


概要
OceanBaseデータベースは、シェアードナッシング(Shared-Nothing、SN)モードと共有ストレージ(Shared-Storage、SS)モードの2種類のデプロイメントモードをサポートしています。
シェアードナッシングモード
シェアードナッシング(SN)モードでは、各ノードは完全に対等であり、各ノードには独自のSQLエンジン、ストレージエンジン、トランザクションエンジンが搭載されています。一般的なPCサーバーで構成されるクラスタ上で動作し、高い拡張性、可用性、パフォーマンス、低コスト、主要なデータベースとの高い互換性といったコア機能を備えています。
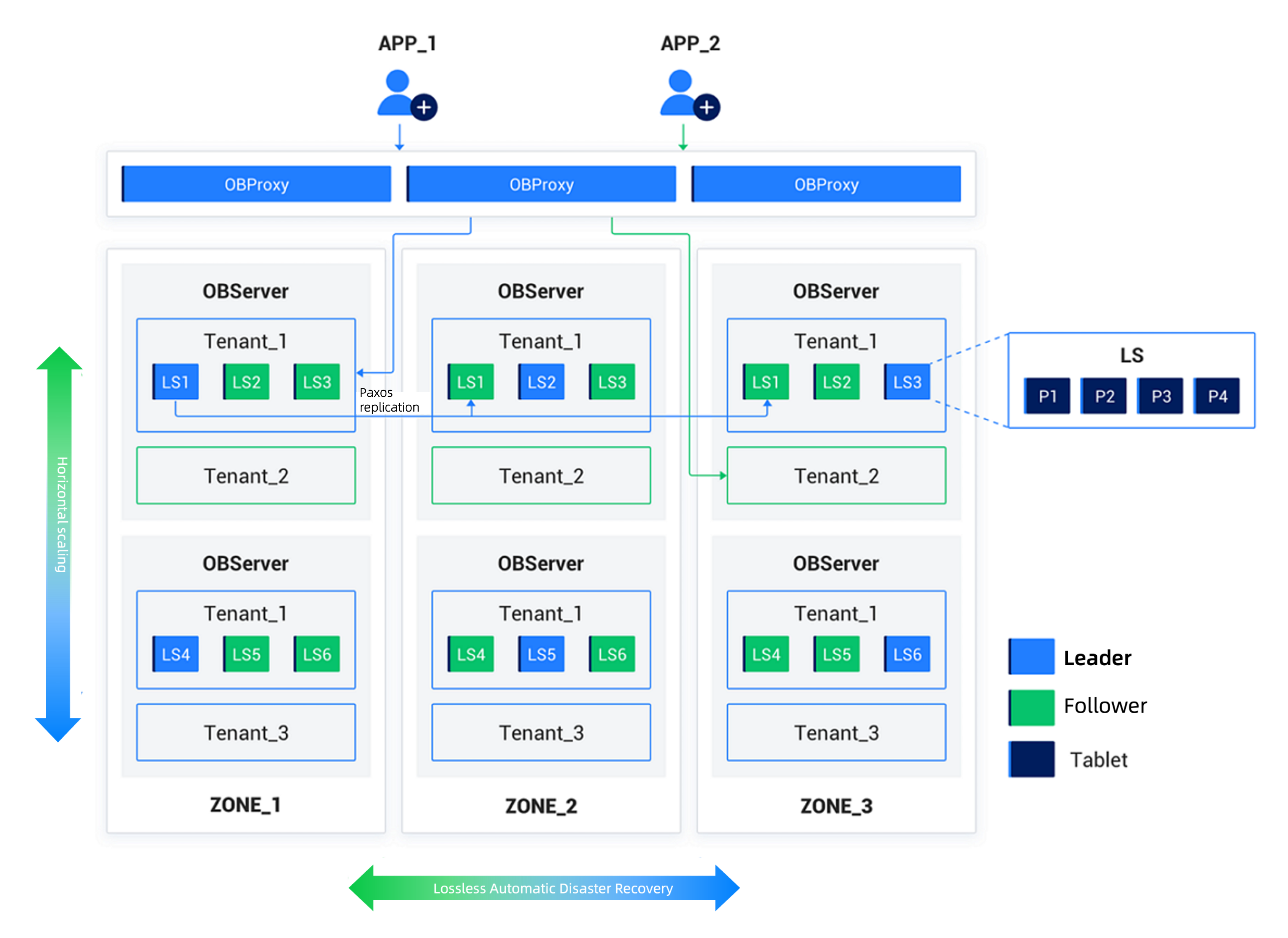
OceanBaseデータベースは汎用サーバーハードウェアを使用し、ローカルストレージに依存します。分散デプロイメントで使用される複数のサーバーも対等であり、特別なハードウェア要件はありません。OceanBaseデータベースの分散データベース処理はShared Nothingアーキテクチャを採用しており、データベース内のSQL実行エンジンは分散実行能力を備えています。
OceanBaseデータベースのサーバー上では、observerという名前の単一プロセスプログラムがデータベースの実行インスタンスとして動作し、ローカルのファイルを使用してデータとトランザクションRedoログを格納します。
OceanBaseクラスタのデプロイメントでは、ゾーン(Zone)を設定する必要があります。各ゾーンは複数のサーバーで構成されています。ゾーンは論理的な概念であり、クラスタ内でハードウェアの可用性が類似したノードのグループを表します。デプロイメントモードによって、その意味合いは異なります。例えば、クラスタ全体が単一のデータセンター(IDC)内にデプロイされている場合、1つのゾーンのノードは同じラックや同じスイッチに属することができます。クラスタが複数のデータセンターに分散されている場合、各ゾーンは1つのデータセンターに対応することができます。
ユーザーが保存するデータは、分散クラスタ内で複数のレプリカとして保存することができ、障害回復や読み取り負荷の分散に利用できます。同一のテナント内のデータは1つのゾーン内に1つのレプリカしか存在せず、異なるゾーンには同一データの複数のレプリカを保存することができます。レプリカ間のデータ一貫性はPaxosプロトコルによって保証されます。
OceanBaseデータベースは組み込みのマルチテナント機能を備えており、各テナントは独立したデータベースインスタンスと見なすことができます。各テナントはテナントレベルで自身のデータ分散戦略、レプリカタイプ、レプリカ数を設定できます。各テナント間のCPU、メモリ、I/Oなどのリソースは相互に隔離されています。
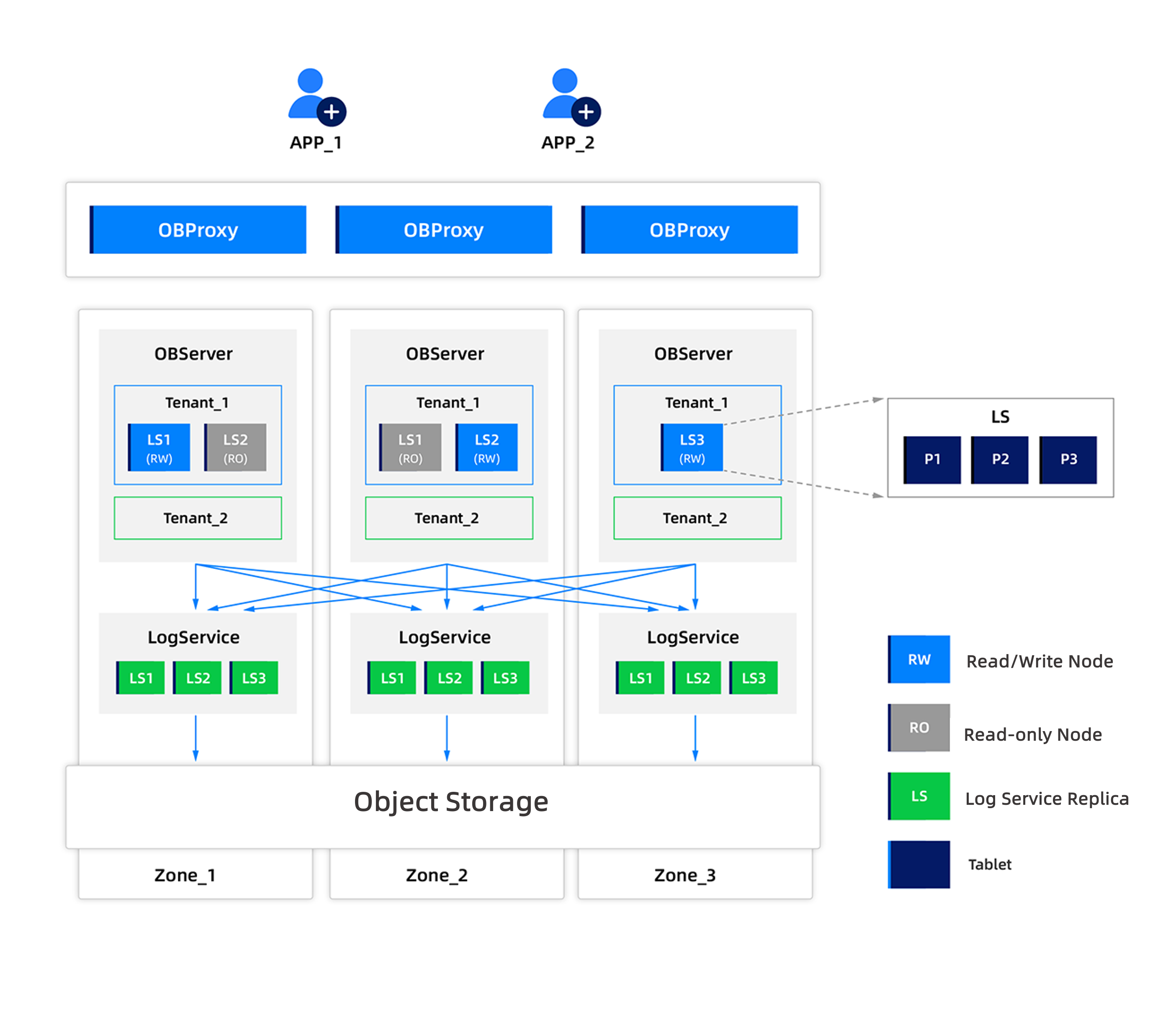
共有ストレージモード
共有ストレージ(SS)モードでは、システムはストレージとコンピューティングを分離したアーキテクチャを採用しています。各テナントは共有オブジェクトストレージ上にデータとログを1セット保存し、各テナントはノードのローカルストレージ上にホットデータとログをキャッシュします。
OceanBaseデータベースのデプロイメントアーキテクチャの詳細については、システムアーキテクチャを参照してください。
OceanBaseクラスタのデータベースインスタンス内部では、異なるコンポーネントが相互に協力して動作します。これらのコンポーネントは、基盤から順にマルチテナント層、ストレージ層、レプリケーション層、バランシング層、トランザクション層、SQL層、アクセス層で構成されています。
マルチテナント層
大規模な複数の業務データベースのデプロイメント管理を簡素化し、リソースコストを削減するために、OceanBaseデータベースは独自のマルチテナント機能を提供しています。1つのOceanBaseクラスタ内では、互いに隔離されたデータベース「インスタンス」を多数作成でき、これをテナントと呼びます。アプリケーションの観点から見ると、各テナントは独立したデータベースインスタンスと同等です。さらに、各テナントはMySQL互換モードまたはOracle互換モードを選択できます。アプリケーションがMySQLテナントに接続すると、テナント内でユーザーやデータベースを作成でき、独立したMySQLデータベースと同じ使用感覚を得られます。同様に、アプリケーションがOracleテナントに接続すると、テナント内でスキーマを作成したりロールを管理したりでき、独立したOracleデータベースと同じ使用感覚を得られます。新しいクラスタを初期化すると、最初にsysという名前の特殊なテナント、つまりシステムテナントが存在します。システムテナントにはクラスタのメタデータが保存されており、MySQL互換モードのテナントです。
テナントのリソースを隔離するために、各observerプロセス内には、異なるテナントに属する複数の仮想コンテナを配置できます。これをリソースユニット(UNIT)と呼びます。リソースユニットにはCPUとメモリリソースが含まれます。各テナントの複数ノード上のリソースユニットが1つのリソースプールを形成します。
ストレージ層
ストレージ層は、テーブルまたはパーティション単位でデータの格納とアクセスを提供し、各パーティションにはデータを格納するためのTablet(シャード)が対応します。ユーザー定義の非パーティションテーブルもTabletに対応します。
Tabletの内部は階層型のストレージ構造であり、合計4層から構成されています:MemTable、L0層のMini SSTable、L1層のMinor SSTable、およびMajor SSTableです。DML操作(挿入、更新、削除など)はまずMemTableに書き込まれ、MemTableが一定のサイズに達するとディスクにダンプされ、L0層のMini SSTableとなります。L0層のMini SSTableの数がしきい値に達すると、複数のL0層のMini SSTableが1つのL1層のMinor SSTableにメジャーコンパクションされます。毎日設定された業務のオフピーク時間帯には、システムはすべてのMemTable、L0層のMini SSTable、およびL1層のMinor SSTableを1つのMajor SSTableにメジャーコンパクションします。
各SSTableは、サイズが2MBの固定長マクロブロックで構成されており、各マクロブロック内部は複数の可変長マイクロブロックで構成されています。
Major SSTableのマイクロブロックは、メジャーコンパクション処理中にエンコーディング方式による形式変換を経て、マイクロブロック内のデータは列単位でそれぞれエンコードされます。エンコードルールには、辞書、ラン長、定数、または差分などが含まれます。各列の圧縮が終了した後、さらに複数列に対して列間の等値や部分文字列などのルールエンコードが行われます。このエンコードによりデータは大幅に圧縮されるとともに、抽出された列内の特徴情報が後続のクエリ処理の速度をさらに向上させます。
エンコード圧縮後、ユーザーが指定した汎用圧縮アルゴリズムを用いて無損失圧縮を行うことも可能で、データ圧縮率をさらに高めることができます。
レプリケーション層
スナップショットモード
スナップショット(SN)モードでは、レプリケーション層はログストリーム(LS、Log Stream)を使用してマルチレプリカ間で状態を同期します。各Tabletには必ず1つのログストリームが対応し、1つのログストリームには複数のTabletが対応します。DML操作によってTabletに書き込まれたデータによって生成されるRedoログは、ログストリームに永続化されます。ログストリームの複数のレプリカは異なるアベイラビリティゾーンに分散配置され、複数のレプリカ間でコンセンサスアルゴリズムが維持されます。その中から1つのレプリカをリーダーレプリカとして選出し、他のレプリカはすべてフォロワーレプリカとなります。TabletのDMLおよび強整合性クエリは、対応するログストリームのリーダーレプリカ上でのみ実行されます。
通常、各テナントは各マシン上において1つのログストリームのリーダーレプリカしか持たず、他の複数のログストリームのフォロワーレプリカを持つ場合があります。テナントの総ログストリーム数は、Primary ZoneとLocalityの設定に依存します。
ログストリームは改良されたPaxosプロトコルを使用してRedoログを本サーバー上に永続化すると同時に、ネットワークを介してログストリームのフォロワーレプリカに送信します。フォロワーレプリカはそれぞれの永続化を完了した後にリーダーレプリカに応答し、リーダーレプリカは過半数の派生レプリカが正常に永続化したことを確認した後に、対応するRedoログの永続化が成功したことを確認します。フォロワーレプリカはRedoログの内容をリアルタイムで再生し、自身の状態がリーダーレプリカと一致することを保証します。
ログストリームのリーダーレプリカがリーダー(Leader)に選出されると、テナントリース(Lease)を取得します。正常に動作するリーダーレプリカは、リース期間内に選挙プロトコルを通じてリース期間を延長し続けます。リーダーレプリカはテナントリースが有効な間のみリーダーとしての業務を実行し、このリースメカニズムによりデータベースの異常処理能力が保証されます。
レプリケーション層はサーバー障害に自動的に対応し、データベースサービスの継続的な可用性を保証します。過半数未満のフォロワーレプリカが存在するサーバーに障害が発生した場合でも、すなわち過半数以上のレプリカが正常に動作している場合は、データベースサービスは影響を受けません。リーダーレプリカが存在するサーバーに問題が発生した場合、そのテナントリースは更新されません。テナントリースが失効した後、他のフォロワーレプリカが選挙プロトコルにより新しいリーダーを選出し、新しいテナントリースを付与することで、データベースサービスを復旧できます。
共有ストレージモード
オブジェクトストレージを基盤とした共有ストレージアーキテクチャに基づき、さらにクラウドネイティブ(Cloud Native)向けのデータベースアーキテクチャを設計し、ログ(ログサービス)とコンピューティング(コンピューティングノード、読み書きノードと読み取り専用ノードに分類)を分離しました。共有ストレージ(SS)モードでは、スナップショット(SN)モードと比較して、データベースのログサービスが抽出され、一連の独立した高性能、高可用性、強整合性を備え、ログアクセス特性に極めて最適化された分散ストレージシステムによってサービスが提供されます。
このアーキテクチャでは、ログストリーム(Log Stream、LS)がログサービスのレプリカ間で整合性プロトコルを通じてログを同期し、データの永続性を保証します。ログサービスのレプリカ数はコンピューティングノード数と分離されています。コンピューティングノードの数は可用性(availability)を保証し、ログサービスノードの数は高可用性下での永続性(durability)を保証します。
読み書きノード(RW)がリーダー(Leader)に選出されると、同様にテナントリース(Lease)を取得します。これはSNモードと一致します。選挙が完了すると、読み書きノード(RW)はPaxosプロトコルを通じて、ログサービスの複数のレプリカに同時に永続化を完了し、過半数のログサービスレプリカからの応答を受信した後に過半数が完了したことを保証します。読み取り専用ノード(RO)は、最新のログサービスレプリカから過半数が完了したログを読み取り、ローカルでデータを再生します。
ログサービスもまた、サーバー障害に自動的に対応し、データベースサービスの継続的な可用性を保証します。ログサービスレプリカの半数未満が存在するサーバーに障害が発生した場合でも、すなわち過半数以上のレプリカが正常に動作している場合は、データベースサービスは影響を受けません。これにより、高可用性下での永続性(durability)が実現されます。同時に、SSモード下のコンピューティングノードはログサービスと共有オブジェクトストレージに依存して直接起動・復旧できるため、コンピューティングノードの過半数に依存しなくなりました。冗長なコンピューティングノードは、データベースの高可用性を保証するだけでなく、読み書き分離機能も提供します。
バランシング層
テーブルの新規作成やパーティションの追加時、システムはバランシングの原則に従って適切なログストリームを選択し、Tabletを作成します。テナントの属性が変更されたり、新しいマシンリソースが追加されたり、長時間の使用後にTabletが各マシン上で均等に分散されなくなった場合、バランシング層はログストリームの分割と統合操作を行い、このプロセスでログストリームレプリカの移動を組み合わせることで、データとサービスを複数のサーバー間で再び均等に配分します。
テナントの拡張操作により、より多くのサーバーリソースを獲得した場合、バランシング層はテナント内の既存のログストリームを分割し、適切な数のTabletを新しいログストリームに一緒に分割します。その後、新しいログストリームを新規に追加されたサーバーに移行することで、拡張後のリソースを最大限に活用します。テナントの縮小操作を行う場合、バランシング層は縮小対象のサーバー上のログストリームを他のサーバーに移行し、他のサーバー上の既存のログストリームと統合することで、マシンのリソース使用量を削減します。
データベースの長期的な使用に伴い、ユーザーが継続的にテーブルを作成または削除し、より多くのデータを書き込むことで、たとえサーバーリソースの数が変わらなくても、元々均等だった状況が崩れる可能性があります。最も一般的なケースは、ユーザーが一括でテーブルを削除した後、削除されたテーブルが元々特定のマシンに集中していた場合です。削除後、これらのマシン上のTablet数が減少するため、他のマシン上のTabletをこれらの少ないマシンに均等に分散させる必要があります。バランシング層は定期的にバランシング計画を生成し、Tabletが多いサーバー上のログストリームから一時ログストリームを分割し、移動が必要なTabletを含めます。一時ログストリームは目的サーバーに移行した後、目的サーバー上のログストリームと統合され、バランシングの効果を達成します。
トランザクション層
トランザクション層は、単一のログストリームおよび複数のログストリームにおけるDML操作のコミットの原子性を保証するとともに、並行するトランザクション間のマルチバージョン分離機能も保証します。
原子性
あるログストリーム上のトランザクションによる変更は、たとえ複数のTabletに関わる場合でも、ログストリームのWrite-Aheadログによりトランザクションコミットの原子性が保証されます。トランザクションの変更が複数のログストリームにまたがる場合、各ログストリームはそれぞれ独自のWrite-Aheadログを生成して永続化します。トランザクション層は、最適化された2フェーズコミットプロトコルにより、トランザクションコミットの原子性を保証します。
複数のログストリームに関わるトランザクションがコミットを開始すると、そのうちの1つのログストリームを2フェーズコミットのコーディネーターとして選択します。コーディネーターは、トランザクションによって変更されたすべてのログストリームと通信し、Write-Aheadログが永続化されているかどうかを確認します。すべてのログストリームで永続化が完了すると、トランザクションはコミット状態に入ります。その後、コーディネーターはすべてのログストリームに対して、そのトランザクションのCommitログを書き込みます。これはトランザクションの最終的なコミット状態を示します。レプリカからの再生やデータベースの再起動時には、既にコミット済みのトランザクションは、各ログストリームのトランザクション状態を決定するためにこのCommitログを参照します。
ダウンタイムからの再起動シナリオでは、ダウンタイム前に未完了だったトランザクションについて、Write-Aheadログは書き込まれているものの、まだCommitログが書き込まれていない場合が発生します。各ログストリームのWrite-Aheadログには、そのトランザクションのすべてのログストリームリストが含まれているため、この情報を用いてどのログストリームがコーディネーターであるかを再判定し、コーディネーターの状態を復元して、トランザクションが最終的なCommitまたはAbort状態に達するまで、再度2フェーズコミットプロトコルを進めることができます。
分離性
GTS(Global Timestamp Service)サービスは、テナント内で連続的に増加するタイムスタンプを生成するサービスであり、マルチレプリカによって可用性を保証します。その基盤となるメカニズムは、前述のレプリケーション層で説明したログストリームレプリカ同期メカニズムと一致しています。
各トランザクションがコミットされる際、GTSからタイムスタンプを取得し、それをトランザクションのコミットバージョン番号としてログストリームのWrite-Aheadログに永続化します。トランザクション内で変更されたすべてのデータは、このコミットバージョン番号でマークされます。
各ステートメントの開始時(Read Committed分離レベルの場合)または各トランザクションの開始時(Repeatable ReadおよびSerializable分離レベルの場合)、GTSからタイムスタンプを取得し、それをステートメントまたはトランザクションの読み取りバージョン番号とします。データを読み取る際には、自身より大きいトランザクションバージョン番号をスキップし、現在の読み取りバージョン番号より小さいすべてのバージョン番号の中で最大のものを選択します。この方法により、読み取り操作に対して統一されたグローバルなデータスナップショットが提供されます。
SQLレイヤー
SQLレイヤーは、ユーザーのSQLリクエストを1つまたは複数のTabletへのデータアクセスに変換します。
SQLレイヤーのコンポーネント
SQLレイヤーがリクエストを処理する実行フローは、Parser、Resolver、Transformer、Optimizer、Code Generator、Executorです。その中で:
Parserは、構文解析を担当します。ユーザーのSQLを「Token」に分割し、事前に設定された文法ルールに基づいてリクエスト全体を解析し、構文木(Syntax Tree)に変換します。
Resolverは、意味解析を担当します。データベースのメタ情報に基づき、SQLリクエスト内のTokenを対応するオブジェクト(例:データベース、テーブル、列、インデックスなど)に翻訳し、生成されたデータ構造をStatement Treeと呼びます。
Transformerは、論理的な書き換えを担当します。内部のルールやコストモデルに基づき、SQLをそれと等価な他の形式に書き換え、後続のオプティマイザーに提供してさらなる最適化を行わせます。
Transformerの動作方法は、元のStatement Treeに等価変換を施し、変換結果も依然としてStatement Treeであることです。
Optimizer(オプティマイザー)は、SQLリクエストに対して最適な実行計画を生成します。SQLリクエストの意味、オブジェクトデータの特性、オブジェクトの物理的配置など、多方面の要因を総合的に考慮し、アクセスパスの選択、結合順序の選択、結合アルゴリズムの選択、分散計画の生成などの問題を解決し、最終的に実行計画を生成します。
Code Generator(コードジェネレーター)は、実行計画を実行可能なコードに変換しますが、最適化の選択は行いません。
Executor(エグゼキューター)は、SQLの実行プロセスを開始します。
標準的なSQLプロセスに加えて、SQLレイヤーにはPlan Cache機能もあり、過去の実行計画をメモリにキャッシュし、後続の実行でこの計画を繰り返し実行することができます。これにより、重複するクエリの最適化処理を回避できます。Fast-parserモジュールと組み合わせることで、構文解析のみを用いてテキスト列を直接パラメータ化し、パラメータ化後のテキストと定数パラメータを取得することで、SQLが直接Plan Cacheにヒットし、頻繁に実行されるSQLを高速化します。
複数の計画
SQLレイヤーの実行計画は、ローカル、リモート、分散の3種類に分けられます。ローカル実行計画は、自身のサーバーのデータのみにアクセスします。リモート実行計画は、ローカルではない別のサーバーのデータのみにアクセスします。分散計画は、1台以上のサーバーのデータにアクセスし、実行計画は複数のサブ計画に分割されて複数のサーバーで実行されます。
SQLレイヤーの並列実行機能は、実行計画を複数の部分に分解し、複数の実行スレッドによって実行することで、一定のスケジューリング手法を通じて実行計画の並列処理を実現します。並列実行は、サーバーのCPUおよびI/O処理能力を最大限に活用し、単一クエリの応答時間を短縮できます。並列クエリ技術は、分散実行計画だけでなく、ローカル実行計画にも適用できます。
アクセス層
OceanBaseデータベースプロキシODP(OceanBase Database Proxy、別名OBProxy)は、OceanBaseデータベースのアクセス層であり、ユーザーのリクエストを適切なOceanBaseデータベースインスタンスに転送して処理を行う役割を担います。
ODPは独立したプロセスインスタンスであり、OceanBaseデータベースインスタンスとは独立してデプロイされます。ODPはネットワークポートをリッスンし、MySQLネットワークプロトコルに互換性があり、MySQLドライバを使用するアプリケーションがOceanBaseデータベースに直接接続することをサポートします。
ODPは、OceanBaseクラスタのテナントおよびデータ分布情報を自動的に検出できます。プロキシする各SQL文について、その文がアクセスしようとするデータを可能な限り特定し、その文をデータが存在するサーバー上のOceanBaseデータベースインスタンスに直接転送します。
ODPには2種類のデプロイ方法があります。1つはOBServerノードとは別にデプロイする方法(別のマシンにデプロイするか、アプリケーションと同一のマシンにデプロイする)であり、もう1つはOBServerノードが存在するマシンにデプロイする方法です。ODPプロキシをデプロイすると、ユーザーのすべてのリクエストはODPから適切なOceanBaseデータベースサーバーに送信されます。ユーザーはネットワーク負荷分散サービスを利用して、複数のODPを1つのエントリアドレスに集約し、アプリケーションにサービスを提供することができます。
ODPのデプロイ方法の詳細については、ODP公式ドキュメントを参照してください。