背景
情報が溢れる現代では、ユーザーは膨大なデータの中から必要な情報を迅速に検索することが求められています。例えば、オンライン文献データベース、eコマースプラットフォームの商品カタログ、そして日々増加し続けるマルチメディアコンテンツライブラリなど、効率的な検索システムが必要であり、ユーザーが興味を持つコンテンツを素早く特定することが求められています。データ量が急増する中、従来のキーワードベースの検索手法では、ユーザーの検索精度と速度に対する要求を満たせなくなりました。そこで登場したのがベクトル検索技術です。この技術は、テキスト、画像、音声など異なる種類のデータを数学的なベクトルに符号化し、ベクトル空間上で検索を行います。この方法により、システムはデータの深層的な意味情報を捉えることができ、より正確で効率的な検索結果を提供できます。
本記事では、OceanBaseのベクトル検索機能を活用して、ドキュメントインテリジェントアシスタントを構築します。
ドキュメントインテリジェントアシスタントのアーキテクチャ
ドキュメントインテリジェントアシスタントは、ドキュメントをベクトル形式でOceanBaseデータベースに一括保存します。ユーザーがUIインターフェースを通じて質問すると、プログラムはBGE-M3モデルを使用して質問内容をベクトルに埋め込み、データベース内で類似ベクトルを検索します。類似ベクトルに対応するドキュメント内容を取得した後、アプリケーションはそれらをユーザーの質問と共にLLMに送信し、LLMは提供されたドキュメントに基づいてより正確な回答を生成します。

前提条件
OceanBase V4.4.0以降のバージョンをデプロイし、MySQLモードのテナントを作成していること。OceanBaseクラスタのデプロイに関する詳細は、デプロイの概要を参照してください。
作成したMySQLモードのテナントに挿入およびクエリの権限が付与されていること。権限設定の詳細については、直接権限付与を参照してください。
データベースを作成済みであること。データベースの作成に関する詳細は、データベースの作成を参照してください。
データベースでベクトル検索機能が有効になっていること。ベクトル検索機能の詳細については、SQLを使用した高速なベクトル検索を参照してください。
obclient> ALTER SYSTEM SET ob_vector_memory_limit_percentage = 30;Python 3.11以降のバージョンをインストールしていること。
Poetryをインストールしていること:
python3 -m ensurepip python3 -m pip install poetry
ステップ1:LLMプラットフォームアカウントの登録
Alibaba Cloud Model Studioアカウントに登録し、モデルサービスを有効化してAPIキーを取得します。
注意
Alibaba Cloud Model Studioの大規模言語モデルサービスを有効化するには、第三者プラットフォームに移動して手続きを完了する必要があります。この操作は第三者プラットフォームの料金規則に従い、該当する費用が発生する場合があります。続行する前に、その公式Webサイトにアクセスするか関連ドキュメントを確認し、料金体系を確認して同意してください。同意しない場合は、操作を続けないでください。
注意
このチュートリアルでは、Qwen LLMを例にQ&Aボットの構築方法を紹介しますが、他のLLMを使用して構築することも可能です。他のLLMを選択する場合は、.env ファイル内の API_KEY、LLM_BASE_URL、LLM_MODEL を更新する必要があります。


ステップ2:AIアシスタントを構築する
コードリポジトリのクローン
git clone https://github.com/ob-labs/ChatBot.git
cd ChatBot
依存関係のインストール
poetry install
環境変数の設定
cp .env.example .env
# Qwenが提供するLLM機能を使用する場合は、API_KEYとOPENAI_EMBEDDING_API_KEYをAlibaba Cloud Bailianコンソールから取得したAPI KEYに更新し、DB_で始まる変数をご自身のデータベース接続情報に更新してファイルを保存してください。
vi .env
データベースへの接続
データベース関連の環境変数の設定が正しく行われているか確認するために、用意されたスクリプトを使用してデータベースへの接続を試すことができます。
bash utils/connect_db.sh
# MySQL接続に無事入ることができれば、環境変数の設定が成功したことを確認できます。
ドキュメントコーパスの準備
このステップでは、OceanBase関連コンポーネントのオープンソースドキュメントリポジトリをクローンし、処理してドキュメントのベクトルデータとその他の構造化データを生成した後、OceanBaseデータベースにデータを挿入します。
ドキュメントリポジトリのクローンと処理
注意
このステップでは、多数のOceanBaseドキュメントをダウンロードおよび処理するため、時間がかかります。
git clone --single-branch --branch V4.3.3 https://github.com/oceanbase/oceanbase-doc.git doc_repos/oceanbase-doc # GitHubリポジトリへのアクセスが遅い場合は、以下のコマンドでGiteeのミラーコピーをクローンできます。 git clone --single-branch --branch V4.3.4 https://gitee.com/oceanbase-devhub/oceanbase-doc.git doc_repos/oceanbase-docドキュメントフォーマットの標準化
OceanBaseのオープンソースドキュメントには、
====と----を用いて見出しを表現しているファイルがあります。このステップでは、それらを標準的な#と##に変換します。# 見出しを標準的なMarkdown形式に変換する poetry run python convert_headings.py \ doc_repos/oceanbase-doc/zh-CN \ドキュメントのベクトル化とOceanBaseデータベースへの挿入
embed_docs.pyスクリプトを提供しています。ドキュメントディレクトリと対応するコンポーネントを指定すると、このスクリプトはディレクトリ内のすべてのmarkdown形式のドキュメントを走査し、長文ドキュメントをスライシングした後、埋め込みモデルを用いてベクトルに変換します。最終的に、ドキュメントのスライス内容、埋め込まれたベクトル、およびスライスのメタ情報(JSON形式、ドキュメントのタイトル、相対パス、コンポーネント名、スライスタイトル、カスケードタイトルを含む)を一緒にOceanBaseの同一テーブルに挿入し、検索用の予備データとして保存します。時間を節約するため、OceanBaseの多数のドキュメントのうち、ベクトル検索に関連する数件のドキュメントのみを処理します。チャットインターフェースを開くと、OceanBaseのベクトル検索機能に関する質問に対して、より正確な回答を得ることができます。
# ドキュメントのベクトルとメタデータを生成する poetry run python embed_docs.py --doc_base doc_repos/oceanbase-doc/zh-CN/640.ob-vector-search
UIチャットインターフェースの起動
以下のコマンドを実行してチャットインターフェースを起動します:
poetry run streamlit run --server.runOnSave false chat_ui.py
端末に表示されたURLにアクセスして、チャットボットアプリケーションの画面を開きます。
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://172.xxx.xxx.xxx:8501
External URL: http://xxx.xxx.xxx.xxx:8501 # ブラウザからアクセス可能なURLです
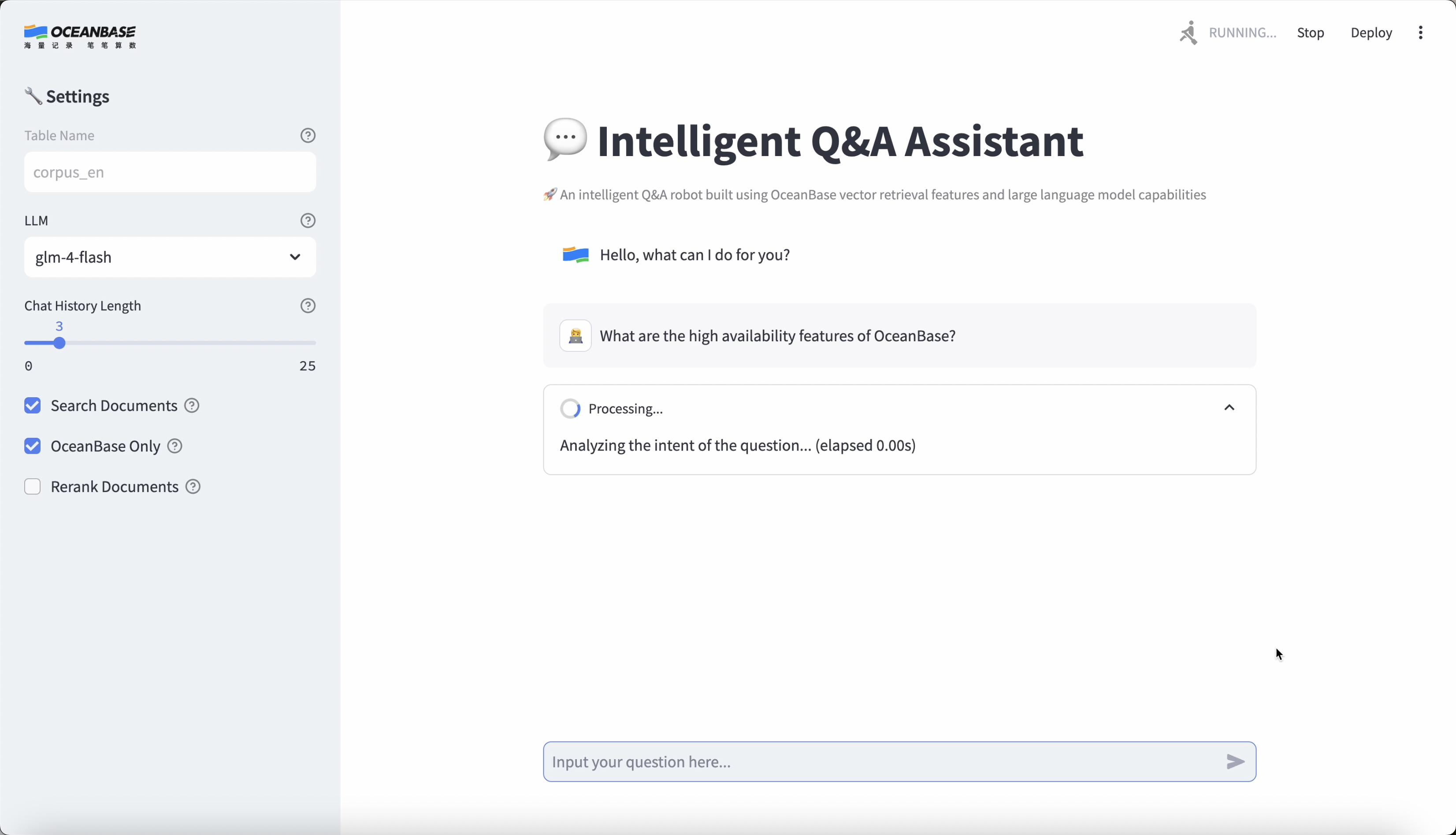
アプリケーションの表示
注意
このアプリケーションはOceanBaseのドキュメントコーパスに基づいて構築されています。OceanBaseに関する質問は、アシスタントにお聞きください。