

システムの高可用性とは何ですか?
ITシステムの高可用性(High Availability)とは、システムが機能を中断することなく実行できる能力を指し、システムの可用性の程度を示します。高可用性は、システム設計、エンジニアリング実践、製品能力の各段階における総合的な取り組みによって、業務の継続性を保証します。システムの高可用性を確保するために最も重要なのは、単一障害点(Single Point of Failure)を可能な限り排除または冗長化し、単一障害やシステム障害発生後に迅速な復旧能力を提供することです。企業向けアプリケーションでは、業務の継続的な可用性を保証するため、システムの可用性に対して非常に高い要求があり、障害や災害発生時にシステムのRTOをできるだけ短く、RPOをできるだけゼロに近づける必要があります。
高可用性は分散システム設計において必ず考慮すべき要素であり、OceanBaseデータベースはネイティブな分散型データベースとして、一貫性があり高可用性のあるデータサービスを外部に提供できます。OceanBaseデータベースのトランザクションの一貫性とストレージの永続性により、OBServerノードが停止して再起動した場合でも、再起動前と同じデータと状態に復旧できることが保証されています。さらに、OceanBaseデータベースのバックアップ・リカバリやプライマリ/スタンバイ構成のソリューションも、さまざまなシナリオにおけるOceanBaseデータベースの高可用性を保証しています。
OceanBaseデータベースは、データサービスの高可用性を保証するためにどのような機能を備えていますか?
| プロダクト機能およびソリューション | 故障シナリオ | 動作原理 |
|---|---|---|
| OceanBase分散型選挙 | OceanBaseクラスタの少数派が様々な理由により利用不可能になった場合の復旧:
|
OceanBaseクラスタの選挙モジュールは、唯一のリーダーレプリカを選出し、外部にデータサービスを提供することを保証します。同時に、Paxosプロトコルを通じて多数派clogの強整合性同期永続化を実現しています。Paxosグループ内の任意の少数派レプリカに障害が発生した場合でも、残りのすべての多数派clogを統合することで、完全なClogが保証され、個別のハードウェア障害によるデータ損失を回避し、データの信頼性を確保します。 OceanBaseクラスタ全体の少数派に障害が発生した場合、非リーダーレプリカの少数派が利用不可能であっても、システムの可用性やデータベースのパフォーマンスに影響はありません。少数派の障害にリーダーレプリカが含まれている場合、OceanBaseクラスタは残りのレプリカから唯一の新しいプライマリを選出し、データサービスを提供することができます。これは主にOceanBaseクラスタの構築・デプロイモデルに基づいています。OBServerノードの複数のゾーンが異なるデータセンター、異なる都市に分散している場合、OceanBaseクラスタの分散型選挙とOceanBase Paxos clog同期を組み合わせることで、データセンター間または都市間の高可用性ソリューションを実現できます。 |
| OceanBase clogおよびストレージエンジン |
|
OceanBaseクラスタのストレージエンジンは、ベースラインデータをSSTableに、増分データをMemTableに保存します。OceanBase clogはデータのredo logです。データ変更が発生すると、リクエストはリーダーレプリカが存在するノードに到達し、データ変更リクエストをMemTableに更新し、トランザクションがコミットされ、リーダーはローカルclogを更新し、Paxosプロトコルを通じてログを他のフォロワーのレプリカノードに同期書き込みます。多数派ノードのログがディスクに正常に書き込まれた後、データ変更が成功し、クライアントに返されます。 フォロワーレプリカは、clogをローカルMemTableにリプレイして弱い整合性読み取りサービスを提供します。MemTableがしきい値に達すると、フリーズとダンプがトリガーされ、SSTable層に永続化されます。この時点でclogのリプレイポイントが進み、チェックポイントを行ったような状態になります。OBServerノードが再起動する際には、SSTableからソースデータを復元し、最新情報に更新することができます。その後、パーティションのメタ情報からclogのリプレイポイントを取得し、clogログのリプレイを開始してMemTableを生成します。これにより、OceanBaseクラスタはディスク上の永続化情報をダウンタイム前の状態に復旧し、データの整合性を保証します。 OceanBaseクラスタが障害(ソフトウェアの終了、異常な再起動、停電、機器障害など)により再起動するか、計画的な停止メンテナンスのために再起動する場合、OBServerノードは起動中に復旧し、OBServerノードのstoreディレクトリ下のログとデータをメモリに復元し、プロセスの状態をダウンタイム前の状態に復旧します。多数派レプリカに障害が発生し、再起動が必要な場合、データサービスは中断されますが、OceanBaseクラスタは多数派がダウンして再起動した後、データをダウンタイム前の状態に完全に復旧することを保証します。 OBServerノードは、多数派のダウン時の再起動についてもさらに最適化処理を行い、データレプリカのMemTableへの復旧ロード速度を高速化し、早期に外部にデータサービスを提供できるようにしています。クラスタ全体の再起動シナリオでは、ディスク上の最新clogを再度MemTableにリプレイした後、外部にデータサービスを提供し、OceanBaseクラスタがデータサービスを再開できるようになったら、データをクラスタ再起動前の状態に復旧します。 |
| OceanBaseバックアップ復旧 | OceanBaseクラスタでデータ損傷、ノードクラッシュ、またはクラスタ障害が発生した場合、OceanBaseクラスタはバックアップされたベースラインデータとclogバックアップから復旧できます。 | OceanBaseクラスタでデータ損傷、ノードクラッシュ、またはクラスタ障害が発生した場合、OceanBaseクラスタはバックアップされたベースラインデータとclogバックアップから復旧できます。 |
| OceanBaseプライマリ/スタンバイ構成ソリューション | ラックレベルの障害または都市レベルの災害復旧:
|
OceanBaseクラスタは従来のプライマリ/スタンバイ構成もサポートしています。OceanBaseクラスタのマルチレプリカメカニズムにより、マシンレベル、ラックレベル、都市レベルの障害に対して豊富なディザスタリカバリ機能を提供し、自動切り替えを実現するとともにデータ損失を防ぎ、RPO = 0を保証します。プライマリクラスタが計画的または計画外(多数派レプリカの障害)のアベイラビリティ障害を発生した場合、スタンバイクラスタがサービスを引き継ぎ、無損失切り替え(RPO = 0)および有損失切り替え(RPO > 0)という2種類のディザスタリカバリ機能を提供し、サービス停止時間を最大限に短縮します。 OceanBaseクラスタは、1つまたは複数のスタンバイクラスタの作成、保守、管理、監視をサポートしています。スタンバイクラスタは本番データのホットバックアップです。管理者は、システムのパフォーマンスとリソース利用率を向上させるために、集約型読み取り専用業務をスタンバイクラスタに割り当てることができます。 |
OceanBaseデータベースでは、少数派のダウンが発生した場合はどうなるのでしょうか?いつ復旧できるのでしょうか?
OceanBaseデータベースは、Paxos分散一貫性プロトコルに基づいており、いかなる時点でも過半数のレプリカが合意に達した場合にのみリーダーを選出し、リーダーレプリカの一意性を保証して外部にデータサービスを提供します。サービスを提供中のリーダーレプリカが障害によりサービスを継続できなくなった場合でも、残りのフォロワーレプリカが過半数を満たし合意に達していれば、新しいリーダーを選出してサービスを引き継ぐことができます。一方、サービスを提供中のリーダー自身が過半数の条件を満たせない場合は、自動的にリーダー資格を失います。リーダーレプリカに障害が発生した際、フォロワーがいつまでにリーダーの障害を検出し新しいリーダーを選出できるかという時間が、直接RTO(Return Time Objective)の大きさを決定します。
OceanBaseデータベースの選出モデルは、Paxosに基づいて再設計された選出方式であり、同一ログストリームの複数レプリカ間でコンセンサス協議を行い、各レプリカの優先順位を組み合わせて唯一のリーダーレプリカを選出します。選出が成功すると、各レプリカはリーダーを認定するリース(Lease)を締結します。リース期間が満了する前に、リーダーは継続的に再選を試み、通常の状況下では常に再選に成功します。もしリーダーが再選に失敗した場合、リース期間満了後に定期的に無主選出を開始し、レプリカの高可用性を保証します。3レプリカ(オールマスターレプリカ)のシナリオでは、あるレプリカに異常が発生した場合(例えば、そのノードのマシン障害やOBServerノードのオフラインなどの単一障害)、OceanBaseデータベースの選出モジュールは以下のように動作します:元のリーダーレプリカが再選に成功した場合、元のプライマリは引き続きリーダーレプリカサービスを提供できます。元のリーダーレプリカがオフラインとなり、リーダーの再選に失敗した場合、OceanBaseデータベースは無主選出を行い、新しいプライマリの就任は8秒以内に完了します。
同時に、OceanBaseデータベースはPaxosプロトコルを通じて、過半数のclog強い一貫性同期永続化を実現しています。Paxosグループ内の任意の少数派レプリカに障害が発生した場合でも、残りの過半数のレプリカは最新のClogを保持できるため、個々のハードウェア障害によるデータ損失を回避し、データの信頼性を保証します。
OceanBaseデータベースの選出は、どのようにしてブレインスプリット問題を回避するのでしょうか?
高可用性ソリューションにおいて、典型的なブレインスプリット(Split Brain)問題とは、2つのデータレプリカがネットワークの問題により互いの状態を知らず、それぞれが自分自身がリーダーレプリカとしてデータサービスを提供すべきだと考える場合に発生します。このとき、典型的なブレインスプリット現象が現れ、最終的にシステムの混乱やデータ損傷を引き起こします。OceanBaseデータベースは、Paxosプロトコルの過半数コンセンサスメカニズムを利用して、データの信頼性とリーダーレプリカの一意性を保証します:いかなる時点でも過半数のレプリカが合意に達した場合にのみ、リーダーを選出できます。サービスを提供中のリーダーレプリカが障害によりサービスを継続できなくなった場合でも、残りのフォロワーレプリカが過半数を満たし合意に達していれば、新しいリーダーを選出してサービスを引き継ぐことができます。一方、サービスを提供中のリーダー自身が過半数の条件を満たせない場合は、自動的にリーダー資格を失います。
したがって、OceanBaseデータベースの分散選出は高可用性において明らかな利点があります:理論的にはいかなる時点でも最大1人のリーダーしか存在しないため、ブレインスプリットの状況を根本的に排除します。ブレインスプリットを心配する必要がなくなったため、リーダーが障害によりサービスを提供できなくなった場合、フォロワーは自動的に選出をトリガーして新しいリーダーを生成し、サービスを引き継ぎます。このプロセスには人の介入は一切不要です。これにより、ブレインスプリットの問題を根本的に解決するだけでなく、自動再選出を利用してRTOを大幅に短縮することができます。もちろん、ここにはもう一つ重要な要素があります。それは、リーダーに障害が発生した場合、フォロワーがいつまでにリーダーの障害を検出し新しいリーダーを選出できるかという時間が、直接RTOの大きさを決定するということです。
OceanBaseクラスタでは、過半数が失敗した場合でもサービスを提供できるのでしょうか?
OceanBaseクラスタにおいて過半数が失敗した場合、対応するパーティションは外部にデータサービスを提供できません。データの高可用性を保証するために、システム全体のアーキテクチャ設計および運用保守時には、2つのレプリカに関連しない連続障害が発生する時間も考慮し、最適化する必要があります。最終的に、MTTF(平均故障時間)が障害の修復時間MTTR(平均修理時間)よりも十分に小さいことを保証し、データサービス全体の高可用性を確保する必要があります。OceanBaseクラスタの過半数が失敗した場合、問題分析に必要な情報とログを保持した上で、できるだけ早く緊急措置を講じてクラスタを可利用状態に復旧させるべきです。
OceanBaseクラスタのレプリカ自動補完機能はどのように動作するのか、またレプリカ自動補完はノードがダウンした場合でも対応するパーティションのレプリカが完全に保たれることを保証できるのか?
observerプロセスが異常終了した場合、終了時間がserver_permanent_offline_time未満であれば処理されません。この時点で一部のパーティションのレプリカ数は2つになります(3レプリカ構成の場合)。終了時間がserver_permanent_offline_timeを超えた場合、そのServerは永続的にオフライン状態となり、OceanBaseクラスタは同一ゾーン内の他のServer(リソースに余裕のあるServer)で領域を開設し、レプリカ数を維持します。十分なリソースが確保されれば、Unit移行が開始されます。
OceanBaseクラスタは複数のデータセンターおよび地域にまたがるデプロイメント方式をサポートしているのか。デプロイ時のインフラ要件は何か、どのように選定すべきか?
OceanBaseクラスタの構築では、複数のレプリカ(ノード)を複数のデータセンター、複数の都市に分散させ、データセンター間/都市間でPaxosグループを実現することが可能です。複数のデータセンター、複数の都市にまたがるクラスタアーキテクチャを選択する際、通常はデータセンターレベル、あるいは都市レベルの災害復旧能力を獲得することを目的としています。技術的には、OceanBaseクラスタの異なるレプリカノードを支えるインフラストラクチャが十分に良好であり、適切なレプリカ分布が保たれていれば、OceanBaseクラスタはデータを異なるノードに分散して外部にデータサービスを提供できます。一般的に、複数のデータセンター/複数の都市にまたがるデプロイメント方式では、ビジネスや各種アーキテクチャ要件を考慮することが最も重要です。なぜなら、複数のデータセンター/複数の都市にまたがるデプロイメント方式は、システム全体のコストを大幅に引き上げる可能性があるからです(例えば、都市間の専用回線デプロイメントなど)。したがって、異なるデプロイメント方式は、コスト、ニーズ、製品能力、プランの実現可能性など、複数の観点からのトレードオフによって決定されるものです。
技術的には、データセンターレベルまたは都市レベルの災害復旧を解決できるクラスタソリューションには以下のものがあります:
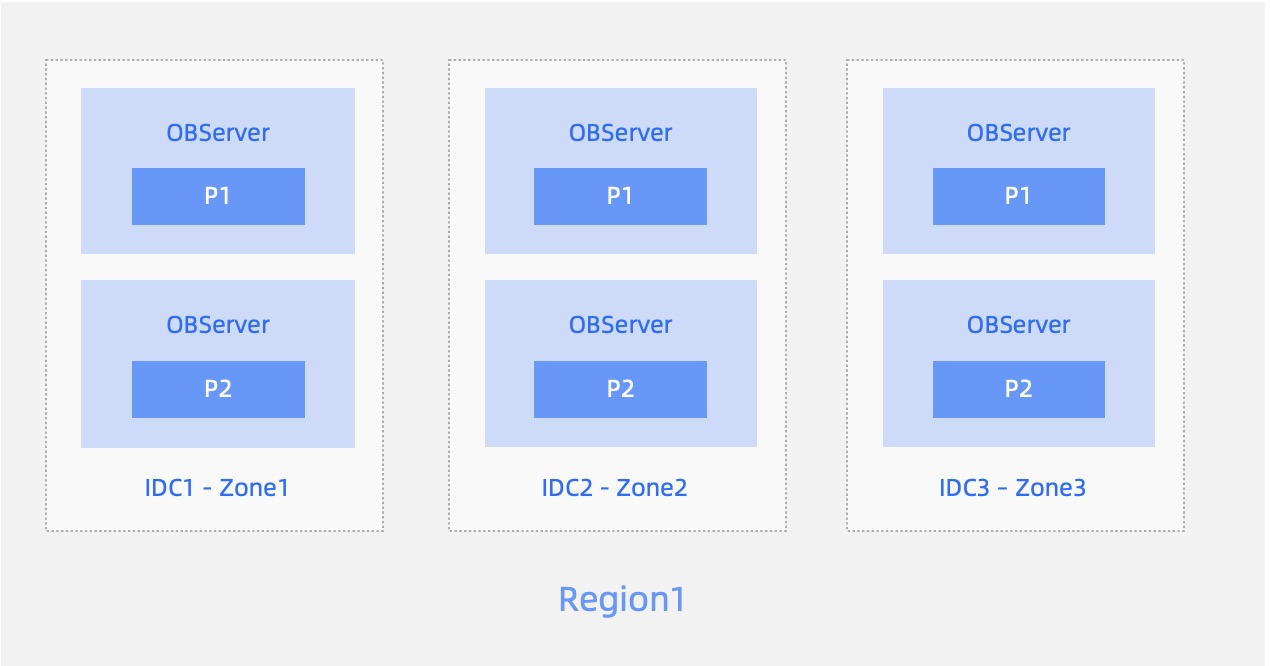
同一都市内の3データセンター・3レプリカ構成:
- 同一都市内の3つのデータセンターで1つのクラスタを構成します(各データセンターが1つのゾーン)。データセンター間のネットワーク遅延は通常0.5~2msの範囲です。
- データセンターレベルの災害発生時、残りの2つのレプリカが多数派となり、Redoログの同期を継続できるため、RPO=0を保証します。
- 都市レベルの災害には対応できません。
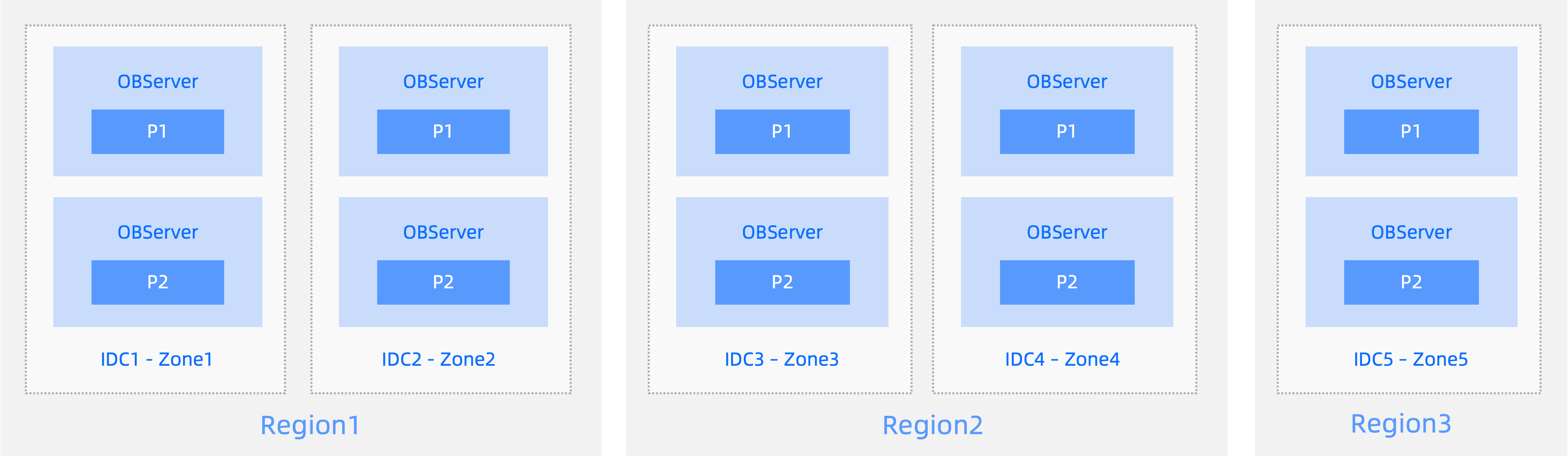
3リージョン・5データセンター・5レプリカ構成:
- 3つの都市で、5レプリカのクラスタを構成します。
- いずれかのIDCまたは都市の障害が発生しても、多数派が維持され、RPO=0を保証します。
- 多数派を形成するには3つ以上のレプリカが必要ですが、各都市には最大2つのレプリカしかないため、遅延を低減するために都市1と都市2は近接して配置する必要があります。これにより、Redoログの同期遅延を抑えることができます。
- コストを削減するため、都市3にはログ型レプリカ(ログのみ)をデプロイすることができます。
実際のデプロイメントプランでは、OceanBaseクラスタは顧客のニーズに基づいて同一都市内の2データセンター構成や2リージョン・3データセンター構成もカスタマイズされています。これら2つのデプロイメントプランはそれぞれ、特定のシナリオにおけるシステムの高可用性要件の一部を解決していますが、同時に一定の災害復旧能力の短所も存在します。一定期間、システムアーキテクチャの中間段階として顧客の初期デプロイメントの選択肢となる可能性があり、顧客はOceanBaseのプライマリ/スタンバイ構成を組み合わせて期待される災害復旧能力を達成することも可能です。具体的なプランの検討には、複数の要因と側面を考慮する必要があります。具体的なシナリオがある場合は、OceanBaseデータベースの技術アーキテクトに連絡し、プランの議論と調整を行ってください。