


データベースの運用保守シナリオにおいて、CPU 使用率が高すぎる、または偏っていることは非常に一般的です。このようなシナリオが発生する原因は、主に以下の2つの方向性があります:
一つ目は、クラスタ環境の異常によるCPU異常です。例えば、ネットワークカードの終端、ディスク障害、ドライバ障害、サードパーティサービス(セキュリティサービスなど)により、OBServerが配置されているノードの一部のCPUリソースが他のプロセスに奪われ、モニタリング上でノードのCPU異常として表示される場合です。
二つ目は、observerプロセス自体が過剰なCPUリソースを占有している場合です。例えば、SQL実行、リモート実行、バックグラウンドスレッド、またはRPC実行などが該当します。
CPU異常が検出されたシナリオでは、まずLinuxシステム監視ツール(例:tsarなど)を使用して、第一の問題を除外する必要があります。本記事では、主に第二の問題、つまりobserverプロセスがなぜ多くのCPUリソースを占有しているのかを特定するトラブルシューティングに焦点を当てます。
CPU使用率が高すぎる、または偏っている問題のトラブルシューティングを行う前に、一般的なトラブルシューティングの考え方と一般的な原因を概説します。
ASH Reportのフロントエンドおよびバックエンド負荷を確認し、以下のシナリオの根本原因を特定します:
テナントのLeaderノードがより多くの内部RPC/inner SQLリクエストを受信し、CPUホットスポットが発生しています。
トラブルシューティングの考え方:ASH Reportのバックエンド負荷を確認し、内部RPC/inner SQLがどのように生成されるかを特定し、SQL次元と関連付けて分析します。
PX並列実行の並列度設定が不適切で、CPUが爆発的に増加しています。
トラブルシューティングの考え方:ASH Reportでは、ほとんどのデータベースタスクがPX並列実行に関連していることが確認できます。SQL次元と関連付けて分析し、並列度を調整します。
ダンプマージを代表とする一連のバックグラウンドタスクが過剰なCPUリソースを消費しています。
トラブルシューティングの考え方:ASH Reportのバックエンド負荷を確認し、内部RPC/inner SQLがどのように生成されるかを特定し、SQL次元と関連付けて分析します。
OceanBaseデータベース内部のリトライイベントが過剰なCPUリソースを消費しています。
トラブルシューティングの考え方:ASH Reportのretryカテゴリの待機イベントを確認し、SQL次元と関連付けて分析します。
ASH Reportを詳細に分析し、以下のシナリオの根本原因を特定します:
ODPルーティングエラーにより、SQLトラフィックが一つのノードに集中しています。
トラブルシューティングの考え方:ASH Reportのフロントエンドおよびバックエンド負荷を確認し、フロントエンド負荷が一つのノードに集中しているか、バックエンド負荷に
ActionがOB_REMOTE_SYNC_EXECUTEのイベントのオーバーヘッドが多いかどうかを確認します。さらにGV$OB_SQL_AUDITのpartition_hit関連列を確認し、ODPルーティングがヒットしているかどうかを確認します。テーブル構造の分布が不均一で、SQL負荷が偏っています。
トラブルシューティングの考え方:フロントエンドおよびバックエンド負荷を確認し、ホットノードやテナントなどを特定した後、ASH Reportデータ内のtablet_idアクセス状況を確認し、アクセス回数が最も高いtablet_idを特定して均等化します。
頻繁に使用されるアカウントにより、ユーザーSQLが特定のパーティションで熱くなっています。
トラブルシューティングの考え方:頻繁に使用されるアカウントに対応するパーティションデータを分析し、データ分布を適切に計画します。
CPU使用率の偏りに関するトラブルシューティングのフローチャートは以下のとおりです。
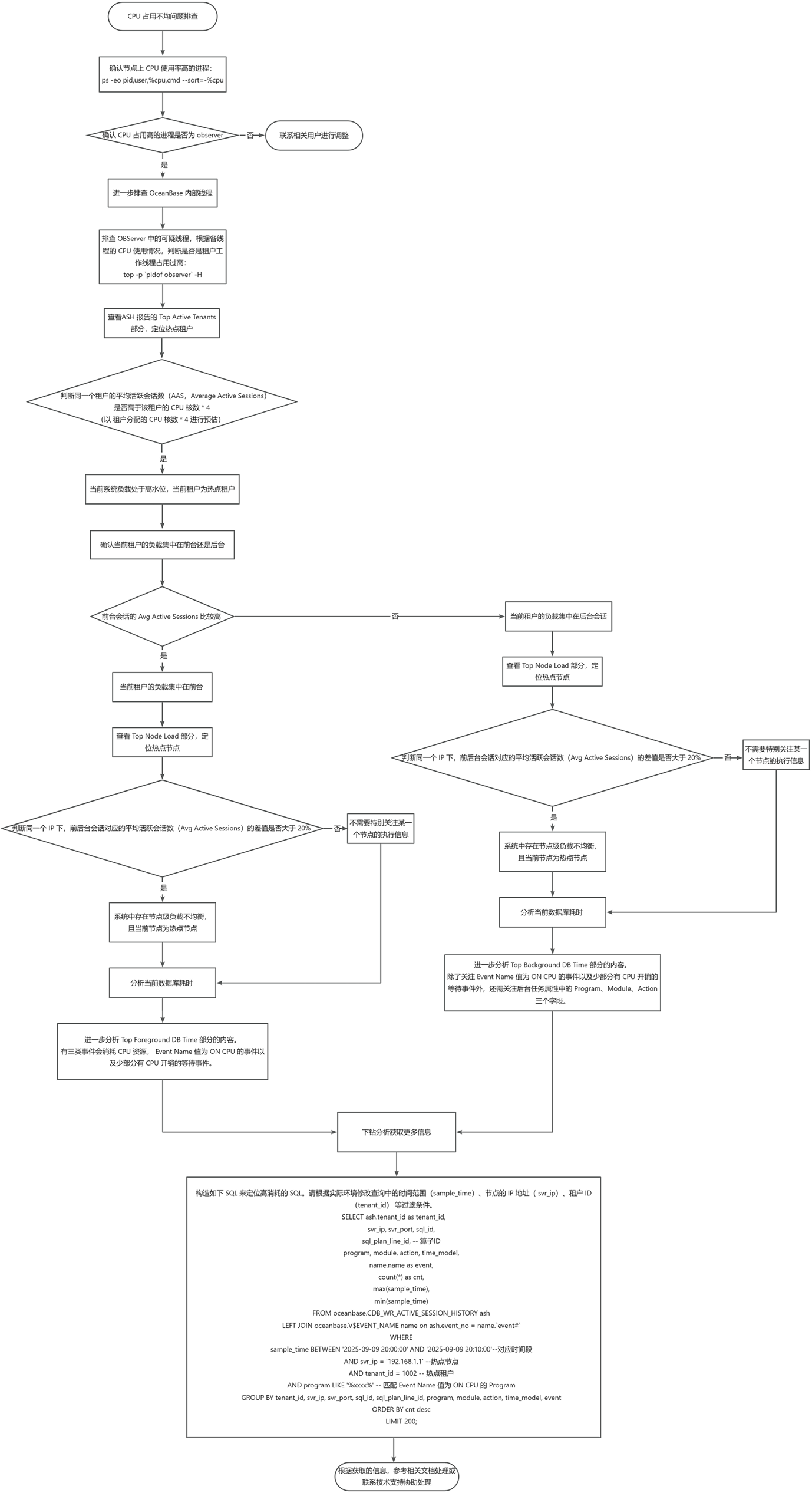
プロセスの概要
ステップ1:ノード上のCPU使用率が高いプロセスがobserverプロセスであることを確認する
問題の調査を開始する前に、指定したノード上でCPU使用率が高いプロセスがobserverプロセスであるかどうかを確認します。ステートメントは以下のとおりです。
ps -eo pid,user,%cpu,cmd --sort=-%cpu
出力例は次のとおりです:
PID USER %CPU CMD
124648 user_a 99.9 other_process
1332 user_b 50.5 observer
実行結果に基づいて:
CPU使用率が高いプロセスがobserverである場合は、OceanBaseの内部スレッドについてさらに調査する必要があります。
他のプロセス(other_processなど)の場合は、関連するユーザーに連絡して調整を依頼する必要があります。
ステップ2:OceanBaseの内部スレッドの調査
OBServer内の疑わしいスレッドの調査。
observerプロセスのCPU使用率が高い場合、以下のコマンドでスレッド状況を確認できます:
top -p `pidof observer` -Hこのコマンドはobserverプロセス内の各スレッドのCPU使用状況を表示し、テナントのワーカースレッドが過剰にCPUを占有しているかどうかを判断するのに役立ちます。
ASH Reportに基づき、全体の負荷を確認し、ホットなテナントを特定します。
ASH ReportのTop Active Tenantsセクションを確認し、該当する情報に基づいてホットなテナントを特定します。
同一テナントの平均アクティブセッション(
Average Active Sessions)が、そのテナントのCPUコア数 * 4(テナントに割り当てられたCPUコア数 * 4で推定)よりも高いかどうかを判断します:Average Active Sessionsが高い場合、現在のシステム負荷が高い状態にあり、該当テナントがホットなテナントであることを意味します。次に、現在のテナントの負荷がフロントエンドに集中しているかバックグラウンドに集中しているかを判断します。
フロントエンドセッションの
Avg Active Sessionsが高い場合、現在のテナントの負荷がフロントエンドセッションに集中していることを意味します。バックグラウンドセッションの
Avg Active Sessionsが高い場合、現在のテナントの負荷がバックグラウンドセッションに集中していることを意味します。
ホットノードの特定。
ASH ReportのTop Node Loadセクションを確認し、同一IPアドレス下のフロントエンドおよびバックグラウンドセッションに対応する平均アクティブセッション数(Avg Active Sessions)の差が20%を超えるかどうかを判断することで、現在のノードがホットノードであるかどうかを判断します。
もしそうであれば、システム内にノードレベルの負荷不均衡が存在することを意味します。
そうでない場合、特定のノードの実行情報に特別な注意を払う必要はありません。
データベースの処理時間の分析。
ホットなテナントまたはホットなノードを特定した後、現在のデータベース処理時間を分析できます。
負荷がフロントエンドセッションに集中している場合、Top Foreground DB Timeセクションの内容をさらに分析する必要があります。
フロントエンドセッションでは、3種類のイベントがCPUリソースを消費します。
Event Nameの値がON CPUのイベント、および少数のCPUオーバーヘッドを伴う待機イベントです。その中で:ON CPU:データベースは、現在のセッションがCPUリソースを消費してタスクを処理していると判断しています。待機イベント:
retryで始まる待機イベント:OceanBaseデータベース内部で何らかのタイプの再試行が行われていることを示し、OceanBaseデータベースの内部再試行メカニズムは一部のCPUリソースを消費します。exec inner sql wait:実行プロセス中に発生した内部テーブルへのアクセスSQLの結果が返されることを示します。例えば、ユーザーテーブルの位置やスキーマ情報を取得する場合などです。このプロセスも一部のCPUリソースを消費します。
負荷がバックグラウンドセッションに集中している場合、Top Background DB Timeセクションの内容をさらに分析する必要があります。
バックグラウンドセッションでは、フロントエンドセッションで述べた3種類のイベントに加え、バックグラウンドタスクの属性にも注意を払う必要があります。
Program、Module、Actionの3つのフィールドはバックグラウンドタスクの属性を示しています:Actionフィールドの値がOB_DAS_ASYNC_ACCESSに対応する場合、バックグラウンドタスクはSQLリモートDAS実行であることを意味します。Programフィールドの値がxxx_PxPoolのようなものに対応する場合、バックグラウンドタスクはPX並列実行であることを意味します。Programフィールドの値がxxx_DAGのようなものに対応する場合、バックグラウンドタスクはダンプマージタスクであることを意味します。Programフィールドの値がxxx_RPC_REQUESTのようなものに対応する場合、バックグラウンドタスクはOBServerノード内部から送信されるRPCタスクであることを意味します。
説明
以上が一般的なバックグラウンドタスクのタイプですが、それ以外にも100種類以上のバックグラウンドタスクのタイプがあります。
上記の分析を経て、CPUオーバーヘッドが主に集中しているノード、テナント、および具体的なタスクタイプを明確にすることができ、データベースシステムの主要なCPUオーバーヘッドがどこにあるかを基本的に確認できました。通常、上記の調査手順だけで問題の大まかな方向性や潜在的なボトルネックを特定するのに役立ちます。しかし、一部のシナリオでは、さらに詳細な分析を進めてより多くの情報を取得したい場合があります。
前述の分析に基づき、バックグラウンドタスクのオーバーヘッドが主にPXまたはDAS実行によるものである場合、対応するsql_idが何であるかを知る必要があります。以下のSQLを構築してクエリを実行できます。
説明
実際の環境に応じて、クエリ内の時間範囲(
sample_time)、ノードのIPアドレス(svr_ip)、テナントID(tenant_id)などのフィルター条件を変更してください。obclient(root@sys)[oceanbase]> SELECT ash.tenant_id as tenant_id, svr_ip, svr_port, sql_id, sql_plan_line_id, -- 演算子ID program, module, action, time_model, name.name as event, count(*) as cnt, max(sample_time), min(sample_time) FROM oceanbase.CDB_WR_ACTIVE_SESSION_HISTORY ash LEFT JOIN oceanbase.V$EVENT_NAME name on ash.event_no = name.`event#` WHERE sample_time BETWEEN '2025-09-09 20:00:00' AND '2025-09-09 20:10:00'--対応する時間帯 AND svr_ip = '192.168.1.1' --ホットノード AND tenant_id = 1002 -- ホットテナント AND program LIKE '%xxxx%' -- Event Nameの値がON CPUのProgramに一致するものをフィルタリング GROUP BY tenant_id, svr_ip, svr_port, sql_id, sql_plan_line_id, program, module, action, time_model, event ORDER BY cnt desc LIMIT 200;以下にいくつかの例を挙げて説明します。
例1:
*_SQL_CMDは、現在のデータベースのユーザーSQLリクエストが過剰なCPUリソースを消費していることを示しており、根本原因はデータ分布の不均衡やODPルーティングエラーなどが考えられます。以下のSQLを使用して、高消費SQLを特定できます。
obclient(root@sys)[oceanbase]> SELECT ash.tenant_id as tenant_id, svr_ip, svr_port, sql_id, sql_plan_line_id, -- 演算子ID program, module, action, time_model, name.name as event, count(*) as cnt, max(sample_time), min(sample_time) FROM oceanbase.CDB_WR_ACTIVE_SESSION_HISTORY ash LEFT JOIN oceanbase.V$EVENT_NAME name on ash.event_no = name.`event#` WHERE sample_time BETWEEN '2025-09-09 20:00:00' AND '2025-09-09 20:10:00' AND svr_ip = '192.168.1.1' AND tenant_id = 1002 AND program LIKE '%_SQL_CMD%' -- ユーザーSQLリクエストをフィルタリング GROUP BY tenant_id, svr_ip, svr_port, sql_id, sql_plan_line_id, program, module, action, time_model, event ORDER BY cnt desc LIMIT 200;例2:
*_RPC_PROCESS*は、RPCリクエストの処理に過剰なCPUリソースが消費されていることを示しており、根本原因はダンプマージを代表とする一連のバックグラウンドタスクが過剰なCPUリソースを消費していることが考えられます。テナントのリーダーノードは、より多くの内部rpc/inner sqlリクエストを受信します。以下のSQLを使用して、高消費SQLを特定できます。
obclient(root@sys)[oceanbase]> SELECT ash.tenant_id as tenant_id, svr_ip, svr_port, sql_id, program, module, action, time_model, name.name as event, count(*) as cnt, max(sample_time), min(sample_time) FROM oceanbase.CDB_WR_ACTIVE_SESSION_HISTORY ash LEFT JOIN oceanbase.V$EVENT_NAME name on ash.event_no = name.`event#` WHERE sample_time BETWEEN '2025-09-09 20:00:00' AND '2025-09-09 20:10:00' AND svr_ip = '192.168.1.100' AND tenant_id = 1 AND (program LIKE '%_RPC_PROCESS%') GROUP BY tenant_id, svr_ip, svr_port, sql_id, program, module, action, time_model, event ORDER BY cnt desc LIMIT 200;例3:
*PX*または*_DAS_*は、リモート実行に過剰なCPUリソースが消費されていることを示しており、根本原因はPX並列実行の並列度設定が不適切であることが考えられます。以下のSQLを使用して、高消費SQLを特定できます。
obclient(root@sys)[oceanbase]> SELECT ash.tenant_id as tenant_id, svr_ip, svr_port, sql_id, program, module, action, time_model, name.name as event, count(*) as cnt, max(sample_time), min(sample_time) FROM oceanbase.CDB_WR_ACTIVE_SESSION_HISTORY ash LEFT JOIN oceanbase.V$EVENT_NAME name on ash.event_no = name.`event#` WHERE sample_time BETWEEN '2025-09-09 20:00:00' AND '2025-09-09 20:10:00' AND svr_ip = '192.168.1.1' AND tenant_id = 1002 AND (IN_PX_EXECUTION = 'Y' or IN_REMOTE_DAS_EXECUTION = 'Y') GROUP BY tenant_id, svr_ip, svr_port, sql_id, program, module, action, time_model, event ORDER BY cnt desc LIMIT 200;
取得した情報に基づき、関連ドキュメントを参照して処理するか、テクニカルサポートに連絡して支援を求めます。