


JOIN操作は、2つのデータソース(テーブルやビューなど)からの出力を結合し、1つのデータソースを返します。複数テーブルのJOINのタイプは、SQL文のWHERE(非ANSI)またはFROM ... JOIN (ANSI) 句で定義されます。FROM句に複数のテーブルが存在する限り、データベースは結合を実行します。
結合条件は、テーブル間の関連関係を定義するために使用されます。この文で結合条件が指定されていない場合、データベースはデカルト結合を実行し、一方のテーブルの各行ともう一方のテーブルの各行をマッチングします。
結合ツリー
結合ツリーは通常、反転したツリー構造で表されます。下図のように、T1 は左側に結合するテーブルであり、ドライバーテーブルとも呼ばれ、通常は次元テーブルです。T2 は右側に結合するテーブルで、通常はファクトテーブルです。オプティマイザーは通常、左から右の順に結合テーブルを処理します。

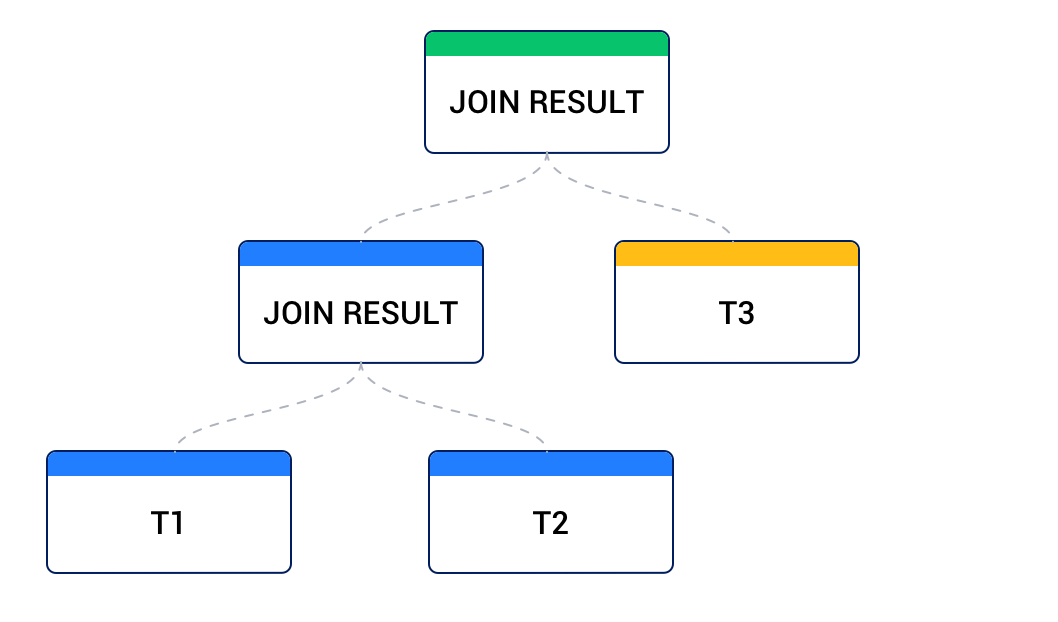
結合のデータソースは、別の結合の結果から得られることもあります。左側のデータソースが別の結合の結果から、右側のデータソースがベーステーブルから得られる場合、これを左深いツリーと呼び、ほとんどの業務計画は左深いツリーです。下図のように。
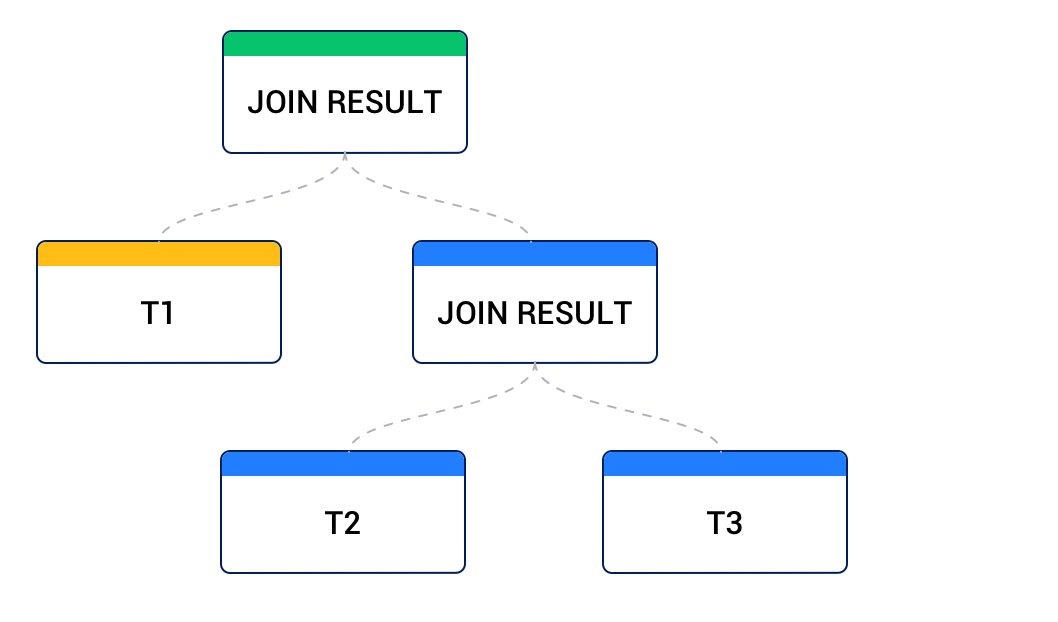
右側のデータソースが別の結合の結果から、左側のデータソースがベーステーブルから得られる場合、これを右深いツリーと呼びます。下図のように。
いずれかの結合ノードが他の結合ノードと異なる形状をしている場合、これを密結合ツリーと呼びます。下図のように。

オプティマイザーによる結合の最適化
FROM句に複数のテーブルが存在する場合、オプティマイザーは各テーブルペアに対する最も効率的な結合操作を決定する必要があります。オプティマイザーは以下の観点から判断します。
項目 |
説明 |
|---|---|
| ベーステーブルのパス | 各ベーステーブルについて、オプティマイザーは主テーブルスキャンまたはインデックススキャンなど、最適なスキャン方法を選択する必要があります。 |
| 結合アルゴリズム | 2つのデータソースを結合するために、オプティマイザーは2つのデータソースを関連付ける方法を決定する必要があります。利用可能な結合アルゴリズムには、ネステッド・ループ結合、メジャーコンパクション結合、ハッシュ結合があります。各結合アルゴリズムには効率的な使用シナリオがあり、オプティマイザーは統計情報に基づいて最適な結合アルゴリズムを選択する必要があります。 |
| 結合タイプ | オプティマイザーがサポートする結合タイプには、INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN、LEFT SEMI JOIN、RIGHT SEMI JOIN、LEFT ANTI JOIN、RIGHT ANTI JOIN、CONNECT BY JOINがあります。後者5つの結合タイプは、オプティマイザーがリライトする結合タイプであり、SQLでは構文指定でこれらの結合タイプを指定することはできません。 |
| 結合順序 | 結合するテーブルの数が2つを超える場合、オプティマイザーは最適な結合順序を決定する必要があります。例:FROM T1, T2, T3 の場合、可能な結合順序には、T1 JOIN T2 JOIN T3、T1 JOIN T3 JOIN T2 などがあります。オプティマイザーは、可能な結合順序から実行性能が最も優れている結合順序を決定する必要があります。 |
オプティマイザーによる結合計画の決定
結合の順序と方法を決定する際、オプティマイザーの目標は結合データ量を早期に削減し、SQL文の実行全体でより少ない処理を行うことです。オプティマイザーは、可能な結合順序、結合方法、利用可能なアクセスパスに基づいて一連の実行計画を生成し、各計画のコストを推定してコストが最も低い計画を選択します。
オプティマイザーは、I/O、ネットワーク、CPUのオーバーヘッドを計算することでクエリ計画のコストを推定します。異なるデータ配分方法は異なるネットワークオーバーヘッドを伴い、さらに異なる関数や式は異なるCPUオーバーヘッドを伴います。オプティマイザーはこれらの指標を用いてクエリ計画の総コストを決定します。これらの指標は、PARALLEL、ENABLE_ROWSETS、システム統計情報など、コンパイル時に多くの初期化パラメータやセッション設定の影響を受ける可能性があります。
例えば、オプティマイザーは以下の方法でコストを見積もります:
- nested loop joinのコストは、外部テーブルの各行と内部テーブルの対応する各行をメモリに読み込むコストに依存します。オプティマイザーは内部テーブルの統計情報を用いてこれらのコストを推定します。
- merge joinのコストは、主にすべてのソースをメモリに読み込んでソートするコストに依存します。
- hash joinのコストは、主に結合の一方の入力側でハッシュテーブルを構築し、もう一方の入力側の行を用いてそれを検索するコストに依存します。