


本記事では、OceanBaseがサポートするベクトル関数とその使用上の注意点について説明します。
使用上の注意点
- 次元の異なるベクトルデータに対して以下の演算を行うことはできず、
different vector dimensions %d and %dエラーが発生します。 - 結果が浮動小数点数の値域を超えた場合、
value out of range: overflow / underflowエラーが発生します。 - 密ベクトルインデックスは、L2、内積(Inner Product)、コサイン距離をインデックス距離アルゴリズムとしてサポートしています。詳細については、HNSWシリーズインデックスおよびIVFシリーズインデックスを参照してください。
- ベクトルインデックス検索では、このドキュメントで説明している
L2_distance、Cosine_distance、Inner_product、Negative_inner_productの各距離関数に加えて、inner_product_similarity、cosine_similarity、l2_similarityの類似度関数を呼び出すことができます。
注意
類似度関数はV4.4.2 BP1バージョンからサポートされています。
ベクトルインデックスのメモリ設定
OceanBase のベクトル検索では、ob_vector_memory_limit_percentage 設定を使ってベクトルインデックスのメモリを設定します。
V4.4.1 より前のバージョンでは、HNSW/HNSW_SQ/HNSW_BQ ベクトルインデックスを使用する前に、
ob_vector_memory_limit_percentageを手動で設定してベクトル機能を有効にする必要があります。最適な検索パフォーマンスを得るため、値は30に設定することを推奨します。デフォルト値のままだと、ベクトルインデックスにメモリが割り当てられず、インデックス作成時にエラーが発生します。IVF/IVF_PQ インデックスは常駐メモリを必要としないため、このパラメータについては気にする必要はありません。設定例は以下の通りです:ALTER SYSTEM SET ob_vector_memory_limit_percentage = 30;V4.4.1 以降のバージョンでは、ベクトル検索機能はデフォルトで有効になっています。デフォルト値の
0は適応モードを意味し、システムがテナント内のベクトルインデックスデータのメモリ使用率を自動的に調整するため、手動での調整は不要です。- テナントの実メモリが 8GB 以下の場合、この値は自動的に
40に設定されます。 - テナントの実メモリが 8GB を超える場合、この値は自動的に
50に設定されます。
- テナントの実メモリが 8GB 以下の場合、この値は自動的に
距離関数
距離関数は、2つのベクトル間の距離を計算するために使用されます。具体的な計算方法は、使用する距離アルゴリズムによって異なります。
L2_distance
ユークリッド距離は、比較対象のベクトル座標間の距離、つまり基本的には2つのベクトル間の直線距離を表します。ベクトルの座標にピタゴラスの定理を適用して計算します。
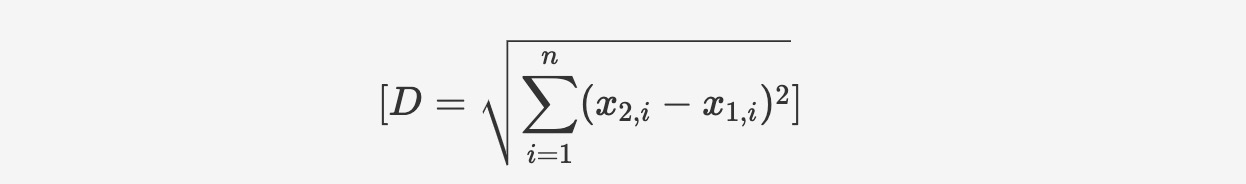
関数の構文は以下のとおりです:
l2_distance(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例:文字列型(例:
'[1,2,3]')。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)型の距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t1(c1 vector(3));
INSERT INTO t1 VALUES('[1,2,3]');
SELECT l2_distance(c1, [1,2,3]), l2_distance([1,2,3],[1,1,1]), l2_distance('[1,1,1]','[1,2,3]') FROM t1;
結果は次のとおりです:
+--------------------------+------------------------------+----------------------------------+
| l2_distance(c1, [1,2,3]) | l2_distance([1,2,3],[1,1,1]) | l2_distance('[1,1,1]','[1,2,3]') |
+--------------------------+------------------------------+----------------------------------+
| 0 | 2.23606797749979 | 2.23606797749979 |
+--------------------------+------------------------------+----------------------------------+
1 row in set
L2_squared
L2 Squared距離は、ユークリッド距離(L2距離)の二乗です。ユークリッド距離の公式から平方根演算を省略しているため、距離の相対的な順序を保ちつつ計算コストを削減できます。計算式は以下のとおりです:
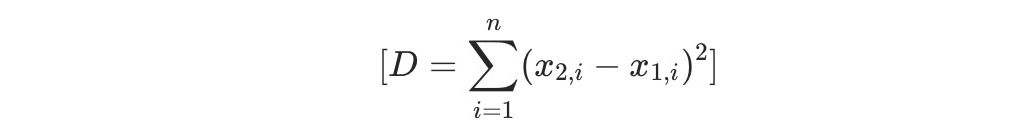
構文は以下のとおりです:
l2_squared(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換可能な他のデータ型もパラメータとして指定できます。例:文字列型(例:
'[1,2,3]')。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)で表される距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t1(c1 vector(3));
INSERT INTO t1 VALUES('[1,2,3]');
SELECT l2_squared(c1, [1,2,3]), l2_squared([1,2,3],[1,1,1]), l2_squared('[1,1,1]','[1,2,3]') FROM t1;
結果は次のとおりです:
+-------------------------+-----------------------------+---------------------------------+
| l2_squared(c1, [1,2,3]) | l2_squared([1,2,3],[1,1,1]) | l2_squared('[1,1,1]','[1,2,3]') |
+-------------------------+-----------------------------+---------------------------------+
| 0 | 5 | 5 |
+-------------------------+-----------------------------+---------------------------------+
1 row in set
L1_distance
マンハッタン距離は、標準座標系における2点間の各軸方向の絶対距離の合計を計算するために使用されます。計算式は以下のとおりです:
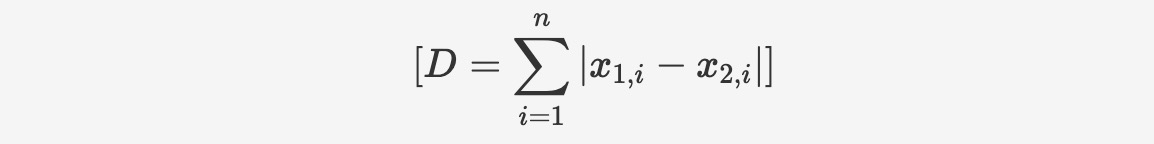
関数の構文は以下のとおりです:
l1_distance(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換可能な他のデータ型もパラメータとして指定できます。例:文字列型(例:
'[1,2,3]')。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)で表される距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t2(c1 vector(3));
INSERT INTO t2 VALUES('[1,2,3]');
INSERT INTO t2 VALUES('[1,1,1]');
SELECT l1_distance(c1, [1,2,3]) FROM t2;
結果は次のとおりです:
+--------------------------+
| l1_distance(c1, [1,2,3]) |
+--------------------------+
| 0 |
| 3 |
+--------------------------+
2 rows in set
Cosine_distance
コサイン類似度(cosine similarity)は、2つのベクトルの角度の差異を測る指標であり、ベクトルの長さ(大きさ)に関係なく、方向の類似度を反映します。コサイン類似度の値の範囲は [-1, 1] であり、1 はベクトルが完全に同じ方向であることを表し、0 は直交を表し、-1 は完全に反対の方向を表します。
コサイン類似度の計算式は以下のとおりです:
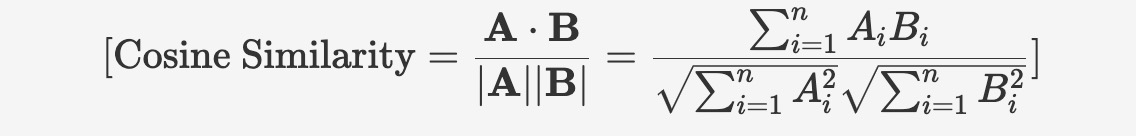
コサイン類似度が1に近いほど類似していることを示すため、ベクトル間の距離の尺度としてコサイン距離(またはコサイン非類似度)が用いられることもあります。コサイン距離は、1からコサイン類似度を引くことで計算できます:
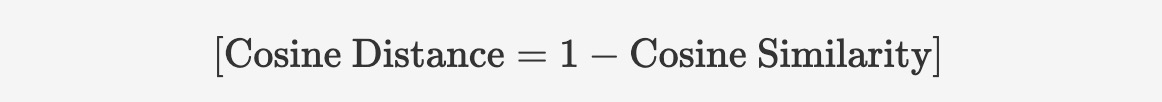
コサイン距離の値の範囲は [0, 2] であり、0 は完全に同じ方向(距離なし)、2 は完全に反対の方向を表します。
関数の構文は以下のとおりです:
cosine_distance(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換可能な他のデータ型もパラメータとして指定できます。例えば、文字列型(例:
'[1,2,3]')などです。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)型の距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t3(c1 vector(3));
INSERT INTO t3 VALUES('[1,2,3]');
INSERT INTO t3 VALUES('[1,2,1]');
SELECT cosine_distance(c1, [1,2,3]) FROM t3;
+------------------------------+
| cosine_distance(c1, [1,2,3]) |
+------------------------------+
| 0 |
| 0.12712843905603044 |
+------------------------------+
2 rows in set
Inner_product
内積は、点乗積またはスカラー積とも呼ばれ、2つのベクトル間の積を表します。幾何学的には、内積は2つのベクトルの方向と大きさの関係を表します。内積の計算式は次のとおりです:
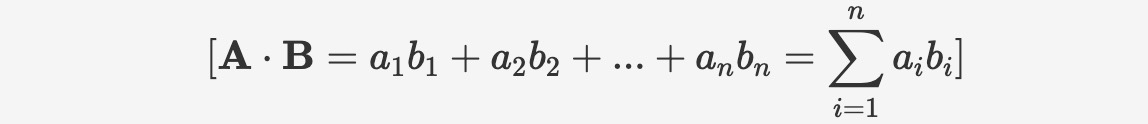
構文は以下のとおりです:
inner_product(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例:文字列型(例:
'[1,2,3]')。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。この関数で疎ベクトルを使用する場合、パラメータのどちらか一方を疎ベクトル形式の文字列として指定できます(例:
c2,'{1:2.4}')。ただし、両方のパラメータを文字列にすることはサポートされていません。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)で表される距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
密ベクトルの例は以下のとおりです:
CREATE TABLE t4(c1 vector(3));
INSERT INTO t4 VALUES('[1,2,3]');
INSERT INTO t4 VALUES('[1,2,1]');
SELECT inner_product(c1, [1,2,3]) FROM t4;
結果は次のとおりです:
+----------------------------+
| inner_product(c1, [1,2,3]) |
+----------------------------+
| 14 |
| 8 |
+----------------------------+
2 rows in set
疎ベクトルの例は以下のとおりです:
CREATE TABLE t4(c1 INT, c2 SPARSEVECTOR, c3 SPARSEVECTOR);
INSERT INTO t4 VALUES(1, '{1:1.1, 2:2.2}', '{1:2.4}');
INSERT INTO t4 VALUES(2, '{1:1.5, 3:3.6}', '{4:4.5}'));
SELECT inner_product(c2,c3) FROM t4;
結果は次のとおりです:
+----------------------+
| inner_product(c2,c3) |
+----------------------+
| 2.640000104904175 |
| 0 |
+----------------------+
2 rows in set
Negative_inner_product
Negative_inner_productは、2つのベクトルの負の内積を計算するために使用されます。計算式は次のとおりです:
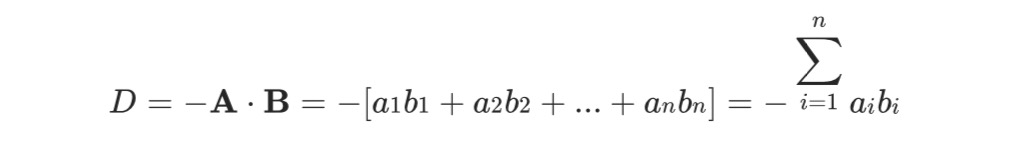
構文は以下のとおりです:
negative_inner_product(vector v1, vector v2)
パラメータの説明は以下のとおりです:
- ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例:文字列型(例:
'[1,2,3]')。 - 2つのパラメータの次元は同じでなければなりません。
- パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。 - この関数で疎ベクトルを使用する場合、パラメータのどちらか一方を疎ベクトル形式の文字列として指定できます(例:
c2,'{1:2.4}')。ただし、両方のパラメータを文字列とする形式はサポートされていません。
戻り値の説明は以下のとおりです:
- 戻り値は
distance(double)で表される距離値です。 - いずれかのパラメータが
NULLの場合、NULLを返します。
密ベクトルの例:
CREATE TABLE t5(c1 vector(3));
INSERT INTO t5 VALUES('[1,2,3]');
INSERT INTO t5 VALUES('[1,2,1]');
SELECT negative_inner_product(c1, [1,2,3]) FROM t5;
結果は次のとおりです:
+-------------------------------------+
| negative_inner_product(c1, [1,2,3]) |
+-------------------------------------+
| -14 |
| -8 |
| -14 |
| -8 |
+-------------------------------------+
4 rows in set
疎ベクトルの例:
CREATE TABLE t5(c1 INT, c2 SPARSEVECTOR, c3 SPARSEVECTOR);
INSERT INTO t5 VALUES(1, '{1:1.1, 2:2.2}', '{1:2.4}');
INSERT INTO t5 VALUES(2, '{1:1.5, 3:3.6}', '{4:4.5}'));
SELECT negative_inner_product(c2,c3) FROM t5;
結果は次のとおりです:
+-------------------------------+
| negative_inner_product(c2,c3) |
+-------------------------------+
| -2.640000104904175 |
| 0 |
+-------------------------------+
2 rows in set
Vector_distance
vector_distanceは、2つのベクトル間の距離を計算するために使用されます。パラメータを指定することで、異なる距離アルゴリズムを選択できます。
構文は以下のとおりです:
vector_distance(vector v1, vector v2 [, string metric])
vector v1/v2 パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例:文字列型(例:
'[1,2,3]')。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
metric パラメータは距離アルゴリズムを指定するために使用されます。選択可能な値は以下のみです:
指定しない場合、デフォルトのアルゴリズムは
euclideanです。指定する場合、選択可能な値は以下のみです。
euclidean。ユークリッド距離を表します。L2_distanceと同じ意味です。manhattan。マンハッタン距離を表します。L1_distanceと同じ意味です。cosine。コサイン距離を表します。Cosine_distanceと同じ意味です。dot。内積を表します。Inner_productと同じ意味です。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)型の距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t5(c1 vector(3));
INSERT INTO t5 VALUES('[1,2,3]');
INSERT INTO t5 VALUES('[1,2,1]');
SELECT vector_distance(c1, [1,2,3], euclidean) FROM t5;
結果は次のとおりです:
+-----------------------------------------+
| vector_distance(c1, [1,2,3], euclidean) |
+-----------------------------------------+
| 0 |
| 2 |
+-----------------------------------------+
2 rows in set
類似度関数
類似度関数は、2つのベクトルの類似度を測るために使用されます。値が大きいほどベクトルがより類似していることを示します。これは距離関数と逆の概念です:類似度が高いほど、距離は小さくなります。ベクトル検索では、類似度のしきい値を設定することで、条件を満たす結果をフィルタリングできます。
inner_product_similarity
inner_product_similarity は、2つのベクトル間の内積類似度を計算するために使用されます。関数の戻り値の計算方法は inner_product と同じですが、距離ではなく類似度を表します。inner_product との換算式は次のとおりです:inner_product_similarity(v1, v2) = (1 + inner_product(v1, v2) / (vector_norm(v1) * vector_norm(v2))) / 2。vector_norm 関数は、ベクトルのユークリッドノルム(大きさ)を計算し、ベクトルと原点間のユークリッド距離を表します。ベクトル v = [v1, v2, v3, ..., vn] のノルムの計算式は次のとおりです:vector_norm(v) = √(v1² + v2² + v3² + ... + vn²)。
構文は以下のとおりです:
inner_product_similarity(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例えば、文字列型(
'[1,2,3]'のように)です。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は
similarity(double)類似度値です。値が大きいほど類似しています。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t12(c1 vector(3));
INSERT INTO t12 VALUES('[1,2,3]');
INSERT INTO t12 VALUES('[1,2,1]');
SELECT inner_product_similarity(c1, [1,2,3]) FROM t12;
結果は次のとおりです:
+---------------------------------------+
| inner_product_similarity(c1, [1,2,3]) |
+---------------------------------------+
| 0.9999999552965164 |
| 0.9364357516169548 |
+---------------------------------------+
2 rows in set
または、より簡単に:
SELECT inner_product_similarity([1,0,0], [0,1,0]);
結果は次のとおりです:
```shell
+--------------------------------------------+
| inner_product_similarity([1,0,0], [0,1,0]) |
+--------------------------------------------+
| 0.5 |
+--------------------------------------------+
1 row in set
cosine_similarity
cosine_similarity は、2つのベクトル間のコサイン類似度を計算するために使用され、ベクトルの長さ(サイズ)に関係なく、方向の類似度を反映します。計算式は次のとおりです:cosine_similarity(v1, v2) = 1 - (cosine_distance(v1, v2) / 2)。
構文は以下のとおりです:
cosine_similarity(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例えば、文字列型(
'[1,2,3]'のように)です。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は
similarity(double)類似度値です。値の範囲は[-1, 1]で、1はベクトルが完全に同じ方向であることを表し、0は直交を表し、-1は完全に反対の方向を表します。値が大きいほど類似しています。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t13(c1 vector(3));
INSERT INTO t13 VALUES('[1,2,3]');
INSERT INTO t13 VALUES('[1,2,1]');
SELECT cosine_similarity(c1, [1,2,3]) FROM t13;
結果は次のとおりです:
+--------------------------------+
| cosine_similarity(c1, [1,2,3]) |
+--------------------------------+
| 0.9999999552965164 |
| 0.9364357516169548 |
+--------------------------------+
2 rows in set
または、より簡単に:
SELECT cosine_similarity([1,0,0], [0,1,0]);
結果は次のとおりです:
+-------------------------------------+
| cosine_similarity([1,0,0], [0,1,0]) |
+-------------------------------------+
| 0.5 |
+-------------------------------------+
1 row in set
l2_similarity
l2_similarity は、2つのベクトル間のL2類似度を計算するために使用されます。L2類似度はユークリッド距離に基づいていますが、戻り値は距離ではなく類似度を表します。類似度値が大きいほど、2つのベクトルは類似しています。l2_squared との換算式は次のとおりです:l2_similarity(v1, v2) = 1 / (1 + l2_squared(v1, v2))。
構文は以下のとおりです:
l2_similarity(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例えば、文字列型(
'[1,2,3]'のように)です。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は
similarity(double)類似度値です。値が大きいほど類似しています。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t14(c1 vector(3));
INSERT INTO t14 VALUES('[1,2,3]');
INSERT INTO t14 VALUES('[1,2,1]');
SELECT l2_similarity(c1, [1,2,3]) FROM t14;
結果は次のとおりです:
+----------------------------+
| l2_similarity(c1, [1,2,3]) |
+----------------------------+
| 1 |
| 0.2 |
+----------------------------+
2 rows in set
または、より簡単に:
SELECT l2_similarity([1,0,0], [0,1,0]);
結果は次のとおりです:
+---------------------------------+
| l2_similarity([1,0,0], [0,1,0]) |
+---------------------------------+
| 0.3333333333333333 |
+---------------------------------+
1 row in set
算術関数
算術関数は、ベクトル型とベクトル型、ベクトル型と1次元配列型または特殊文字列型、および1次元配列型同士や1次元配列型と特殊文字列型との間で、加算(+)、減算(-)、乗算(*)の算術演算を行います。計算は要素ごとに行われます。例えば、加算は次のようになります:
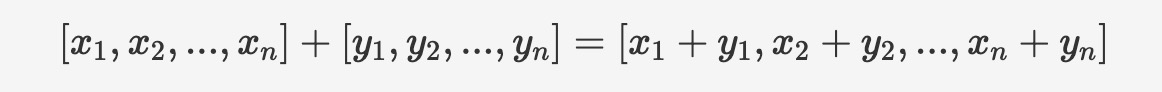
構文は以下のとおりです:
v1 + v2
v1 - v2
v1 * v2
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例えば、文字列型(
'[1,2,3]'のように)です。**注意:**2つのパラメータは同時に文字列型にすることはできません。少なくとも一方のパラメータはベクトル型または1次元配列型でなければなりません。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです:
2つのパラメータのうち少なくとも一方がベクトル型の場合、戻り値はベクトル型のパラメータと同じベクトル型になります。
2つのパラメータがともに1次元配列型のみの場合、戻り値は
array(float)型になります。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t6(c1 vector(3));
INSERT INTO t6 VALUES('[1,2,3]');
SELECT [1,2,3] + '[1.12,1000.0001, -1.2222]', c1 - [1,2,3] FROM t6;
結果は次のとおりです:
+---------------------------------------+--------------+
| [1,2,3] + '[1.12,1000.0001, -1.2222]' | c1 - [1,2,3] |
+---------------------------------------+--------------+
| [2.12,1002,1.7778] | [0,0,0] |
+---------------------------------------+--------------+
1 row in set
比較関数
比較関数は、ベクトル型とベクトル型、ベクトル型と1次元配列型または特殊文字列型との間で、=、!=、>、<、>=、<= の比較記号を用いた比較計算を行います。計算は要素ごとの辞書順比較です。
構文は以下のとおりです:
v1 = v2
v1 != v2
v1 > v2
v1 < v2
v1 >= v2
v1 <= v2
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例えば、文字列型(
'[1,2,3]'のように)です。注意
2つのパラメータのうち、少なくとも一方はベクトル型でなければなりません。
2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は bool 型です。
いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t7(c1 vector(3));
INSERT INTO t7 VALUES('[1,2,3]');
SELECT c1 = '[1,2,3]' FROM t7;
結果は次のとおりです:
+----------------+
| c1 = '[1,2,3]' |
+----------------+
| 1 |
+----------------+
1 row in set
集計関数
注意
ベクトル列をGROUP BY条件として使用することはサポートされていません。DISTINCT もサポートされていません。
Sum
Sum 関数は、テーブル内のベクトル列の合計を計算するために使用され、要素ごとに累積して合計ベクトルを得ます。
構文は以下のとおりです:
sum(vector v1)
パラメータの説明は以下のとおりです:
- ベクトル型のみサポートされています。
戻り値の説明は以下のとおりです:
sum (vector)の値を返します。
例:
CREATE TABLE t8(c1 vector(3));
INSERT INTO t8 VALUES('[1,2,3]'),('[2,3,4]'),('[3,4,5]');
SELECT sum(c1) FROM t8;
結果は次のとおりです:
+---------+
| sum(c1) |
+---------+
| [6,9,12] |
+---------+
1 row in set
複数行のベクトルを要素ごとに加算する場合:1次元目は1+2+3=6、2次元目は2+3+4=9、3次元目は3+4+5=12、したがって合計は [6,9,12] となります。
Avg
Avg 関数は、テーブル内のベクトル列の平均値を計算するために使用されます。
構文は以下のとおりです:
avg(vector v1)
パラメータの説明は以下のとおりです:
- ベクトル型のみサポートされています。
戻り値の説明は以下のとおりです:
avg (vector)の値を返します。このベクトル列内の
NULL行は計算に含まれません。入力パラメータが空の場合、
NULLを返します。
例:
CREATE TABLE t9(c1 vector(3));
INSERT INTO t9 VALUES('[2,4,6]'),('[4,6,8]'),('[6,8,10]');
SELECT avg(c1) FROM t9;
結果は次のとおりです:
+---------+
| avg(c1) |
+---------+
| [4,6,8] |
+---------+
1 row in set
複数行のベクトルを要素ごとに平均する場合:1次元目は (2+4+6)/3=4、2次元目は (4+6+8)/3=6、3次元目は (6+8+10)/3=8、したがって平均値は [4,6,8] となります。
その他の一般的なベクトル関数
Vector_norm
Vector_norm 関数は、ベクトルのユークリッドノルム(大きさ)を計算するために使用され、ベクトルと原点間のユークリッド距離を表します。計算式は次のとおりです:
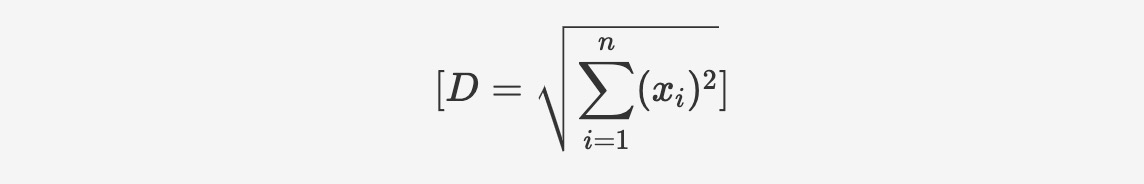
構文は以下のとおりです:
vector_norm(vector v1)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例えば、文字列型(
'[1,2,3]'のように)です。パラメータに1次元配列を指定する場合、その配列の要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです:
norm(double)のノルム値を返します。パラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t10(c1 vector(3));
INSERT INTO t10 VALUES('[1,2,3]');
SELECT vector_norm(c1),vector_norm([1,2,3]) FROM t10;
結果は次のとおりです:
+--------------------+----------------------+
| vector_norm(c1) | vector_norm([1,2,3]) |
+--------------------+----------------------+
| 3.7416573867739413 | 3.7416573867739413 |
+--------------------+----------------------+
1 row in set
ベクトルの正規化
ベクトルの正規化(Normalization)とは、ベクトルの長さ(ノルム)を1に標準化するプロセスを指します。vector_norm 関数は、ベクトルの正規化を実現するためによく使用されます。
l2_distance で距離タイプのベクトルインデックスを使用する場合、類似度検索の精度を向上させるために、ベクトルを正規化することを推奨します。正規化後のベクトルのノルムは1となり、L2距離の範囲は [0, 2] に制限されるため、類似度値が小さすぎることによる精度の問題を回避できます。
例えば、ベクトル [3, 4] の場合:
- ベクトルのノルム:
vector_norm([3, 4]) = √(3² + 4²) = 5 - 正規化後:
[3, 4] / 5 = [0.6, 0.8]
正規化後のベクトルのノルムは1です。検証方法は次のとおりです:
SELECT vector_norm([0.6, 0.8]);
結果は次のとおりです:
+-------------------------+
| vector_norm([0.6, 0.8]) |
+-------------------------+
| 1.000000029802322 |
+-------------------------+
1 row in set
Vector_dims
Vector_dims 関数は、ベクトルの次元を返します。
構文は以下のとおりです:
vector_dims(vector v1)
パラメータの説明は以下のとおりです:
- ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。例えば、文字列型(
'[1,2,3]'のように)です。
戻り値の説明は以下のとおりです:
dims(int64)の次元値を返します。パラメータが
NULLの場合、エラーが発生します。
例:
CREATE TABLE t11(c1 vector(3));
INSERT INTO t11 VALUES('[1,2,3]');
INSERT INTO t11 VALUES('[1,1,1]');
SELECT vector_dims(c1), vector_dims('[1,2,3]') FROM t11;
結果は次のとおりです:
+-----------------+------------------------+
| vector_dims(c1) | vector_dims('[1,2,3]') |
+-----------------+------------------------+
| 3 | 3 |
| 3 | 3 |
+-----------------+------------------------+
2 rows in set