


obvec_jdbcは、OceanBaseのベクトルストレージシナリオおよびJSONテーブル仮想テーブルシナリオ向けに実装されたJava SDKです。本記事では、obvec_jdbcの使用方法について説明します。
インストール
obvec_jdbcは以下のいずれかの方法でインストールできます。
Maven依存関係の追加
プロジェクトのpom.xmlファイルにobvec_jdbcの依存関係を追加します。
<dependency>
<groupId>com.oceanbase</groupId>
<artifactId>obvec_jdbc</artifactId>
<version>1.0.4</version>
</dependency>
ソースコードからのインストール
obvec_jdbcをインストールします。
# obvec_jdbcリポジトリをクローン git clone https://github.com/oceanbase/obvec_jdbc.git # obvec_jdbcディレクトリに移動 cd obvec_jdbc # obvec_jdbcをインストール mvn install依存関係を追加します。
<dependency> <groupId>com.oceanbase</groupId> <artifactId>obvec_jdbc</artifactId> <version>1.0.4</version> </dependency>
APIの定義と使用
obvec_jdbcは、OceanBaseのベクトル検索機能およびJSONテーブル仮想テーブル機能を操作するためのObVecClientオブジェクトを提供します。
ベクトル検索機能の使用
クライアントの作成
以下のインターフェース定義を使用してObVecClientオブジェクトを構築します:
# uri:接続文字列。アドレス、ポート、接続するデータベース名などが含まれます。
# user:ユーザー名
# password:パスワード
public ObVecClient(String uri, String user, String password);
例:
import com.oceanbase.obvec_jdbc.ObVecClient;
String uri = "jdbc:oceanbase://127.0.0.1:2881/test";
String user = "root@test";
String password = "";
String tb_name = "JAVA_TEST";
ObVecClient ob = new ObVecClient(uri, user, password);
ObFieledSchemaクラス
このクラスはテーブルの列スキーマを定義するために使用されます。コンストラクタは以下のとおりです:
# name:列名
# dataType:列のデータ型
public ObFieldSchema(String name, DataType dataType);
現在サポートされている列データ型は以下のとおりです:
DataType |
説明 |
|---|---|
| BOOL | TINYINTと等価です |
| INT8 | TINYINTと等価です |
| INT16 | SMALLINTと等価です |
| INT32 | INTと等価です |
| INT64 | BIGINTと等価です |
| FLOAT | FLOATと等価です |
| DOUBLE | DOUBLEと等価です |
| STRING | LONGTEXTと等価です |
| VARCHAR | VARCHARと等価です |
| JSON | JSONと等価です |
| FLOAT_VECTOR | VECTORと等価です |
説明
より複雑な型や制約などについては、obvec_jdbcではなくOceanBase JDBCのインターフェースを使用して自ら作成できます。
インターフェースの定義は以下のとおりです:
API |
説明 |
|---|---|
| String getName() | 列名を取得します。 |
| ObFieldSchema Name(String name) | 列名を設定し、オブジェクト自体を返すことで連鎖操作を可能にします。 |
| ObFieldSchema DataType(DataType dataType) | データ型を設定します。 |
| boolean getIsPrimary() | 主キー列かどうかを示します。 |
| ObFieldSchema IsPrimary(boolean isPrimary) | 主キーであるかどうかを設定します。 |
| ObFieldSchema IsAutoInc(boolean isAutoInc) | 自動インクリメントを設定します。
注意IsAutoIncはIsPrimaryがtrueの場合にのみ有効になります。 |
| ObFieldSchema IsNullable(boolean isNullable) | NULLを許容するかどうかを設定します。
注意IsNullableはデフォルトでfalseであり、MySQLの動作とは異なります。 |
| ObFieldSchema MaxLength(int maxLength) | VARCHAR型の最大長を設定します。 |
| ObFieldSchema Dim(int dim) | VECTOR型の次元数を設定します。 |
IndexParams/IndexParam
IndexParamは単一のインデックスパラメータを設定するために使用されます。IndexParamsはベクトルインデックスパラメータのセットを設定するために使用され、特定のテーブルに複数のベクトルインデックスを作成する場合に使用します。
注意
obvec_jdbcはベクトルインデックスの作成のみをサポートしています。他のインデックスを作成する必要がある場合は、OceanBase JDBCを使用してください。
IndexParamのコンストラクタは以下のとおりです:
# vidx_name:インデックス名
# vector_field_name:ベクトル列名
public IndexParam(String vidx_name, String vector_field_name);
インターフェースの定義は以下のとおりです:
API |
説明 |
|---|---|
| IndexParam M(int m) | HNSWアルゴリズムにおける各ベクトルの最大近傍数を取得します。 |
| IndexParam EfConstruction(int ef_construction) | HNSWアルゴリズムの構築時に検索する最大候補ベクトル数を設定します。 |
| IndexParam EfSearch(int ef_search) | HNSWアルゴリズムでの検索時の最大候補ベクトル数を設定します。 |
| IndexParam Lib(String lib) | 使用するベクトルライブラリのタイプを設定します。 |
| IndexParam MetricType(String metric_type) | ベクトル距離関数のタイプを設定します。 |
IndexParamsのコンストラクタは以下のとおりです:
public IndexParams();
インターフェースの定義は以下のとおりです:
API |
説明 |
|---|---|
| void addIndex(IndexParam index_param) | インデックス定義を追加します。 |
ObCollectionSchemaクラス
テーブル作成時にはObCollectionSchemaオブジェクトの設定に依存するため、まずこのクラスのコンストラクタとインターフェースについて説明します。
ObCollectionSchemaのコンストラクタは以下のとおりです:
public ObCollectionSchema();
インターフェースの定義は以下のとおりです:
API |
説明 |
|---|---|
| void addField(ObFieldSchema field) | 列定義を追加します。 |
| void setIndexParams(IndexParams index_params) | テーブルのベクトルインデックスパラメータを設定します。 |
テーブルの削除
コンストラクタは以下のとおりです:
# table_name:対象テーブル名
public void dropCollection(String table_name);
テーブルの存在チェック
コンストラクタは以下のとおりです:
# table_name:対象テーブル名
public boolean hasCollection(String table_name);
テーブルの作成
コンストラクタは以下のとおりです:
# table_name:対象テーブル名
# collection:ObCollectionSchema型データ構造、テーブルのスキーマ
public void createCollection(String table_name, ObCollectionSchema collection);
ObFieldSchema、OCollectionSchema、およびIndexParamsを使用してテーブルを作成する例は以下のとおりです:
import com.oceanbase.obvec_jdbc.DataType;
import com.oceanbase.obvec_jdbc.ObCollectionSchema;
import com.oceanbase.obvec_jdbc.ObFieldSchema;
import com.oceanbase.obvec_jdbc.IndexParam;
import com.oceanbase.obvec_jdbc.IndexParams;
# テーブルスキーマの定義
ObCollectionSchema collectionSchema = new ObCollectionSchema();
ObFieldSchema c1_field = new ObFieldSchema("c1", DataType.INT32);
c1_field.IsPrimary(true).IsAutoInc(true);
ObFieldSchema c2_field = new ObFieldSchema("c2", DataType.FLOAT_VECTOR);
c2_field.Dim(3).IsNullable(false);
ObFieldSchema c3_field = new ObFieldSchema("c3", DataType.JSON);
c3_field.IsNullable(true);
collectionSchema.addField(c1_field);
collectionSchema.addField(c2_field);
collectionSchema.addField(c3_field);
# インデックスの定義
IndexParams index_params = new IndexParams();
IndexParam index_param = new IndexParam("vidx1", "c2");
index_params.addIndex(index_param);
collectionSchema.setIndexParams(index_params);
ob.createCollection(tb_name, collectionSchema);
ベクトルインデックスの追加作成
コンストラクタは以下のとおりです:
# table_name:対象テーブル名
# index_param:IndexParam型データ構造、テーブルのベクトルインデックスパラメータ
public void createIndex(String table_name, IndexParam index_param)
データの挿入
コンストラクタは以下のとおりです:
# table_name:ターゲットテーブル名
# column_names:ターゲットテーブルの列名配列
# rows:データ行。ArrayList<Sqlizable[]>、各行データはSqlizable配列です。SqlizableはJavaデータ型をSQLデータ型に変換するためのラッピングクラスです。
public void insert(String table_name, String[] column_names, ArrayList<Sqlizable[]> rows);
rowsでサポートされているデータ型は以下のとおりです:
- SqlInteger:Int型のデータをラップします。
- SqlFloat:Float型のデータをラップします。
- SqlDouble:Double型のデータをラップします。
- SqlText:String型のデータをラップします。
- SqlVector:Vector型のデータをラップします。
例:
import com.oceanbase.obvec_jdbc.SqlInteger;
import com.oceanbase.obvec_jdbc.SqlText;
import com.oceanbase.obvec_jdbc.SqlVector;
import com.oceanbase.obvec_jdbc.Sqlizable;
ArrayList<Sqlizable[]> insert_rows = new ArrayList<>();
Sqlizable[] ir1 = { new SqlVector(new float[] {1.0f, 2.0f, 3.0f}), new SqlText("{\"doc\": \"oceanbase doc 1\"}") };
insert_rows.add(ir1);
Sqlizable[] ir2 = { new SqlVector(new float[] {1.1f, 2.2f, 3.3f}), new SqlText("{\"doc\": \"oceanbase doc 2\"}") };
insert_rows.add(ir2);
Sqlizable[] ir3 = { new SqlVector(new float[] {0f, 0f, 0f}), new SqlText("{\"doc\": \"oceanbase doc 3\"}") };
insert_rows.add(ir3);
ob.insert(tb_name, new String[] {"c2", "c3"}, insert_rows);
データの削除
コンストラクタは以下のとおりです:
# table_name:ターゲットテーブル名
# primary_key_name:主キー列名
# primary_keys:ターゲット行の主キー列値配列
public void delete(String table_name, String primary_key_name, ArrayList<Sqlizable> primary_keys);
例:
ArrayList<Sqlizable> ids = new ArrayList<>();
ids.add(new SqlInteger(2));
ids.add(new SqlInteger(1));
ob.delete(tb_name, "c1", ids);
ANNクエリ
コンストラクタは以下のとおりです:
# table_name:ターゲットテーブル名
# vec_col_name:ベクトル列名
# metric_type:ベクトル距離関数のタイプ。l2:l2距離関数に対応します。cosine:cosine距離関数に対応します。ip:negative_inner_product距離関数に対応します。
# qv:クエリ対象のベクトル値
# topk:最も類似した上位k個の結果を返す
# output_fields:投影列、つまり返されるフィールド配列
# output_datatypes:投影列のデータ型、つまり返されるフィールドのデータ型。Javaデータ型への直接変換に使用されます。
# where_expr:WHERE条件式
public ArrayList<HashMap<String, Sqlizable>> query(
String table_name,
String vec_col_name,
String metric_type,
float[] qv,
int topk,
String[] output_fields,
DataType[] output_datatypes,
String where_expr);
例:
ArrayList<HashMap<String, Sqlizable>> res = ob.query(tb_name, "c2", "l2",
new float[] {0f, 0f, 0f}, 10,
new String[] {"c1", "c3", "c2"},
new DataType[] {
DataType.INT32,
DataType.JSON,
DataType.FLOAT_VECTOR,
"c1 > 0"});
if (res != null) {
for (int i = 0; i < res.size(); i++) {
for (HashMap.Entry<String, Sqlizable> entry : res.get(i).entrySet()) {
System.out.printf("%s : %s, ", entry.getKey(), entry.getValue().toString());
}
System.out.print("\n");
}
} else {
System.out.println("res is null");
}
JSONテーブル機能の使用
obvec_jdbc の JSONテーブル機能は、OceanBase の JSON データ型に対する操作処理能力(JSON_VALUE/JSON_TABLE/JSON_REPLACE などを含む)に依存しており、仮想テーブルメカニズムを実装しています。複数のユーザー(ユーザーIDで区別)が同一の物理テーブル上で仮想テーブルに対するDDLまたはDML操作を実行できると同時に、ユーザー間のデータ分離を保証します。管理者ユーザーはDDL操作を、一般ユーザーはDML操作を実行できます。
この設計は、リレーショナルデータベースの構造的な管理能力とJSONの柔軟性を組み合わせており、OceanBaseデータベースのマルチモーダル統合能力を体現しています。ユーザーはSQLの強力な機能と使いやすさを享受しつつ、半構造化データも処理できるため、現代のアプリケーションが求める多様なデータモデルに対応できます。操作対象は依然として「テーブル」ですが、基盤となるストレージではより柔軟なJSON形式でデータを格納できるため、複雑で多様なアプリケーションシナリオをより効果的にサポートできます。
原理の説明
ここでは、原理図を用いてJSONテーブルの仕組みを説明します。
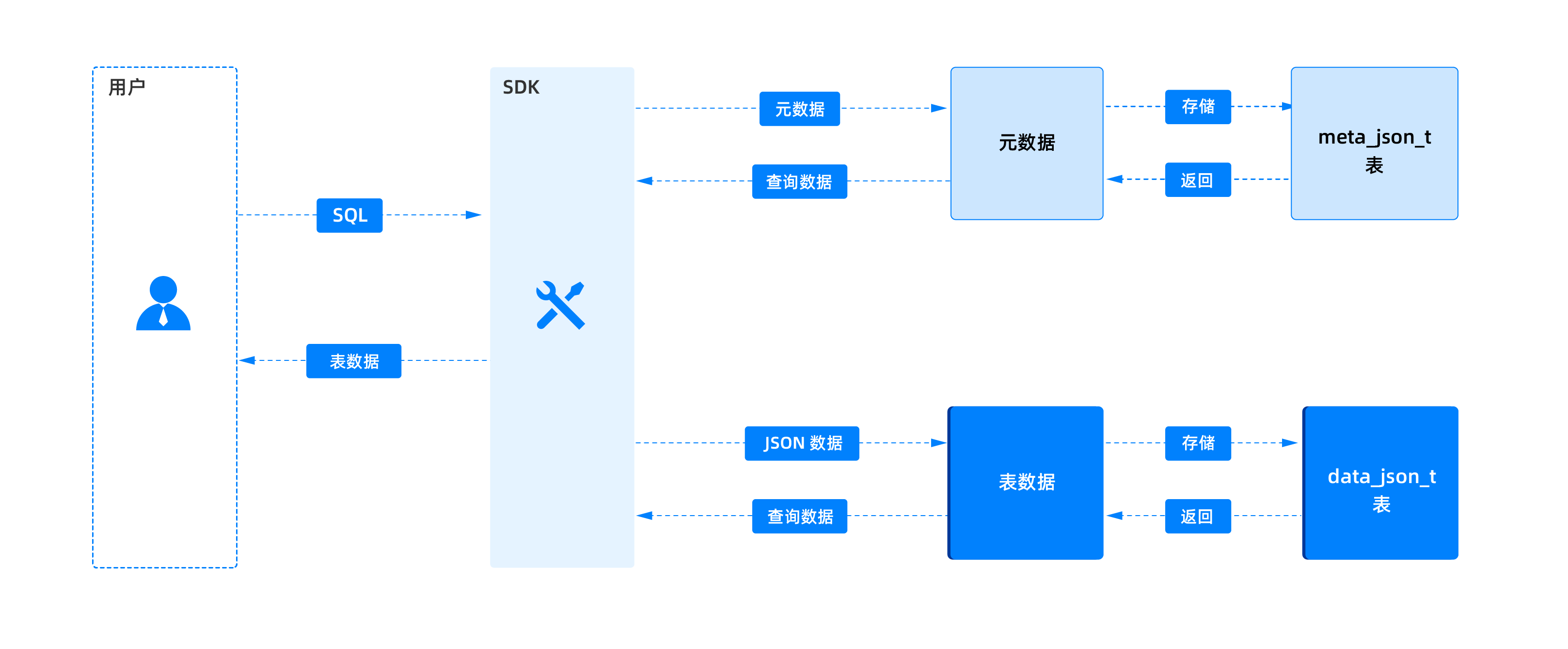
具体的な説明は以下の通りです:
ユーザー操作:ユーザーは引き続き、慣れ親しんだ標準SQL文(例えば
CREATE TABLEでテーブル構造を作成、INSERTでデータを挿入、SELECTでデータをクエリする)を使用してシステムとやり取りします。データが下層でどのように保存されているかを気にする必要はなく、通常のリレーショナルデータベースのテーブルを操作するのと同じです。ユーザーがSQL文で作成するテーブルは論理テーブルであり、OceanBaseデータベース内部ではmeta_json_tとdata_json_tの2つの物理テーブルに対応します。JSON Table SDK:アプリケーション内部には、JSON Table SDK(ソフトウェア開発キット)が存在します。このSDKは、ユーザーのSQL操作とOceanBaseデータベースの実際のストレージをつなぐ鍵となります。SQL文が実行されると、SDKはこれらのリクエストを傍受し、賢明にもそれらをOceanBaseデータベース内部のテーブル
meta_json_tおよびdata_json_tへの読み書き操作に変換します。OceanBaseデータベース内部:
meta_json_t(テーブル構造の保存):ユーザーが作成した論理テーブルのメタデータ、すなわちテーブルの構造情報(例えば、作成したテーブルにはどのような列があり、各列のデータ型は何か)を保存するために使用されます。CREATE TABLEを実行すると、SDKはこれらの構造情報をmeta_json_tに記録します。data_json_t(行データをJSON型で保存):実際に挿入されたデータを保存するために使用されます。従来のリレーショナルデータベースが直接行データを保存するのとは異なり、JSON Table機能は挿入された各行データをJSONオブジェクトにカプセル化し、data_json_tテーブルの特定の列に保存します。このようにすることで、データ構造が柔軟であっても効率的に保存できます。
- データクエリ:
SELECTなどのクエリ操作を実行すると、SDKはdata_json_tからJSON形式のデータを読み取り、meta_json_tのテーブル構造情報と組み合わせて、これらのJSONデータを再解析し、ご存知のテーブル形式でアプリケーションに返します。
meta_json_t テーブルは、JSONテーブルのメタデータ情報、すなわちユーザーが CREATE TABLE で定義した論理テーブル構造を保存します。それは各論理テーブルの列情報を記録しており、テーブル構造は以下の通りです:
フィールド名 |
説明 |
例 |
|---|---|---|
user_id |
ユーザーID。異なるユーザーの論理テーブルを区別するために使用されます。 | 0, 1, 2 |
jtable_name |
論理テーブルの名前。 | test_count |
jcol_id |
論理テーブル内の列ID。 | 1, 2, 3 |
jcol_name |
論理テーブル内の列名。 | c1, c2, c3 |
jcol_type |
列のデータ型。 | INT, VARCHAR(124), DECIMAL(10,2) |
jcol_nullable |
列がNULLを許容するかどうか。 | 0, 1 |
jcol_has_default |
列にデフォルト値があるかどうか。 | 0, 1 |
jcol_default |
列のデフォルト値。 | {'default': null} |
ユーザーが CREATE TABLE を実行すると、JSON Table SDKはこれらの列定義情報を解析し、meta_json_t テーブルに挿入します。
data_json_t テーブルは、JSONテーブルの実際のデータ、すなわちユーザーが INSERT で挿入したデータを保存します。それは各論理テーブルの行データを記録しており、テーブル構造は以下の通りです:
フィールド名 |
説明 |
例 |
|---|---|---|
user_id |
ユーザーID。異なるユーザーの論理テーブルを区別するために使用されます。 | 0, 1, 2 |
admin_id |
管理者ユーザーID。 | 0 |
jtable_name |
論理テーブルの名前。meta_json_t のメタデータと関連付けるために使用されます。 |
test_count |
jdata_id |
データID。JSONデータの一意の識別子で、論理テーブル内の各行に対応します。 | 1, 2, 3 |
jdata |
JSON型の列です。論理テーブル内の実際の行データを格納するために使用されます。 | {"c1": 1, "c2": "test", "c3": 1.23} |
使用例
クライアントの作成
コンストラクタは以下のとおりです:
# uri:接続文字列。アドレス、ポート、接続するデータベース名などを含みます。 # user:ユーザー名 # password:パスワード # user_id:ユーザーID # log_level:ログレベル public ObVecJsonClient(String uri, String user, String password, String user_id, Level log_level);例:
import com.oceanbase.obvec_jdbc.ObVecJsonClient; String uri = "jdbc:oceanbase://127.0.0.1:2881/test"; String user = "root@test"; String password = ""; ObVecJsonClient client = new ObVecJsonClient(uri, user, password, 0, Level.INFO);DDLステートメントの実行
parseJsonTableSQL2NormalSQLインターフェースを直接呼び出し、具体的なSQLステートメントを渡すことで使用できます。テーブルの作成
String sql = "CREATE TABLE `t2` (c1 INT NOT NULL DEFAULT 10, c2 VARCHAR(30) DEFAULT 'ca', c3 VARCHAR NOT NULL, c4 DECIMAL(10, 2), c5 TIMESTAMP DEFAULT CURRENT_TIMESTAMP);"; client.parseJsonTableSQL2NormalSQL(sql);ALTER TABLE CHANGE COLUMN
sql = "ALTER TABLE t2 CHANGE COLUMN c2 changed_col INT"; client.parseJsonTableSQL2NormalSQL(sql);ALTER TABLE ADD COLUMN
sql = "ALTER TABLE t2 ADD COLUMN email VARCHAR(100) default 'example@example.com'"; client.parseJsonTableSQL2NormalSQL(sql);ALTER TABLE MODIFY COLUMN
sql = "ALTER TABLE t2 MODIFY COLUMN changed_col TIMESTAMP NOT NULL DEFAULT current_timestamp"; client.parseJsonTableSQL2NormalSQL(sql);ALTER TABLE DROP COLUMN
sql = "ALTER TABLE t2 DROP c1"; client.parseJsonTableSQL2NormalSQL(sql);ALTER TABLE RENAME
sql = "ALTER TABLE t2 RENAME TO alter_test"; client.parseJsonTableSQL2NormalSQL(sql);