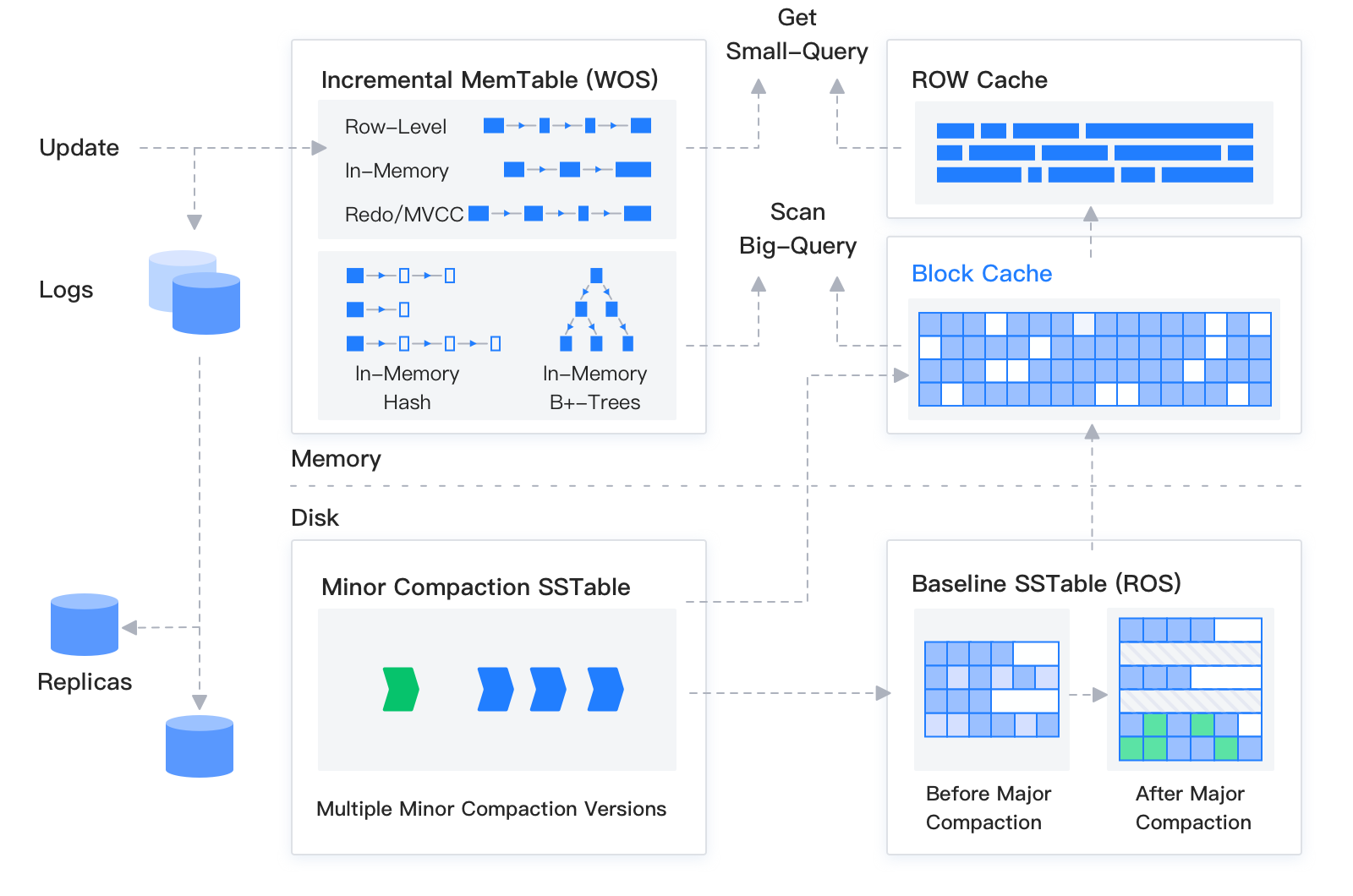
OceanBaseデータベースのストレージエンジンはLSM-Treeアーキテクチャに基づいており、データを静的なベースラインデータ(SSTableに格納)と動的な増分データ(MemTableに格納)の2つに分けています。SSTableは読み取り専用で、一度生成されると変更されずにディスクに保存されます。MemTableは読み書き可能で、メモリに保存されます。データベースのDML操作(挿入、更新、削除など)はまずMemTableに書き込まれ、MemTableが一定のサイズに達すると、ディスクに転送してSSTableとなります。クエリ実行時には、SSTableとMemTableに対して別々にクエリを実行し、その結果をマージしてSQL層に返します。同時に、メモリ内ではBlock CacheとRow cacheを実装し、ベースラインデータへのランダムな読み取りを回避しています。
メモリ内の増分データが一定の規模に達すると、増分データとベースラインデータのメジャーコンパクションがトリガーされ、増分データがディスクにフラッシュされます。また、毎晩のアイドルタイムには、システムが自動的に日次メジャーコンパクションも実行します。
OceanBaseデータベースは本質的にベースラインデータに増分データを加えたストレージエンジンであり、LSM-Treeアーキテクチャの利点を維持しつつ、従来のリレーショナルデータベースのストレージエンジンの長所も取り入れています。
従来のデータベースはデータを多数のページに分割しますが、OceanBaseデータベースも従来のデータベースの考え方を参考に、データファイルを2MBを基本単位として複数のマクロブロックに分割し、各マクロブロック内部をさらに複数の可変長のマイクロブロックに細分化しています。メジャーコンパクション時にはマクロブロック単位でデータの再利用が行われ、更新されていないデータのマクロブロックは再度開いて読み取ることがないため、メジャーコンパクション期間中のライトアンプリフィケーションを可能な限り削減でき、従来のLSM-Treeアーキテクチャのデータベースに比べてメジャーコンパクションコストを大幅に低減しています。
OceanBaseデータベースはベースラインデータに増分データを加えた設計を採用しているため、一部のデータはベースラインに、一部は増分に存在します。原理上、毎回のクエリではベースラインと増分の両方を読み取る必要があります。このため、OceanBaseデータベースでは特に単一行に対する最適化を含め、多くの最適化が施されています。OceanBaseデータベース内部では、データブロックのキャッシュに加えて行のキャッシュも行われ、行キャッシュは単一行に対するクエリ性能を大幅に向上させます。行が存在しない「NULLクエリ」に対しては、ブルームフィルターを構築し、そのブルームフィルターをキャッシュします。OLTP業務の大部分は小規模なクエリであり、小規模クエリの最適化により、OceanBaseデータベースは従来のデータベースのようにデータブロック全体を解析するオーバーヘッドを回避し、メモリベースのデータベースに匹敵する性能を実現しています。さらに、ベースラインデータは読み取り専用であり、内部では連続ストレージ方式を採用しているため、OceanBaseデータベースは比較的過激な圧縮アルゴリズムを使用できます。これにより、高い圧縮率を実現しつつクエリ性能に影響を与えず、コストを大幅に削減できます。
古典的なデータベースの長所を取り入れた上で、OceanBaseデータベースはより汎用的なLSM-Treeアーキテクチャのリレーショナルデータベースストレージエンジンを提供し、以下の特徴を備えています:
低コスト:LSM-Treeのデータ書き込み後は更新されない特性を活用し、独自の行列混合エンコーディングと汎用圧縮アルゴリズムを組み合わせることで、OceanBaseデータベースのデータストレージ圧縮率は従来のデータベースに比べて10倍以上向上しています。
使いやすさ:他のLSM-Treeデータベースとは異なり、OceanBaseデータベースはアクティブトランザクションのディスクフラッシュをサポートすることで、ユーザーの大規模・長時間トランザクションの正常な実行やロールバックを保証し、多段階のメジャーコンパクションとダンプメカニズムにより、性能とスペースの最適なバランスを実現します。
高性能:一般的なポイントクエリに対しては、OceanBaseデータベースは多段階のキャッシュ加速を提供し、極めて低い応答遅延を保証します。範囲スキャンに対しては、ストレージエンジンがデータエンコーディングの特性を活用してクエリフィルタ条件の計算を下位に押し下げることをサポートし、ネイティブなベクトル化サポートを提供します。
高信頼性:全リンクのデータ検証に加え、ネイティブ分散型の利点を活用し、OceanBaseデータベースはグローバルメジャーコンパクション時にマルチレプリカ比較および主表とインデックス表の比較検証を行うことで、ユーザーデータの正確性を保証します。同時に、バックグラウンドスレッドによる定期的なスキャンを提供し、サイレントエラーを回避します。
ストレージエンジンの機能
機能モジュールによる分類では、OceanBaseデータベースのストレージエンジンは大まかに以下の部分に分けられます。
データストレージ
データの構成
他のLSMツリー型データベースと同様に、OceanBaseデータベースもデータをメモリ上の増分データ(MemTable)と静的データ(SSTable)の2つの階層に分けています。SSTableは読み取り専用であり、一度生成されると変更されることはなく、ディスクに格納されます。MemTableは読み書きが可能で、メモリ上に格納されます。データベースのDML操作である挿入、更新、削除などは、まずMemTableに書き込まれ、MemTableが一定のサイズに達すると、ディスクに転送されてSSTableとなります。
また、OceanBaseデータベースでは、SSTableはさらにMini SSTable、Minor SSTable、Major SSTableの3種類に細分化されます。MemTableはMini Compactionによってデータをディスク上のMini SSTableに転送します。複数のMini SSTableが一定のしきい値に達すると、Minor Compactionがトリガーされ、Mini SSTableまたはMinor SSTableになります。そして、OceanBaseデータベース特有の日次マージが開始されると、各パーティションの元のベースラインSSTable(Major SSTable)とすべてのMini SSTableおよびMinor SSTableが統合され、新しいMajor SSTableが作成されます。
ストレージ構造
OceanBaseデータベースでは、各パーティションの基本ストレージ単位は個々のSSTableであり、すべてのストレージの基本粒度はマクロブロックです。データベース起動時、データファイル全体を2MBの固定長でマクロブロックに分割します。各SSTableは、実質的には複数のマクロブロックの集合です。
各マクロブロック内部はさらに複数のマイクロブロックに分割されます。マイクロブロックの概念は従来のデータベースのページやブロックの概念と似ていますが、LSMツリーの特性を活かして、OceanBaseデータベースのマイクロブロックは圧縮されて長さが可変になっています。マイクロブロックの圧縮前のサイズは、テーブル作成時に指定する
block_sizeで決定できます。マイクロブロックは、ユーザーが指定したストレージ形式に応じて、encoding形式またはflat形式で保存されます。encoding形式のマイクロブロックでは、内部データが行と列の混合モードで保存されます。flat形式のマイクロブロックでは、すべてのデータ行が平铺されて保存されます。
圧縮エンコード
OceanBaseデータベースは、ユーザーテーブルが指定した形式に基づいて、マイクロブロック内のデータをそれぞれエンコードおよび圧縮します。ユーザーテーブルでencodingが有効になっている場合、各マイクロブロック内のデータは列単位で別々にエンコードされます。エンコードルールには、辞書/ラン/定数/差分などが含まれます。各列の圧縮が終了すると、さらに複数列に対して列間等値/部分文字列などのルールでエンコードが行われます。エンコードにより、データの大幅な圧縮が可能になるだけでなく、抽出された列内の特徴情報により、その後のクエリ速度もさらに向上します。
エンコード圧縮後、OceanBaseデータベースは、ユーザーが指定した汎用圧縮アルゴリズムを用いてマイクロブロックデータを無損失圧縮することもサポートしており、データ圧縮率をさらに向上させることができます。
ダンプとマージ
ダンプ
ダンプには2つのプロセスが含まれます:Mini CompactionとMinor Compactionです。メモリ内のMemTableのサイズが一定のしきい値を超えると、MemTable内のデータをディスク上のMini SSTableに転送してメモリを解放する必要があります。このプロセスをMini Compactionと呼びます。ユーザーデータの書き込みに伴い、Mini SSTableの数が増え続けると、Mini SSTableの数が一定のしきい値を超えると、バックグラウンドで自動的にMinor Compactionがトリガーされます。
マージ
マージ、すなわちMajor Compactionは、OceanBaseデータベースでは日次マージとも呼ばれ、概念は他のLSMツリー型データベースとは若干異なります。その名の通り、この概念が生まれた当初は、毎日午前2時頃にクラスタ全体で一括してCompactionを行うことを想定していました。マージは通常、各テナントのRSが書き込み状況やユーザー設定に基づいてスケジュールを開始します。各テナントの各マージでは、グローバルなスナップショットポイントが選択され、テナント内のすべてのパーティションがこのスナップショットポイントのデータを用いてMajor Compactionを行います。このように、毎回のマージではテナントのすべてのデータがこの統一されたスナップショットポイントに基づいて対応するSSTableが生成されます。この仕組みにより、ユーザーは定期的に増分データを統合し、読み取り性能を向上させるだけでなく、自然なデータ検証ポイントも提供されます。グローバルな一致する時点を通じて、OceanBaseデータベースは内部でマルチレプリカや主表・インデックス表に対して多次元的な物理的データ検証を行うことができます。
クエリの読み書き
挿入
OceanBaseデータベースでは、すべてのデータテーブルはインデックスクラスタテーブルと見なすことができます。主キーのないヒープテーブルであっても、内部では隠れた主キーが維持されます。そのため、ユーザーがデータを挿入する際には、新しいユーザーデータをMemTableに書き込む前に、現在のデータテーブルに同じデータ主キーが既に存在するかどうかを確認する必要があります。この重複する主キーのクエリ性能を高速化するため、各SSTableに対して、バックグラウンドスレッドが異なるマクロブロックの重複頻度に応じて、Bloomfilterの構築を非同期でスケジュールします。
更新
LSM-Treeデータベースとして、OceanBaseデータベースにおける各更新も新しい行データの挿入となります。Clogとは異なり、MemTableで更新され書き込まれるデータには、更新される列の新しい値と対応する主キー列のみが含まれます。つまり、更新される行には必ずしもテーブルのすべての列のデータが含まれるわけではありません。継続的なバックグラウンドCompactionの動作により、これらの増分更新が絶えず統合され、ユーザークエリが高速化されます。
削除
更新と同様に、削除操作も元のデータに直接作用するのではなく、削除される行の主キーを用いて新しい行データを書き込み、行ヘッダーマーカーで削除アクションを示します。大量の削除操作はLSM-Treeデータベースにとって好ましくありません。これにより、データ範囲が完全に削除された後でも、データベースはその範囲内のすべての削除マーク行を反復処理し、統合後に初めて削除状態が確定します。このようなシナリオに対処するため、OceanBaseデータベースは固有の範囲削除マーカーロジックを提供し、このような状況を回避します。また、ユーザーが明示的にテーブルモードを指定することもサポートしており、特殊なダンプメジャーコンパクション方式を通じて、これらの削除行を事前に回収し、クエリを高速化することができます。
クエリ
増分更新の戦略により、各行データをクエリする際には、バージョンの新旧順にすべてのMemTableおよびSSTableを走査し、各テーブルの対応する主キーのデータを統合して返却する必要があります。データアクセスプロセスでは、必要に応じてCacheを活用して高速化され、大規模クエリシナリオでは、SQL層がフィルタ条件をストレージ層にプッシュダウンし、ストレージデータの特性を活用して低レイヤーでの高速フィルタリングを実行します。また、ベクトル化シナリオにおけるバッチ計算と結果返却もサポートしています。
マルチレベルキャッシュ
パフォーマンス向上のため、OceanBaseデータベースはマルチレベルのキャッシュシステムをサポートしています。データマイクロブロックに対するBlock Cache、各SSTableに対するRow Cache、クエリ統合結果に対するFuse Row Cache、挿入時のNULLチェック用Bloomfilter cacheなどがあります。同一テナント内のすべてのキャッシュはメモリを共有しており、MemTableへの書き込み速度が速すぎる場合、現在の各種キャッシュオブジェクトから柔軟にメモリを割り当てて書き込みに使用することができます。
データ検証
金融級リレーショナルデータベースとして、OceanBaseデータベースは常にデータ品質とセキュリティを最優先に考えています。データ保存に関わる全データリンクの各段階でデータ検証保護を追加し、同時にマルチレプリカストレージの固有の利点を活用して、レプリカ間のデータ検証を追加し、全体のデータ一貫性をさらに検証します。
論理検証
一般的なデプロイメントモードでは、OceanBaseデータベースの各ユーザーテーブルには複数のレプリカが存在します。テナントの日次メジャーコンパクション時には、すべてのレプリカがグローバル統一のスナップショットバージョンに基づいて一貫したベースラインデータを生成します。この特性を活用して、メジャーコンパクション完了時には、すべてのレプリカのデータのチェックサムを比較し、完全な一致性を保証します。さらに、ユーザーテーブルのインデックスに基づいて、インデックス列のチェックサムも比較し、最終的にユーザーに返却されるデータがプログラムの内在的な問題で誤っていないことを確保します。
物理検証
データストレージについて、OceanBaseデータベースはデータストレージの最小I/O粒度であるマイクロブロックから始め、各マイクロブロック/マクロブロック/SSTable/パーティションに対応するチェックサムを記録しています。データを読み取るたびにデータ検証が実行されます。低レイヤーのストレージハードウェアの問題を防ぐため、ダンプメジャーコンパクションでデータマクロブロックに書き込む際にも、書き込み直後に再度データ検証が行われます。最後に、各Serverのバックグラウンドには定期的なデータ巡回スレッドがあり、全体的なデータをスキャンして検証し、ディスクのサイレントデータ損失を早期に発見します。