


パラレル実行は、SQLクエリタスクを最適化する戦略であり、クエリタスクを複数のサブタスクに分割して複数のプロセッサ上で同時に実行させることで、クエリタスク全体の実行効率を向上させます。
現代のコンピュータシステムでは、マルチコアプロセッサ、マルチスレッド、および高速なネットワーク接続が広く採用されているため、パラレル実行は効率的なクエリ技術となっています。この技術は、計算集約型の大規模クエリの応答時間を大幅に短縮し、オフラインデータウェアハウス、リアルタイムレポート、オンラインのビッグデータ分析などの業務シナリオで広く利用されています。また、一括データ導入やインデックステーブルの迅速な構築などの分野でもその強力な適用能力を示しています。
パラレル実行は、以下のSQLクエリシナリオの性能を顕著に向上させます:
- 大規模テーブルのスキャン、大規模テーブルの結合、大量データのソート、集計の処理。
- 主キーの変更、列型の変更、インデックスの作成など、大規模テーブルに対するDDL操作の実行。
- 既存の大量データからテーブルの作成(
Create Table As Selectを使用)。 - データの一括挿入、削除、更新操作の実行。
適用シナリオ
パラレル実行は、オフラインデータウェアハウス、リアルタイムレポート、オンラインのビッグデータ分析などの分析系システムだけでなく、OLTP分野でも一定の役割を果たします。DDL操作やデータバッチ処理の高速化に利用できます。
パラレル実行は、複数のCPUおよびI/Oリソースを最大限活用することで、SQL実行時間の短縮を実現します。以下の条件が満たされている場合、パラレル実行の方が直列実行よりも優れています:
- データアクセス量が多い
- SQLクエリの同時実行度が低い
- 待ち時間に対する要求が低い
- 十分なハードウェアリソースを備えている
パラレル実行は、複数のプロセッサを協調させて同一タスクを並行処理するため、以下のシステム環境を備えている場合にパフォーマンスが向上します:
- マルチプロセッサシステム(SMP)およびクラスタ
- I/O帯域幅が十分である
- 余剰メモリを備えている(ソートやHashテーブル作成などのメモリ集約型操作の処理に利用可能)
- システム負荷が適度であるか、またはピークとトレンドの特徴を持つ(例:システム負荷が通常30%以下に保たれる)
システムが上記の特性を満たしていない場合、パラレル実行によるパフォーマンス向上は顕著ではない可能性があります。負荷が高い、メモリが小さい、またはI/O能力が弱いシステムでは、パラレル実行の効果が低下することさえあります。
パラレル実行には特別なハードウェア要件はありませんが、CPUコア数、メモリサイズ、ストレージI/O性能、ネットワーク帯域幅がすべてパラレル実行のパフォーマンスに影響を与える点に注意が必要です。これらのいずれかがボトルネックとなると、全体のパフォーマンスに影響を及ぼす可能性があります。
動作原理
パラレル実行は、SQLクエリタスクを複数のサブタスクに分割し、これらのサブタスクを複数のプロセッサにスケジュールして実行することで、効率的な並列実行を実現します。
SQLクエリがパラレル実行計画に解析されると、その実行プロセスは以下の手順で進みます:
- SQLメインスレッド(SQLの受信と解析を担当するスレッド)は、計画の形態に基づいて、事前にパラレル実行に必要なスレッドリソースを割り当てます。これらのスレッドリソースは、複数のマシンにまたがるクラスタを含む場合があります。
- SQLメインスレッドは、パラレルスケジューリングオペレーター(PX Coordinator)を有効化します。
- パラレルスケジューリングオペレーターは計画を解析し、複数の操作ステップに分割し、ボトムアップの順序でこれらの操作をスケジュールします。各操作は、可能な限り最大限にパラレル実行できるよう設計されています。
- すべての操作のパラレル実行が完了すると、パラレルスケジューリングオペレーターは計算結果を受信し、上位のオペレーター(例:Aggregateオペレーター)に渡します。そこで、残りの並列化できない計算(例:最終的なSUM計算)が直列実行で完了します。
並列の粒度
並列データスキャンの基本単位は、Granuleと呼ばれます。
OceanBaseデータベースは、テーブルスキャンタスクを複数のGranuleに細分化し、各Granuleはスキャンタスクの範囲を定義します。各Granuleは単一のパーティションのデータのみを対象とするため、各パーティションのデータには独立したスキャンタスクが対応します。簡単に言えば、各Granuleはパーティション内のスキャンタスクに対応します。
Granuleの粒度特性に基づき、以下の2つのカテゴリに分類できます:
Partition Granule
Partition Granuleが記述する範囲は完全なパーティションです。スキャンタスクが対象とするパーティション数に応じて、同じくらいの数のPartition Granuleが生成されます。ここでのパーティションは、プライマリテーブルのパーティションでもインデックスのパーティションでもかまいません。Partition Granuleは、主にPartition Wise Joinで使用され、2つのテーブルの対応するパーティションがそれぞれPartition Granuleによって処理されることを保証します。
Block Granule
Block Granuleが記述する範囲は、パーティション内の連続したデータ区間です。データスキャンのシナリオでは、通常Block Granuleを用いてデータを分割します。各パーティションは複数のBlockに分割され、これらのBlockは一定のルールに従って接続され、並列ワーカースレッドが処理するためのタスクキューを形成します。
次の図は、Block Granuleの動作原理を示しています。
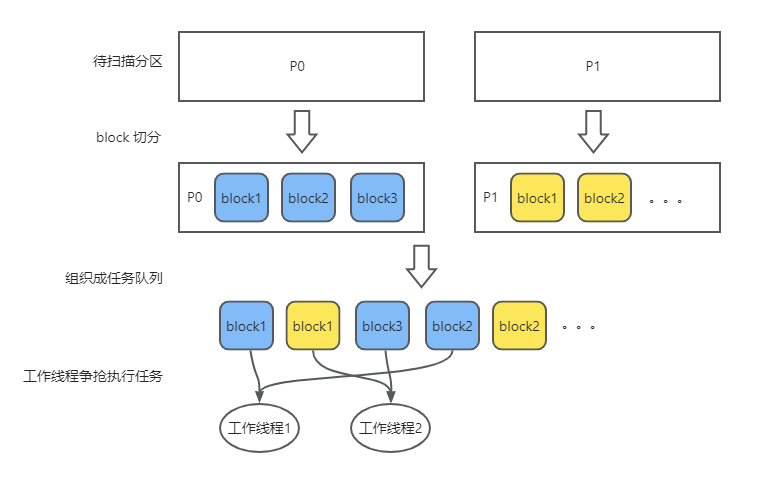
与えられた並列度の下で、スキャンタスクの均等性を保つため、オプティマイザーは自動的にデータをPartition GranuleまたはBlock Granuleに分割する方法を選択します。Block Granuleを選択した場合、並列実行フレームワークはランタイムでBlockの分割を動的に決定します。全体的な原則は、Blockが大きすぎず小さすぎないようにすることです。Blockが大きすぎるとデータの偏りが生じ、一部のスレッドが十分に働かない可能性があります。Blockが小さすぎると、頻繁なスキャン切り替えによるオーバヘッドが発生します。
一度パーティション粒度(すなわち、Block Granule)の分割が完了すると、各粒度に対応するスキャンタスクが1つずつ生成されます。Table Scan演算子は、これらのスキャンタスクを順次処理し、すべてのタスクが終了するまで段階的に完了させます。
パラレル実行モデル
プロデューサー・コンシューマーパイプラインモデル
並列実行では、プロデューサー・コンシューマーモデルを用いたパイプライン実行が行われます。
並列スケジューラーが実行計画を解析すると、計画は複数の操作ステップに分割され、各操作ステップはDFO(Data Flow Operation)と呼ばれます。
通常、並列スケジューラーは2つのDFOを同時に開始し、これら2つのDFOはプロデューサー・コンシューマー方式で接続され、DFO間の並列実行を形成します。各DFOは一連のスレッドを使用して実行され、これをDFO内の並列実行と呼びます。また、DFOが使用するスレッド数をDOP(Degree Of Parallisim)と呼びます。
前段階のコンシューマーDFOは、次の段階でプロデューサーDFOに変わります。並列スケジューラーの調整のもと、コンシューマーDFOとプロデューサーDFOは同時に開始されます。以下の図は、プロデューサー・コンシューマーモデルにおけるDFOの処理フローを示しています。
- DFO Aが生成したデータは、即座にDFO Bに転送されて計算されます。
- DFO Bの計算が完了すると、データを現在のスレッドに格納し、上位のDFO Cの起動を待ちます。
- DFO BがDFO Cの起動完了通知を受信すると、自身の役割をプロデューサーに切り替え、DFO Cへのデータ転送を開始します。DFO Cがデータを受信すると計算を開始します。
以下のクエリ例では、SELECT ステートメントの実行計画はまず game テーブルに対して全表スキャンを行い、次に team テーブルでグループ化して合計を求め、最終的に各 team テーブルの総得点を計算します。
CREATE TABLE game (round INT PRIMARY KEY, team VARCHAR(10), score INT)
PARTITION BY HASH(round) PARTITIONS 3;
INSERT INTO game VALUES (1, "CN", 4), (2, "CN", 5), (3, "JP", 3);
INSERT INTO game VALUES (4, "CN", 4), (5, "US", 4), (6, "JP", 4);
SELECT /*+ PARALLEL(3) */ team, SUM(score) TOTAL FROM game GROUP BY team;
obclient> EXPLAIN SELECT /*+ PARALLEL(3) */ team, SUM(score) TOTAL FROM game GROUP BY team;
obclient> EXPLAIN SELECT /*+ PARALLEL(3) */ team, SUM(score) TOTAL FROM game GROUP BY team;
+---------------------------------------------------------------------------------------------------------+
| Query Plan |
+---------------------------------------------------------------------------------------------------------+
| ================================================================= |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| ----------------------------------------------------------------- |
| |0 |PX COORDINATOR | |1 |4 | |
| |1 | EXCHANGE OUT DISTR |:EX10001|1 |4 | |
| |2 | HASH GROUP BY | |1 |4 | |
| |3 | EXCHANGE IN DISTR | |3 |3 | |
| |4 | EXCHANGE OUT DISTR (HASH)|:EX10000|3 |3 | |
| |5 | HASH GROUP BY | |3 |2 | |
| |6 | PX BLOCK ITERATOR | |1 |2 | |
| |7 | TABLE SCAN |game |1 |2 | |
| ================================================================= |
| Outputs & filters: |
| ------------------------------------- |
| 0 - output([INTERNAL_FUNCTION(game.team, T_FUN_SUM(T_FUN_SUM(game.score)))]), filter(nil), rowset=256 |
| 1 - output([INTERNAL_FUNCTION(game.team, T_FUN_SUM(T_FUN_SUM(game.score)))]), filter(nil), rowset=256 |
| dop=3 |
| 2 - output([game.team], [T_FUN_SUM(T_FUN_SUM(game.score))]), filter(nil), rowset=256 |
| group([game.team]), agg_func([T_FUN_SUM(T_FUN_SUM(game.score))]) |
| 3 - output([game.team], [T_FUN_SUM(game.score)]), filter(nil), rowset=256 |
| 4 - output([game.team], [T_FUN_SUM(game.score)]), filter(nil), rowset=256 |
| (#keys=1, [game.team]), dop=3 |
| 5 - output([game.team], [T_FUN_SUM(game.score)]), filter(nil), rowset=256 |
| group([game.team]), agg_func([T_FUN_SUM(game.score)]) |
| 6 - output([game.team], [game.score]), filter(nil), rowset=256 |
| 7 - output([game.team], [game.score]), filter(nil), rowset=256 |
| access([game.team], [game.score]), partitions(p[0-2]) |
| is_index_back=false, is_global_index=false, |
| range_key([game.round]), range(MIN ; MAX)always true |
+---------------------------------------------------------------------------------------------------------+
29 rows in set
上記のクエリ例の実行概要図は以下のとおりです:
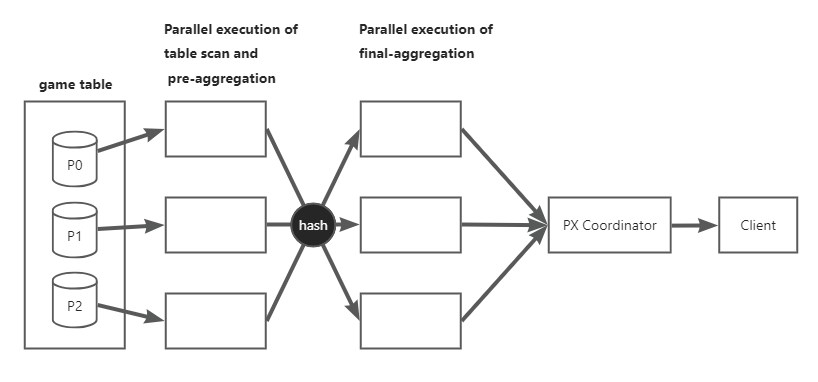
図からわかるように、このクエリでは実際に6つのスレッドが使用され、実行フローとタスクの割り当ては以下のとおりです:
- 第1ステップ:最初の3つのスレッドが
gameテーブルのスキャンを担当し、各スレッド内でgame.teamデータの事前集計を行います。 - 第2ステップ:後の3つのスレッドが事前集計されたデータに対して最終的な集計を行います。
- 第3ステップ:最終的な集計結果は並列スケジューラーに渡され、クライアントに返却されます。
第1ステップのデータを第2ステップに渡す際には、game.team フィールドをHash関数として使用し、事前集計されたデータをどのスレッドに渡すかを決定します。
プロデューサーとコンシューマー間のデータ配信方式
データ配信方式とは、一連のパラレル実行ワーカースレッド(プロデューサー)が別のワーカースレッド(コンシューマー)にデータを送信する際に使用する方法を指します。オプティマイザーは、最適なパフォーマンスを達成するために、一連の最適化戦略を用いて最適なデータ再分散方式を選択します。
一般的なパラレル実行におけるデータ配信方式には以下のものがあります:
Hash Distribution
Hash Distribution を使用する場合、プロデューサーは Distribution Key に基づいてデータ行にハッシュ計算を行い、その結果をモジュロ演算して、データをどのコンシューマー・ワーカースレッドに送信するかを決定します。通常、Hash Distribution はデータを複数のコンシューマースレッドに均等に分散できます。
Pkey Distribution
Pkey Distribution を使用する場合、プロデューサーはデータ行に対応するターゲットテーブルのパーティションを計算し、その後その行データをそのパーティションを処理するコンシューマースレッドに送信します。Pkey Distribution は、Partitial Partitions Wise Join シナリオでよく使用されます。この場合、コンシューマー側のデータは再分散する必要がなく、プロデューサー側のデータと直接 Partition Wise Join を実行できるため、ネットワーク通信量を削減し、パフォーマンスを向上させることができます。
Pkey Hash Distribution
Pkey Hash Distribution を使用する場合、プロデューサーはまずデータ行に対応するターゲットテーブルのパーティションを計算し、次に Distribution Key に基づいてデータ行にハッシュ計算を行い、それを処理するコンシューマースレッドを決定します。
Pkey Hash Distribution は、Parallel DML シナリオでよく使用されます。このシナリオでは、一つのパーティションが複数のスレッドによって同時に更新される可能性があるため、Pkey Hash Distribution を使用して、同じ値を持つデータ行は同一のスレッドが処理し、異なる値を持つデータ行は可能な限り均等に複数のスレッドに分散されるようにします。
Broadcast Distribution
Broadcast Distribution を使用する場合、プロデューサーは各データ行をコンシューマー側の各スレッドに送信し、各コンシューマースレッドがプロデューサー側の全量データを保有するようにします。Broadcast Distribution は、小さなテーブルのデータを Join を実行するすべてのノードにコピーし、その後ローカルで Join 操作を実行することで、ネットワーク通信量を削減するシナリオでよく使用されます。
Broadcast to Host Distribution(BC2HOST)
Broadcast to Host Distribution を使用する場合、プロデューサーは各データ行をコンシューマー側の各ノードに送信し、各コンシューマーノードがプロデューサー側の全量データを保有するようにします。その後、ノード内のコンシューマースレッドが協調してこのデータを処理します。
Broadcast to Host Distribution は、
NESTED LOOP JOINやSHARED HASH JOINシナリオでよく使用されます。NESTED LOOP JOINシナリオでは、各コンシューマースレッドが共有データから一部のデータを取得してドライブデータとし、ターゲットテーブルに対する Join 操作を実行します。SHARED HASH JOINシナリオでは、各コンシューマースレッドが共有データに基づいて共通の Hash テーブルを構築し、各スレッドが独立して同一の Hash テーブルを構築することによる不必要なオーバーヘッドを回避します。Range Distribution
Range Distribution を使用する場合、プロデューサーは Range の範囲に基づいてデータを分割し、異なるコンシューマースレッドが異なる範囲のデータを処理するようにします。Range Distribution はソートシナリオでよく使用されます。各コンシューマースレッドは割り当てられたデータのみをソートすればよく、グローバル範囲での順序付けを保つことができます。
Random Distribution
Random Distribution を使用する場合、プロデューサーはデータをランダムに分散させた後、コンシューマースレッドに送信します。これにより、各コンシューマースレッドが処理するデータ量がほぼ均等になり、ロードバランシングが実現されます。Random Distribution は、多スレッド並列
UNION ALLシナリオでよく使用されます。このシナリオでは、データの分散とロードバランシングのみが必要であり、データ間に他の関連制約はありません。Hybrid Hash Distribution
Hybrid Hash Distribution は、適応型の Join アルゴリズムに使用されます。収集した統計情報を組み合わせることで、OceanBase データベースは通常値と高頻度値を定義するための一連のパラメータを提供します。Hybrid Hash Distribution 方式では、Join の両側の通常値には Hash Distribution を使用し、左側の高頻度値には Broadcast Distribution を使用し、右側の高頻度値には Random Distribution を使用します。
プロデューサーとコンシューマー間のデータ転送メカニズム
同一時刻に、パラレルスケジューリングオペレーターによって起動された2つのDFO間では、プロデューサー・コンシューマー方式で並列実行が接続されます。プロデューサーとコンシューマー間でデータを転送するためには、転送ネットワークを作成する必要があります。
例えば、プロデューサーDFOがDOP=2でデータスキャンを行い、コンシューマーDFOがDOP=3でデータ集計計算を行う場合、各プロデューサースレッドはコンシューマースレッドに3つの仮想リンクを作成して接続し、合計で6つの仮想リンクが作成されます。下図のようになります。
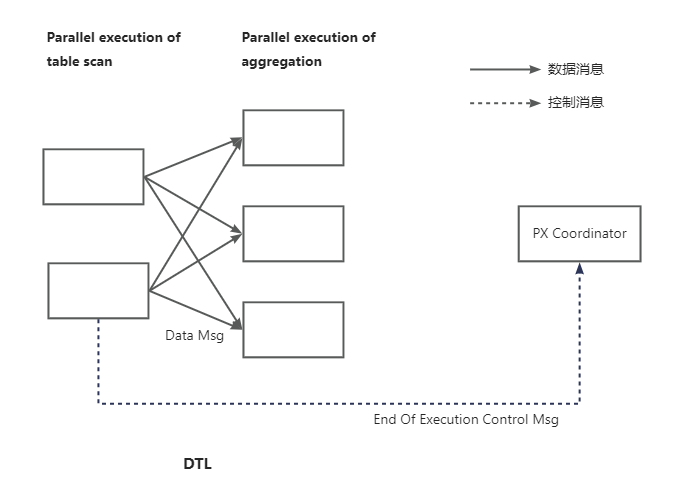
作成された仮想的な転送ネットワークは、データ転送層(Data Transfer Layer、略称:DTL)と呼ばれます。OceanBaseデータベースのパラレル実行フレームワークでは、すべての制御メッセージと行データはDTLを介して転送されます。各ワーカースレッドは数千の仮想リンクを確立できるため、高い拡張性を備えています。さらに、DTLにはデータバッファリング、バッチデータ送信、自動トラフィック制御などの機能もあります。
DTLの両端が同一ノード上にある場合、DTLはメモリコピングを用いてメッセージを伝達します。一方、DTLの両端が異なるノード上にある場合、DTLはネットワーク通信を介してメッセージを伝達します。
ワーカースレッド
パラレルクエリでは、主に2種類のスレッドがあります:1つのメインスレッドと複数のパラレルワーカースレッドです。メインスレッドは通常のTPクエリと同じスレッドプールを使用しますが、パラレルワーカースレッドは専用のスレッドプールから供給されます。
OceanBaseデータベースは、専用スレッドプールモデルを採用してパラレルワーカースレッドを割り当てます。各テナントは、所属する各ノード上に専用のパラレル実行スレッドプールを持ち、すべてのパラレルクエリワーカースレッドはこのスレッドプールから割り当てられます。
パラレルスケジューリングオペレーターは、各DFOをスケジューリングする前に、スレッドプールからスレッドリソースを要求します。DFOの実行完了後、スレッドリソースは直ちに解放されます。
スレッドプールの初期サイズは0で、必要に応じて動的に増加し、上限はありません。過剰なアイドルスレッドを避けるため、スレッドプールには自動回収メカニズムが導入されています。任意のスレッドについて:
- アイドル時間が10分を超え、かつスレッドプール内の残存スレッド数が8個を超える場合、回収・破棄されます。
- アイドル時間が60分を超えた場合、無条件で破棄されます。
スレッドプールのサイズに上限はありませんが、以下の2つのメカニズムにより、ほとんどの場合実質的な上限が形成されます:
- パラレル実行開始前に、Admissionモジュールを通じてスレッドリソースを予約する必要があり、予約に成功した場合にのみ実行に投入されます。このメカニズムにより、並行クエリの数を制限できます。Admissionモジュールの詳細については、並行制御とキューイングを参照してください。
- スレッドプールからスレッドを申請する際、1回の申請で割り当てられるスレッド数はNを超えません。ここで、NはテナントUnitのMIN_CPUにpx_workers_per_cpu_quotaを乗算した値に等しく、これを超える場合でも最大でN個のスレッドが割り当てられます。クラスタ構成パラメータpx_workers_per_cpu_quotaのデフォルト値は10です。例えば、あるDFOのDOP = 100で、Aノードから30個のスレッド、Bノードから70個のスレッドを申請する必要がある場合を考えます。UnitのMIN_CPU = 4、px_workers_per_cpu_quota = 10とすると、N = 4 * 10 = 40となります。最終的に、このDFOはAノードで実際に30個のスレッド、Bノードで実際に40個のスレッドを申請し、実質的なDOPは70となります。
ロードバランシングによるパフォーマンスの最適化
最適なパフォーマンスを実現するためには、すべてのワーカースレッドに割り当てられるタスクはできるだけ均等である必要があります。
SQLがBlock Granule単位でタスクを分割する場合、作業タスクは動的にワーカースレッド間で分散されます。これにより、ワークロードの不均衡、つまり特定のワーカースレッドの処理負荷が他のワーカースレッドを大幅に上回ることを最小限に抑えることができます。
SQLがPartition Granule単位でタスクを分割する場合、タスク数をワーカースレッド数の整数倍に設定することでパフォーマンスを最適化できます。これは、Partition Wise Joinや並列DMLのシナリオで非常に有用です。
あるテーブルが16個のパーティションを持ち、各パーティションのデータ量がほぼ同じであると仮定します。この場合、16個のワーカースレッド(DOPが16)を使用すると、約16分の1の時間で作業を完了できます。または、5個のワーカースレッドを使用して5分の1の時間で作業を完了するか、2個のスレッドを使用して半分の時間で作業を完了することもできます。しかし、15個のスレッドを使用して16個のパーティションを処理する場合、最初のスレッドが1つのパーティションの処理を終えると、16番目のパーティションの処理を開始します。他のスレッドは処理を終えるとアイドル状態になります。各パーティションのデータ量が近い場合、この構成ではパフォーマンスが低下します。各パーティションのデータ量に差異がある場合、実際のパフォーマンスは状況によって異なります。
同様に、6個のスレッドを使用して16個のパーティションを処理し、各パーティションのデータ量がほぼ同じであると仮定します。
この場合、各スレッドは最初のパーティションを終えた後、次のパーティションを処理しますが、3番目のパーティションを処理するのは4個のスレッドのみで、残りの2個のスレッドはアイドル状態のままです。
一般的に、与えられた数のパーティション(N)と与えられた数のワーカースレッド(P)で並列操作を実行するのに必要な時間は、NをPで割った値に等しいと仮定することはできません。この公式は、一部のスレッドが他のスレッドが最後のパーティションを終えるのを待つ必要がある可能性を考慮していません。しかし、適切なDOPを選択することで、ワークロードの不均衡を最小限に抑え、パフォーマンスを最適化できます。
適用外れのシナリオ
パラレル実行は、通常、以下のシナリオでは推奨されません:
システム内の典型的なSQLの実行時間がすべてミリ秒単位である場合。
パラレルクエリ自体にミリ秒単位のスケジューリングオーバヘッドがあるため、短いクエリについては、パラレル実行によるメリットがスケジューリングオーバヘッドによって相殺される可能性があります。
システム負荷が非常に高い場合。
パラレル実行の設計目標は、システムの余剰リソースを最大限に活用することです。システム自体に余剰リソースがない場合、パラレル実行は追加のメリットをもたらさない可能性があり、むしろシステム全体のパフォーマンスに影響を与える可能性があります。
直列実行は、単一のスレッドでデータベース操作を実行します。以下の場合、直列実行の方がパラレル実行よりも優れています:
- クエリがアクセスするデータ量が非常に少ない場合。
- 高並行性が求められる場合。
- クエリの実行時間が100ミリ秒未満の場合。
以下の場合は、部分的にパラレル実行ができません:
- 最上位のDFOはパラレル化不要です。これはクライアントとのやり取りを担当し、
LIMIT、PX COORDINATORなど、最上位でパラレル化不要な部分の操作を実行します。 TABLEUDFを含む場合、そのUDFを含むDFOは直列実行のみ可能で、残りの部分は引き続きパラレル実行可能です。- OLTPシステムにおける一般的な
SELECTおよびDML文では、パラレル実行が適用されない場合があります。