


このドキュメントでは、OceanBaseのベクトル検索を使用したAIアプリケーションのワークフローについて説明します。
AIアプリケーションのワークフロー図
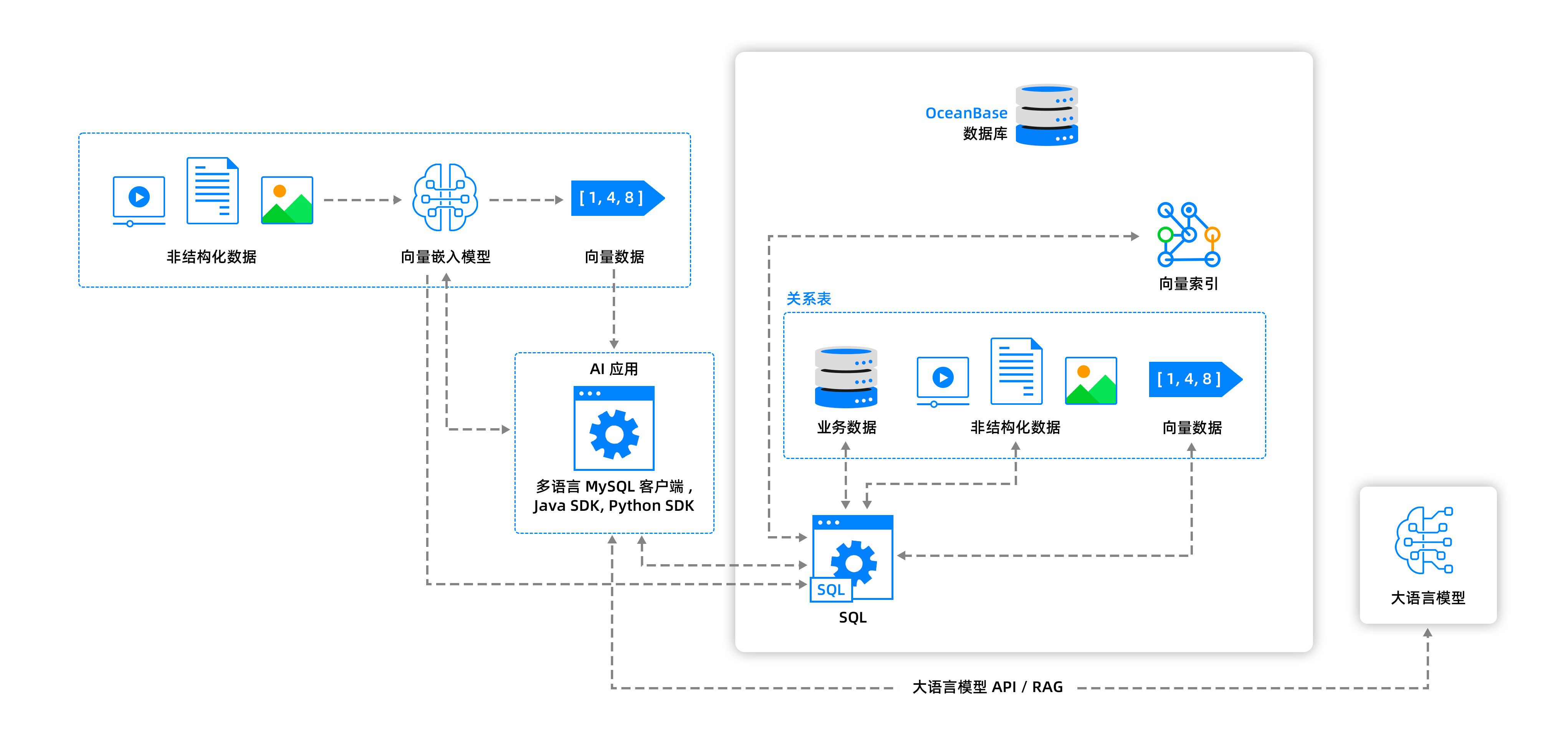
このアーキテクチャ図は、従来のリレーショナルデータベースの機能と高度なベクトル検索および大規模言語モデル技術を組み合わせた、典型的な現代のAIアプリケーションパターンを示しています。これにより、マルチモーダルデータのインテリジェントな処理と効率的な活用が実現されます。OceanBaseデータベースは、その中で重要な役割を果たし、強力なデータストレージとベクトル検索機能を提供することで、このようなAIアプリケーションを構築するための堅固な基盤を築きます。
主要なステップの解説
1. 非構造化データをベクトル埋め込み処理により特徴ベクトルに変換する
非構造化データ(ビデオ、ドキュメント、画像など)は、ワークフローの起点です。ビデオ、テキストファイル(ドキュメント)、画像など、さまざまな形式の非構造化データは、ベクトル埋め込みモデルによってベクトルデータ表現に変換されます。このモデルのタスクは、類似度を直接計算することが困難なこれらの元の非構造化データを、高次元のベクトルデータ(Vectors)に変換することです。これらのベクトルはデータの意味情報と特徴を捉えることができ、ベクトル空間上の距離によってデータの類似度を表現することができます。詳細については、ベクトル埋め込み技術を参照してください。
2. OceanBaseデータベースにベクトル埋め込みを格納し、ベクトルインデックスを作成する
コアストレージ層として、OceanBaseデータベースはすべてのデータの保存を担当します。これには、従来のリレーショナルテーブル(業務データの保存に使用)だけでなく、元の非構造化データおよびベクトル埋め込み後に生成されたベクトルデータも含まれます。詳細については、ベクトルデータの保存を参照してください。
効率的なベクトル検索を実現するために、OceanBaseデータベースはベクトルデータに対してベクトルインデックスを構築します。ベクトルインデックスは、高次元ベクトル空間における最近傍探索を大幅に高速化するための専用のデータ構造です。ベクトル類似度計算のコストは高いため、厳密検索(すべてのベクトルの距離を順次計算する方法)は結果の正確性を保証しますが、クエリ性能を急激に低下させます。ベクトルインデックスを使用することで、システムは候補ベクトルを迅速に特定し、距離を計算する必要があるベクトルの数を大幅に削減することができます。これにより、高い精度を維持しつつ、クエリ効率を大幅に向上させることができます。詳細については、ベクトルインデックスを参照してください。
3. SQL/SDKを使用して最近傍探索およびハイブリッド検索を実行する
ユーザーはクライアントまたはプログラミング言語を通じてAIアプリケーションと対話し、クエリリクエストを送信します。これらのリクエストは、テキスト、画像、その他の形式を含む場合があります。詳細については、サポートされているクライアントと言語を参照してください。
OceanBaseはSQL文を使用してリレーショナルデータのクエリと管理を行い、スカラーデータとベクトルデータのハイブリッド検索を実現します。ユーザーがクエリを発行した際、それが非構造化クエリである場合、システムはまずベクトル埋め込みモデルを使用してそれをベクトルに変換します。その後、システムはベクトルインデックスおよびスカラーインデックスを活用して、クエリベクトルに最も類似し、かつスカラーフィルタ条件を満たすベクトルデータを迅速に検索し、最も関連性の高い非構造化データを見つけ出します。最近傍探索の詳細については、最近傍探索を参照してください。
4. プロンプトを生成し、LLMに送信して推論を完了する
最終段階では、ハイブリッド検索の結果を基に最適化されたプロンプト(Prompt)を生成し、大規模言語モデル(LLM)に送信して完全な推論プロセスを実行します。LLMはこれらのコンテキスト情報に基づいて、自然言語の応答を生成します。LLMとベクトル埋め込みモデルの間にはフィードバックループが存在し、これによりLLMの出力やユーザーフィードバックを用いてベクトル埋め込みモデルを最適化し、継続的な学習と改善の閉ループを形成することが可能になります。