

実行計画(Execution Plan)とは、データベース内でのSQLクエリ文の実行プロセスを記述したものです。
ユーザーは EXPLAIN コマンドを使用して、指定されたSQLに対してオプティマイザが生成した論理的な実行計画を確認することができます。特定のSQLのパフォーマンス問題を分析する場合、通常はまずそのSQLの実行計画を確認し、各ステップでの実行に問題がないかどうかを調査する必要があります。したがって、実行計画を理解することはSQL最適化の前提条件であり、実行計画の演算子を理解することが EXPLAIN コマンドを理解する鍵となります。
EXPLAINコマンドの形式
OceanBaseデータベースの実行計画コマンドには、EXPLAIN BASIC、EXPLAIN、EXPLAIN EXTENDED の3つのモードがあります。これら3つのモードでは、実行計画に対して異なる粒度の詳細情報を表示します:
EXPLAIN BASICコマンドは、最も基本的な計画表示に使用されます。EXPLAIN EXTENDEDコマンドは、最も詳細な計画表示に使用されます(通常、問題のトラブルシューティング時にこの表示モードが使用されます)。EXPLAINコマンドで表示される情報は、一般ユーザーが計画全体の実行方法を理解するのに役立ちます。
EXPLAIN コマンドの形式は以下のとおりです:
EXPLAIN [BASIC | EXTENDED | PARTITIONS | FORMAT = format_name] [PRETTY | PRETTY_COLOR] explainable_stmt
format_name:
{ TRADITIONAL | JSON }
explainable_stmt:
{ SELECT statement
| DELETE statement
| INSERT statement
| REPLACE statement
| UPDATE statement }
EXPLAIN コマンドは SELECT、DELETE、INSERT、REPLACE、UPDATE ステートメントに適用され、オプティマイザーが提供するステートメント実行計画に関する情報を表示します。これには、そのステートメントをどのように処理するか、テーブルをどのように結合するか、またどの順序で結合するかなどの情報が含まれます。
一般的に、EXPLAIN EXTENDED コマンドを使用して、テーブルスキャンの範囲セグメントを表示できます。EXPLAIN OUTLINE コマンドを使用すると、アウトライン情報を表示できます。
FORMAT オプションは出力フォーマットを選択するために使用できます。TRADITIONAL はテーブル形式で出力を表示することを意味し、これがデフォルト設定でもあります。JSON は JSON フォーマットで情報を表示することを意味します。
EXPLAIN PARTITIONS を使用して、パーティションテーブルに関連するクエリをチェックすることもできます。パーティション化されていないテーブルに対するクエリをチェックする場合、エラーは発生しませんが、PARTITIONS 列の値は常に NULL になります。
複雑な実行計画については、PRETTY または PRETTY_COLOR オプションを使用して、計画ツリー内の親ノードと子ノードをツリーラインまたはカラーツリーラインで接続し、実行計画の表示を読みやすくすることができます。例:
obclient> CREATE TABLE p1table(c1 INT ,c2 INT) PARTITION BY HASH(c1) PARTITIONS 2;
Query OK, 0 rows affected
obclient> CREATE TABLE p2table(c1 INT ,c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
Query OK, 0 rows affected
obclient> EXPLAIN EXTENDED PRETTY_COLOR SELECT * FROM p1table p1 JOIN p2table p2 ON p1.c1=p2.c2\G
*************************** 1. row ***************************
Query Plan: ==========================================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
----------------------------------------------------------
|0 |PX COORDINATOR | |1 |278 |
|1 | EXCHANGE OUT DISTR |:EX10001|1 |277 |
|2 | HASH JOIN | |1 |276 |
|3 | ├PX PARTITION ITERATOR | |1 |92 |
|4 | │ TABLE SCAN |P1 |1 |92 |
|5 | └EXCHANGE IN DISTR | |1 |184 |
|6 | EXCHANGE OUT DISTR (PKEY)|:EX10000|1 |184 |
|7 | PX PARTITION ITERATOR | |1 |183 |
|8 | TABLE SCAN |P2 |1 |183 |
==========================================================
Outputs & filters:
-------------------------------------
0 - output([INTERNAL_FUNCTION(P1.C1, P1.C2, P2.C1, P2.C2)]), filter(nil)
1 - output([INTERNAL_FUNCTION(P1.C1, P1.C2, P2.C1, P2.C2)]), filter(nil), dop=1
2 - output([P1.C1], [P2.C2], [P1.C2], [P2.C1]), filter(nil),
equal_conds([P1.C1 = P2.C2]), other_conds(nil)
3 - output([P1.C1], [P1.C2]), filter(nil)
4 - output([P1.C1], [P1.C2]), filter(nil),
access([P1.C1], [P1.C2]), partitions(p[0-1])
5 - output([P2.C2], [P2.C1]), filter(nil)
6 - (#keys=1, [P2.C2]), output([P2.C2], [P2.C1]), filter(nil), dop=1
7 - output([P2.C1], [P2.C2]), filter(nil)
8 - output([P2.C1], [P2.C2]), filter(nil),
access([P2.C1], [P2.C2]), partitions(p[0-3])
1 row in set
実行計画の形状と演算子情報
OceanBaseデータベースの実行計画は以下のように表示されます:
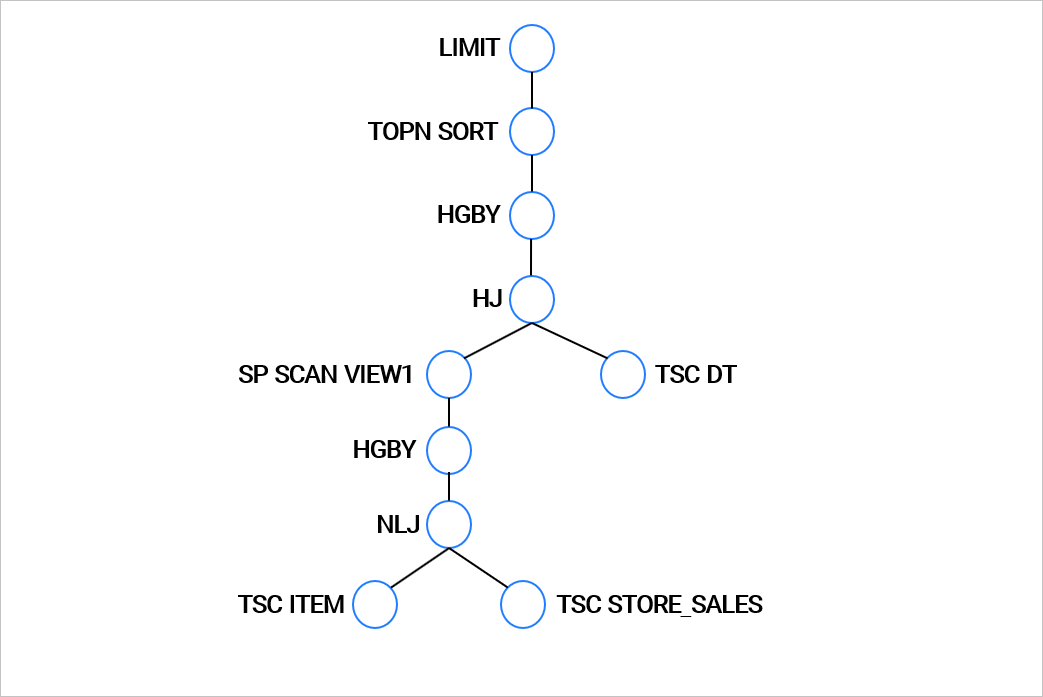
|ID|OPERATOR |NAME |EST. ROWS|COST |
-------------------------------------------------------
|0 |LIMIT | |100 |81141|
|1 | TOP-N SORT | |100 |81127|
|2 | HASH GROUP BY | |2924 |68551|
|3 | HASH JOIN | |2924 |65004|
|4 | SUBPLAN SCAN |VIEW1 |2953 |19070|
|5 | HASH GROUP BY | |2953 |18662|
|6 | NESTED-LOOP JOIN| |2953 |15080|
|7 | TABLE SCAN |ITEM |19 |11841|
|8 | TABLE SCAN |STORE_SALES|161 |73 |
|9 | TABLE SCAN |DT |6088 |29401|
=======================================================
例から分かるように、OceanBaseデータベースの計画表示はOracleデータベースと似ています。OceanBaseデータベースの実行計画における各列の意味は、以下の表に示されています。
| 列名 | 意味 |
|---|---|
| ID | 実行木が先祖順にトラバースした際の番号(0から始まる)。 |
| OPERATOR | 演算子の名前。 |
| NAME | 対応するテーブル操作のテーブル名(インデックス名)。 |
| EST. ROWS | この演算子の出力行数の推定値。 |
| COST | この演算子の実行コスト(マイクロ秒)。 |
説明
テーブル操作において、NAMEフィールドにはその操作に関連するテーブルの名前(エイリアス)が表示されます。インデックスを使用してアクセスする場合は、名前の後にそのインデックスの名前も括弧内で表示されます。例えば、t1(t1_c2)はインデックスt1_c2が使用されていることを示します。スキャンの順序が逆順である場合は、後ろにRESERVEキーワードを使用して識別されます。例えば、t1(t1_c2,RESERVE)のようになります。
OceanBaseデータベースのEXPLAINコマンド出力の最初の部分は、実行計画のツリー構造表示です。ツリー内の各操作の階層は、演算子内でのインデントによって示されます。ツリーの階層関係はインデントで表され、階層が最も深いものが優先的に実行され、階層が同じ演算子は指定された演算子の実行順序に従って実行されます。
上記の例のクエリの計画表示ツリーは、以下の図のとおりです。
OceanBaseデータベースのEXPLAINコマンド出力の2番目の部分は、各操作演算子の詳細情報であり、出力式、フィルタ条件、パーティション情報、および各演算子固有の情報(ソートキー、結合キー、プッシュダウン条件などを含む)が含まれます。例:
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil), sort_keys([t1.c1, ASC], [t1.c2, ASC]), prefix_pos(1)
1 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil),
equal_conds([t1.c1 = t2.c2]), other_conds(nil)
2 - output([t2.c1], [t2.c2]), filter(nil), sort_keys([t2.c2, ASC])
3 - output([t2.c2], [t2.c1]), filter(nil),
access([t2.c2], [t2.c1]), partitions(p0)
4 - output([t1.c1], [t1.c2]), filter(nil),
access([t1.c1], [t1.c2]), partitions(p0)