

ディストリビューション実行の概要
OceanBaseデータベースは、Shared-Nothing型の分散システムに基づいて構築されており、ディストリビューション実行計画の生成と実行機能を備えています。
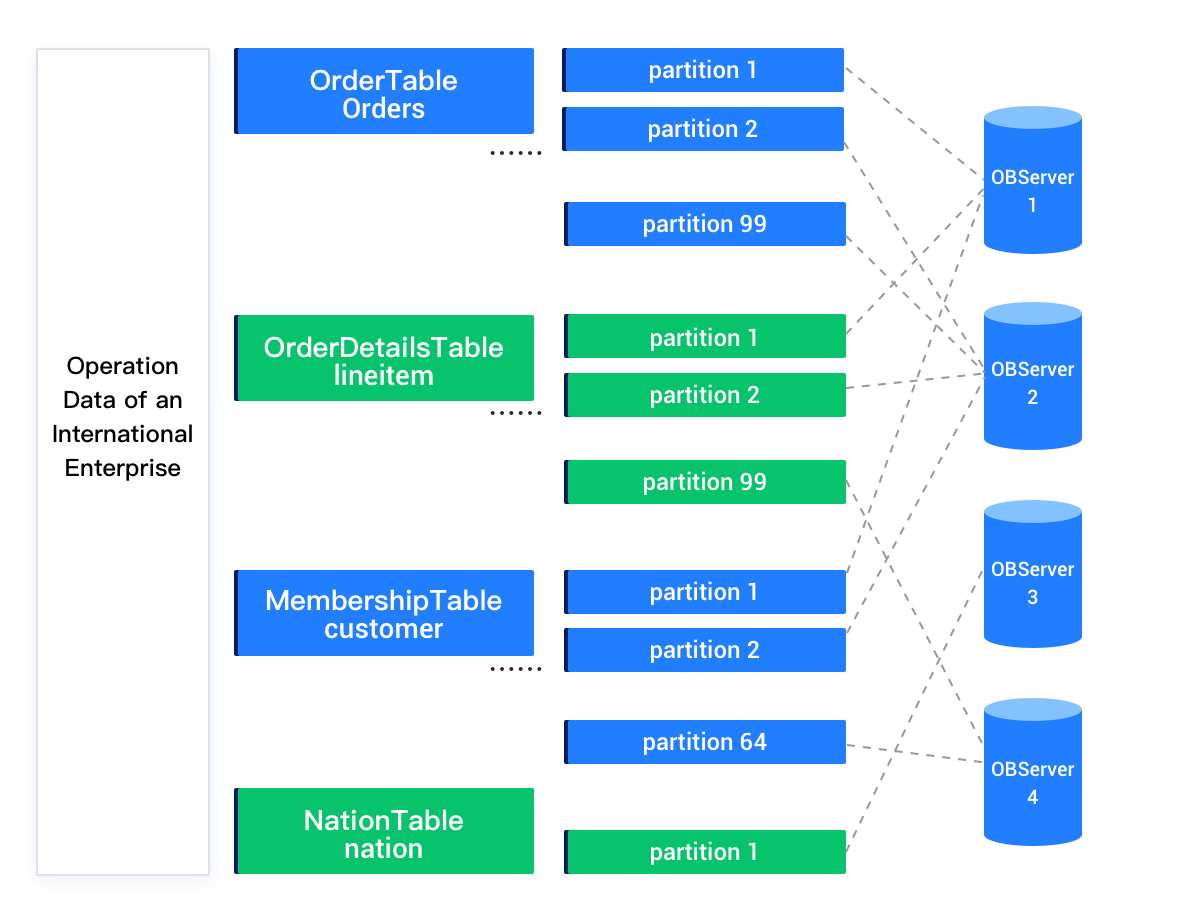
リレーショナルデータテーブルのデータはパーティション単位でシステム内の各ノードに格納されるため、パーティション間をまたぐデータクエリリクエストでは、実行計画が複数のノードのデータを操作できるようになっている必要があります。OceanBaseデータベースのオプティマイザーは、クエリとデータの物理的分布に基づいて自動的にディストリビューション実行計画を生成します。パーティションはディストリビューション実行計画においてクエリ性能を向上させることができます。データベースのリレーショナルテーブルが比較的小さい場合、パーティション化する必要はありません。一方、リレーショナルテーブルが大きい場合は、上位の業務要件に基づいて慎重にパーティションキーを選択し、ほとんどのクエリがパーティションキーを用いてパーティションカットを行えるようにすることで、データアクセス量を削減する必要があります。
また、関連性のあるテーブルについては、関連キーをパーティションキーとして使用し、同一のパーティショニング方式を採用することを推奨します。さらに、同じパーティションを同一のノード上に配置するために、テーブルグループを使用することで、ノード間のデータ交換を削減できます。
パラレルクエリの概要
パラレルクエリとは、クエリ計画をパラレル実行することで、各クエリ計画に対するCPUおよびI/O処理能力を向上させ、単一クエリの応答時間を短縮する技術です。パラレルクエリ技術は、分散実行計画にもローカルクエリ計画にも適用可能です。
単一クエリがアクセスするデータが同一ノード上にない場合、データ再配置を通じて関連データを同一ノードに分散して計算を行う必要があります。OceanBaseデータベースでは、各データ再配置ノードを上下の境界として、実行計画を垂直方向に複数のDFO(Data Flow Operator)に分割します。また、各DFOは指定された並列度のタスクに細分化され、並行実行によって実行効率が向上します。
一般的に、並列度が高くなるほどクエリの応答時間は短縮され、より多くのCPU、I/O、メモリリソースがクエリコマンドの実行に利用されます。特に、大量データを扱うDSS(意思決定支援システム)やデータウェアハウス型アプリケーションにおいて、クエリ時間の改善が顕著になります。
全体として、パラレルクエリの考え方は分散実行計画と類似しており、実行計画を分解した後、各部分を複数の実行スレッドが実行し、一定のスケジューリング手法によって、実行計画内のDFO間およびDFO内部での並行実行を実現します。
システムが以下の条件を満たす場合、パラレルクエリはシステムの処理性能を効果的に向上させることができます:
十分なI/O帯域幅
システムのCPU負荷が低い
十分なメモリリソース
システムが追加の並列処理に十分なリソースを持たない場合、パラレルクエリや並列度の向上は実行性能を向上させません。逆に、システムが過負荷状態の場合、オペレーティングシステムはより多くのスケジューリングを強いられ、例えば実行コンテキストの切り替えによって性能が低下する可能性があります。
通常、DSSシステムでは大量のデータへのアクセスが必要となるため、パラレル実行によって実行応答時間を向上させることができます。一方、単純なDML操作やデータ量が比較的小さいクエリにおいては、パラレルクエリを使用してもクエリ応答時間を明確に短縮することはできません。
パラレルクエリと分散クエリの原理
OceanBaseデータベースでは、データはシャード形式で各ノードに格納され、ノード間はギガビットまたはテラビットネットワークを介して通信します。通常、各ノードにはobserverと呼ばれるプロセスがデプロイされており、これがOceanBaseデータベースの外部サービスの主体となります。以下の図を参照してください。
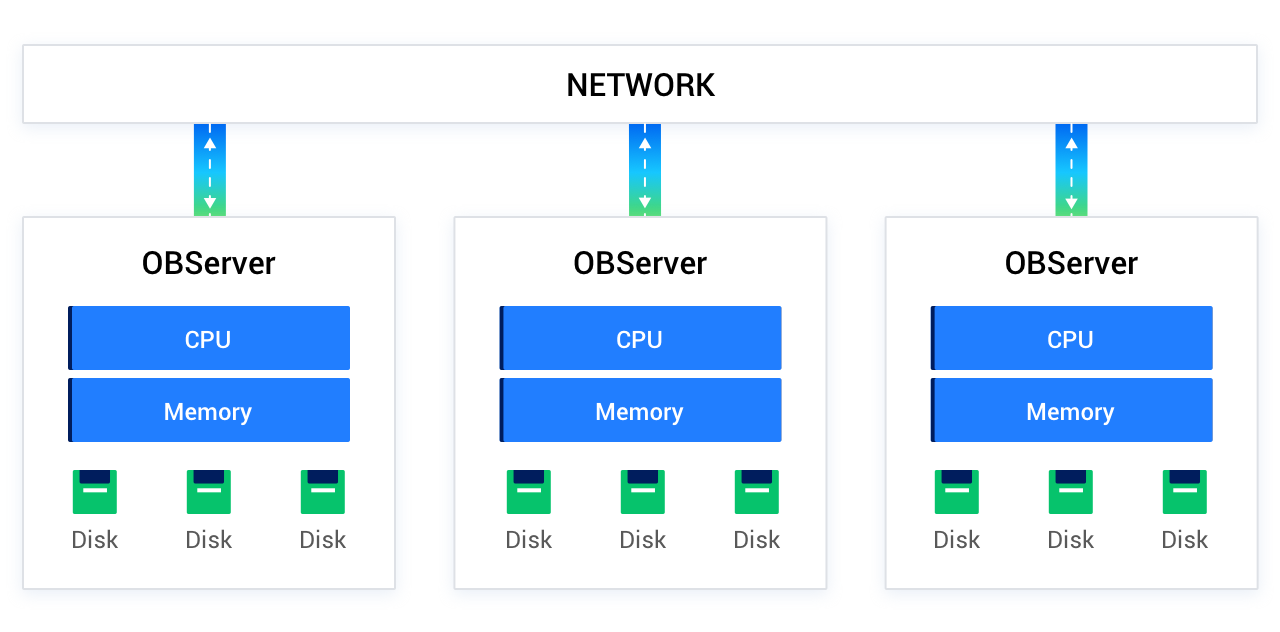
OceanBaseデータベースは一定のバランシングポリシーに基づいてデータシャードを複数のobserverプロセスに均等に分散するため、パラレルクエリでは一般的に複数のobserverプロセスへ同時にアクセスする必要があります。以下の図を参照してください。
SQLステートメントのパラレル実行プロセス
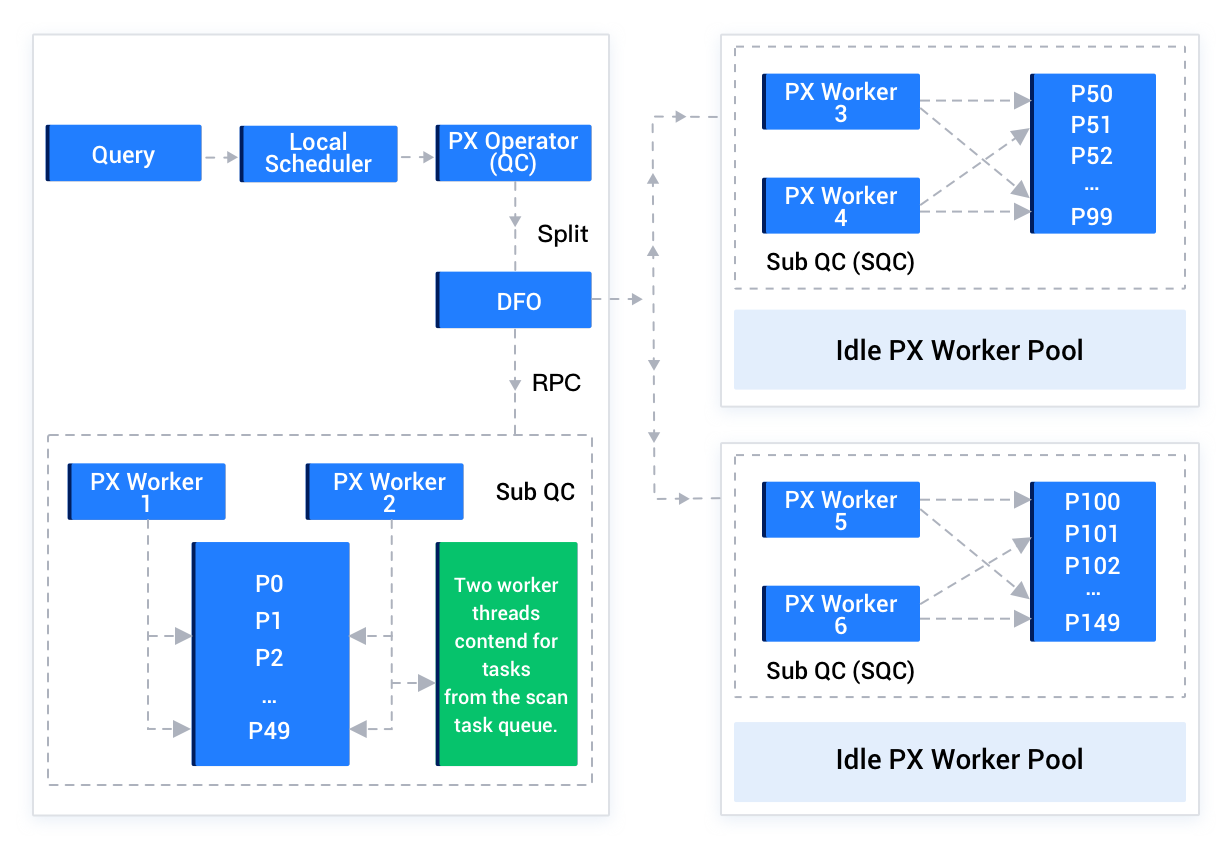
ユーザーが指定したSQLステートメントでアクセスする必要があるデータが2台以上のOBServerノードに存在する場合、パラレル実行が有効になります。ユーザーが接続しているこのOBServerノードは、クエリコーディネーターQC(Query Coordinator)の役割を担います。実行手順は以下のとおりです:
QCは十分なスレッドリソースを予約します。
QCは、並列化が必要な計画を複数のサブ計画、すなわちDFO(Data Flow Operator)に分割します。各DFOには、直列実行される演算子が複数含まれます。例えば、あるDFOにはパーティションのスキャン、集計、送信演算子のタスクが含まれ、別のDFOには収集、集計演算子などのタスクが含まれます。
QCは一定の論理的順序に従って、DFOを適切なOBServerノードにスケジュールして実行します。OBServerノードでは、一時的に補助コーディネーターSQC(Sub Query Coordinator)が起動されます。SQCは、所属するOBServerノード上で各DFOのために実行リソースの申請や実行コンテキスト環境の構築などを担当し、その後各DFOを起動して各OBServerノード上でパラレル実行を開始します。
各DFOの実行が完了すると、QCは残りの部分の計算を直列実行します。例えば、並列の
COUNTアルゴリズムでは最終的にQCが各マシン上の計算結果をSUM演算でまとめる必要があります。QCが実行しているスレッドは、結果をクライアントに返します。
オプティマイザーは、どのような並列計画を生成するかを決定し、QCはその計画を具体的に実行します。例えば、2つのパーティションテーブルのJOINでは、オプティマイザーはルールとコスト情報に基づいて、分散型PARTITION WISE JOIN計画またはHASH HASH分散型の分散JOIN計画を生成する可能性があります。計画が決定されると、QCは計画を複数のDFOに分割し、順序立ててスケジュールして実行します。QCの実行手順は以下の図に示されています。
パラレル度とタスク分割方法
パラレル度DOP(Degree Of Parallelism)は、1つのDFOを実行するために使用するスレッド(Worker)の数を指定できます。現在、OceanBaseデータベースではPARALLELHintを使用してパラレル度を指定します。パラレル度が決定されると、DOPはDFOを実行する必要がある複数のOBServerノードに分割されます。
スキャンを含むDFOの場合、DFOがアクセスする必要があるパーティションと、それらのパーティションがどのOBServerノードに配置されているかを計算し、その後DOPを対応するOBServerに比例して分割します。例えば、DOPが6で、DFOが120個のパーティションにアクセスする場合、server1には60個のパーティション、server2には40個のパーティション、server3には20個のパーティションがあるとします。その場合、server1には3つのスレッド、server2には2つのスレッド、server3には1つのスレッドを割り当て、平均して各スレッドが20個のパーティションを処理できるようにします。DOPとパーティション数が整数で割り切れない場合、OceanBaseデータベースは一定の調整を行い、ロングテールをできるだけ短くすることを目指します。
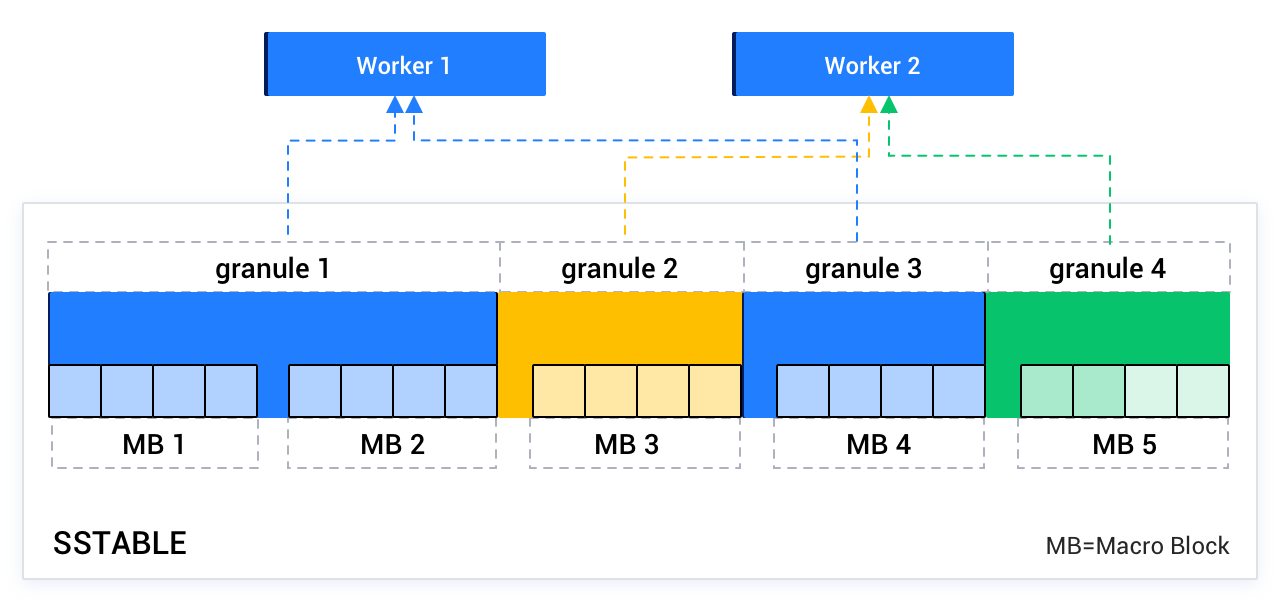
各マシンに割り当てられるWorker数がパーティション数を大幅に上回る場合、自動的にパーティション内の並列処理が行われます。各パーティションは、マクロブロックを境界として複数のスキャンタスクに分割され、複数のWorkerが実行を競合します。
このような分割機能を抽象化・カプセル化するために、Granuleという概念が導入されました。各スキャンタスクを1つのGranuleと呼び、このスキャンタスクは1つのパーティションをスキャンすることも、パーティション内のごく小さな範囲をスキャンすることもできます。以下の図を参照してください。
パラレルスケジューリング方式
オプティマイザがパラレル計画を生成した後、QCはそれを複数のDFOに分割します。以下の図に示すように、t1テーブルとt2テーブルのHASH JOINでは、3つのDFOに分割されます。DFO 1とDFO 2はデータのパラレルスキャンを担当し、データを対応するノードにHASH処理します。DFO 3はHASH JOINを実行し、最終的なHASH結果をQCに集約します。
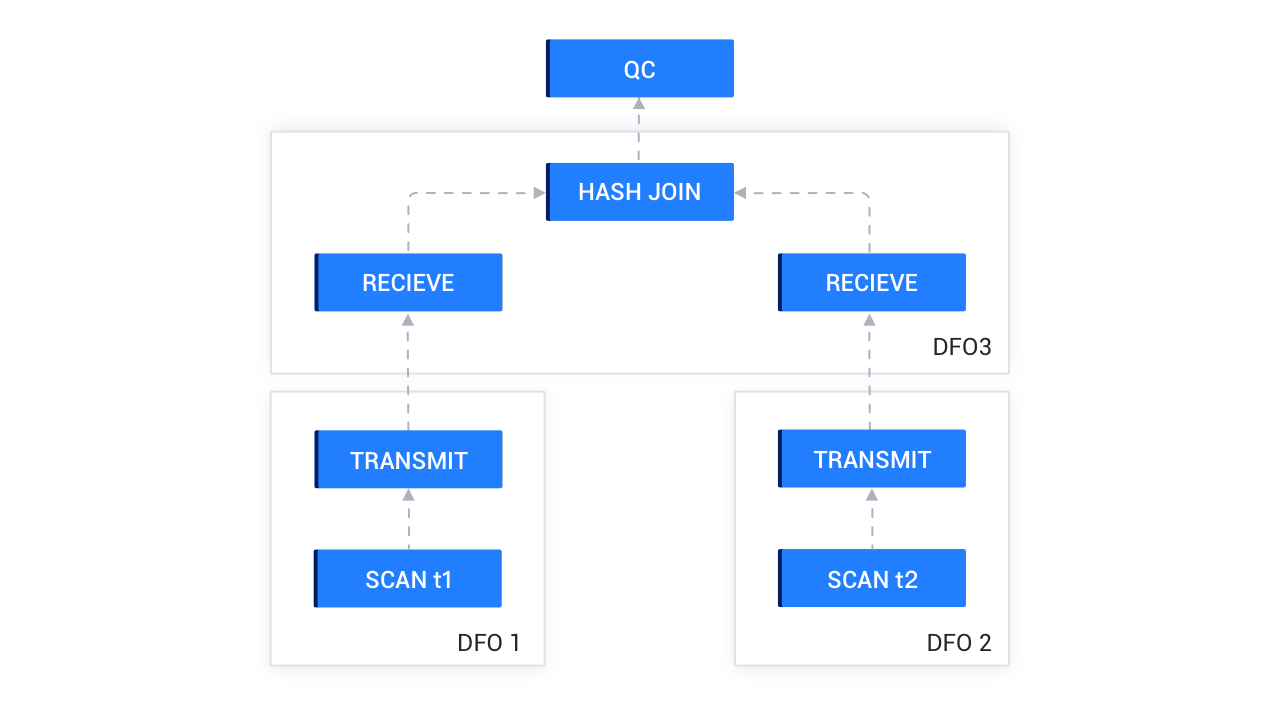
QCは可能な限り2組のスレッドを使用して計画のスケジューリングを完了します。上記の例のスケジューリングプロセスは以下のとおりです:
QCはまずDFO 1とDFO 3をスケジューリングします。DFO 1が実行を開始すると、データのスキャンを開始し、DFO 3に送信します。
DFO 3が実行を開始すると、最初にHASH JOINでHash Tableを作成するステップでブロックされます。つまり、DFO 1からデータを収集し、すべてのデータが収集されてHash Tableが作成されるまで待機します。その後、DFO 3は右側のDFO 2からデータを収集します。この時点でDFO 2はまだスケジューリングされていないため、DFO 3はデータ収集プロセスで待機します。DFO 1はデータをすべてDFO 3に送信した後、スレッドリソースを解放して終了できます。
スケジューラーがDFO 1のスレッドリソースを回収した後、直ちにDFO 2をスケジューリングします。
DFO 2が実行を開始すると、データをDFO 3に送信します。DFO 3はDFO 2から1行のデータを受信するたびにHash Tableで照合し、ヒットした場合は直ちにQCに出力します。QCは結果をクライアントに出力します。
ネットワーク通信方式
関連付けられたChild DFOとParent DFOのペアについて、Child DFOはプロデューサーとしてM個のWorkerスレッドを割り当てられ、Parent DFOはコンシューマーとしてN個のWorkerスレッドを割り当てられます。両者間のデータ転送には、M × N個のネットワークチャネルを使用する必要があります。以下の図に示すように。
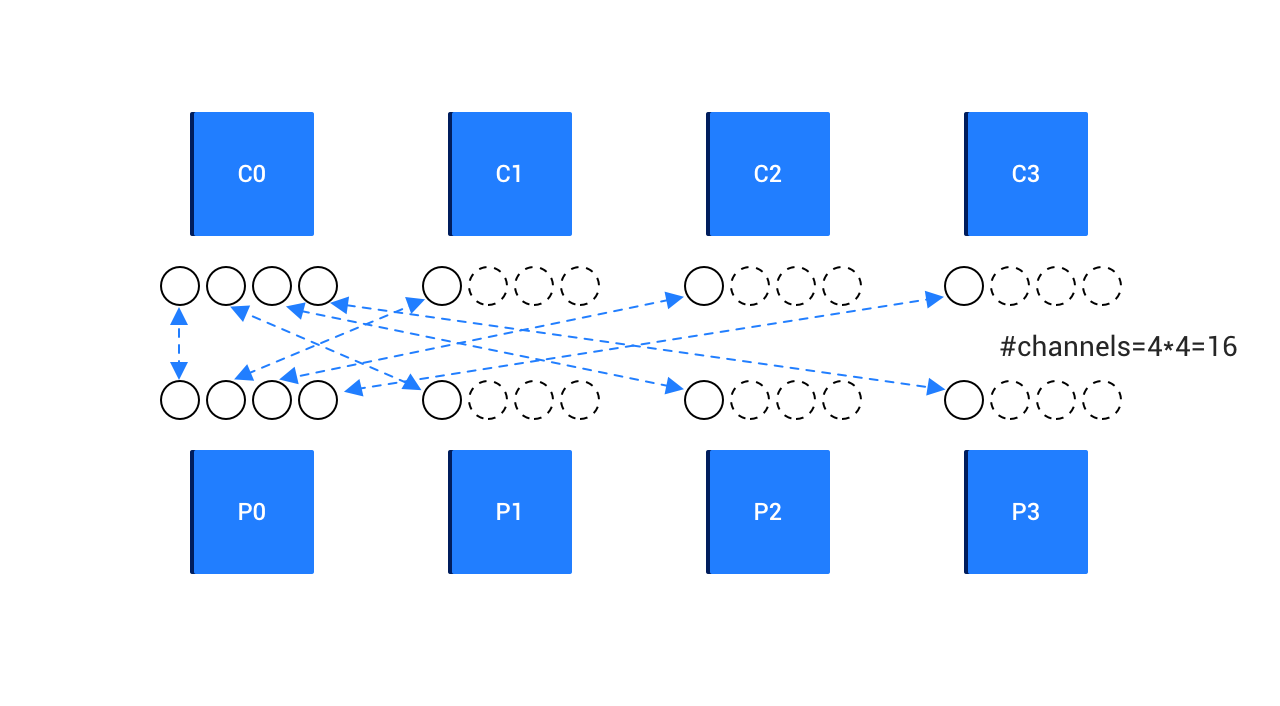
このネットワーク通信形式をよりよく理解するために、データ転送層DTL(Data Transfer Layer)という概念を導入します。これは、任意の2点間の通信接続をチャネル(Channel)という概念で記述するものです。
チャネルは送信側と受信側に分かれており、初期の実装では送信側が無制限に受信側にデータを送信できるようにしていましたが、受信側がこれらのデータを即座に消費できない場合、受信側のメモリが爆発的に増加する可能性があることが判明しました。そのため、ストリーム制御ロジックが追加されました。各チャネルの受信側には3つのスロットが予約されており、スロットがデータで上限になると送信側にデータ送信を一時停止するよう通知します。受信側のデータが消費されて空きスロットが出現すると、送信側に再送信を続けるよう通知します。