

OceanBaseデータベースがSysbenchテストで直面するパフォーマンス問題を深く分析し、ボトルネックの特定、構成の最適化、およびパフォーマンスチューニングを通じて解決策を提供します。これにより、高同時実行シナリオにおけるデータベースの安定性と効率性の向上を支援します。また、ユーザーが直面する可能性のあるパフォーマンス問題を解決するために、いくつかのパフォーマンス問題のケースを参考として提供します。
Sysbenchの問題の迅速な特定方法
SysbenchでTPSが予想より低く、変動が大きい、0に低下した、または異常終了した場合は、まず迅速に問題を特定し、調査する方法を採用すべきです。
問題現象1:SysbenchのTPSが予想を下回る
問題の調査手順は以下のとおりです:
Sysbenchパラメータを分析します。
Sysbench実行コマンド内のパラメータを優先的に分析します。
--rand-type=specialを設定している場合、または--rand-typeパラメータを設定していない場合は、データ間のロック競合を減らすために--rand-type=uniformに設定できます。テーブル数やサイズが小さすぎる場合は、データセットを増やすことができます。例えば、
tables=100、table_size=1000000などです。read_writeまたはwrite_onlyのシナリオの場合、デッドロックがないか確認して検証することができます:SELECT * FROM oceanbase.cdb_ob_deadlock_event_history ORDER BY create_time DESC LIMIT 10;
接続方式を確認します。
- Primary Zoneが単一のZoneであり、OBServerノードに直接接続されている場合、接続先がLeaderであるか確認します。
- Primary ZoneがRandomの場合、テストを行うにはOBProxyに接続する必要があります。
テナント情報を照会します。
SELECT * FROM oceanbase.dba_ob_tenants;テナントのLeaderを照会します。
SELECT svr_ip, sql_port, count(1) FROM oceanbase.cdb_ob_ls_locations WHERE tenant_id=1 AND role='leader' GROUP BY svr_ip;
CPUオーバーヘッドを観察します。
Sysbenchパラメータとクライアント接続方式に問題がない場合、CPU使用率を確認してさらに調査を進めることができます。
スレッドのCPU占有率を確認します。
top -H -p pidof observer各業務スレッドが基本的に1コアをフルに使用している場合、次にスレッド数がマシンのコア数に近いかどうかを確認します。
- 業務スレッド(例えばT1002_L0_G2)の数がマシンのコア数よりもはるかに少なく、CPUの総オーバーヘッドもマシンの上限に達していない場合、おそらく
cpu_countの割り当てが少なすぎることが原因です。この場合、テナント作成コマンドを確認し、cpu_countが低すぎないかどうか設定しています。 - CPUの総オーバーヘッドがマシンの上限に近い場合、マシンの性能は限界に達しており、より高い性能を得るには、より高い構成のマシンを使用するしかありません。
- 業務スレッド(例えばT1002_L0_G2)の数がマシンのコア数よりもはるかに少なく、CPUの総オーバーヘッドもマシンの上限に達していない場合、おそらく
テナントの仕様を確認します。
show create tenant xxx; SELECT * FROM oceanbase.dba_ob_resource_pools; SELECT * FROM oceanbase.dba_ob_units;業務スレッドが1コアをフルに使用していない場合(例えばCPU占有率が20%~50%)、他の部分でボトルネックが発生しています。
- ネットワークスレッド(例えばRpcIO)が1コアをフルに使用している場合、ネットワークスレッドの数が少なすぎる可能性があり、ネットワーク通信がボトルネックとなっているため、スレッド数
net_thread_countを増やす必要があります。 - すべてのスレッドのCPU占有率がそれほど高くない場合、ハードウェア側でボトルネックが発生している可能性があり、さらに分析する必要があります。
- ネットワークスレッド(例えばRpcIO)が1コアをフルに使用している場合、ネットワークスレッドの数が少なすぎる可能性があり、ネットワーク通信がボトルネックとなっているため、スレッド数
ハードウェア要因を分析します。
CPU要因を除外した後、残りのハードウェア要因は主にディスクとネットワークです。ディスクとネットワークの問題の調査手法は以下のとおりです。
- NIC帯域幅の上限を確認し、テスト時にネットワーク帯域幅がボトルネックになっていないか観察します(SysbenchをOBServerマシン上でテストすることができます)。
- ネットワーク遅延(ping)を確認します。遅延が高すぎると、SQL実行が遅くなる可能性があります。
- ログディスクへの16K書き込みの帯域幅上限(FIOテストによる)を確認し、テスト時にディスクI/Oがボトルネックになっていないか観察します(SSDまたはNVMに交換してテストすることができます)。
ネットワークI/Oを確認するコマンド:
sar -n DEV 1NIC帯域幅の上限を確認するコマンド:
##(eth0はNIC名) ethtool eth0その他。
上記の要因を除外した後、テスト時間帯とobserverバックグラウンドタスクの競合など、特別な状況が存在する可能性があります。
以前、ユーザーからの報告によると、業務テストを行っている際に、2つのデータセットが明らかに予想を下回っていることがわかりました。各種設定をチェックしたところ、明らかな問題は見つかりませんでした。最終的に、そのユーザーが業務テストを行ったのは午前2時であり、その時間帯はちょうどOceanBaseデータベースが毎日のダンプコンパクションを行うデフォルトの時間であることが判明しました。そのため、データベースのパフォーマンスに大きな影響が出ました。
問題現象2:SysbenchのTPSが変動または0に低下する
SysbenchのTPSが変動したり、0に低下したりする場合、以下のような状況が考えられます。
TPSが時折わずかに変動する
考えられる原因:OceanBaseデータベースは定期的にダンプコンパクションを実行し、CPUリソースを占有するため、業務スレッドに影響を与えます。
cpu_countが多いほど影響は小さくなります。例えば、4c8gのテナントでは、ダンプ時にTPSが80%低下する可能性があります。32c64gのテナントでは、ダンプ時にTPSが10%低下する可能性があります。対処方法:
テナントリソースユニットの
max_cpuを増やします。テナントCPUの並列度を増やします。
alter system set cpu_quota_concurrency=4 tenant = xxx;ダンプスレッド数(
merge_thread_count)を減らすか、スレッドの優先順位(compaction_high_thread_score、compaction_mid_thread_score、compaction_low_thread_score)を下げると、単位時間あたりのダンプコストは低減されますが、時間的な代償が伴い、ダンプ全体のコストは変わりません。
TPSが一時的に0に低下した後、間隔を置いて回復する
- 考えられる原因:デッドロックが発生し、Sysbenchで
--mysql-ignore-errors=1062,1213,6002;が設定されている場合があります。 - 対処方法:
まずデッドロックが発生していないか確認します。
SELECT * FROM oceanbase.cdb_ob_deadlock_event_history ORDER BY create_time DESC LIMIT 10;確認後、次の操作を実行します。
- Sysbenchに
--rand-type=uniformパラメータを追加します。 - データセットを増やします。例えば、
tables=100、table_size=1000000;(table_sizeのデフォルト値は10000です)。
- Sysbenchに
TPSが0に低下した後、回復しない
- 考えられる原因:デッドロックが発生し、それが検出されなかった上に、タイムアウト時間が長く設定されているため、TPSが0に低下してもエラーが報告されず、終了も回復もされません。
- 対処方法:
まずデッドロックが発生していないか確認します。
SELECT * FROM oceanbase.cdb_ob_deadlock_event_history ORDER BY create_time DESC LIMIT 10;確認後、次の操作を実行します。
- Sysbenchに
--rand-type=uniformパラメータを追加します。 - データセットを増やします。例えば、
tables=100、table_size=1000000;(table_sizeのデフォルト値は10000です)。
- Sysbenchに
TPSが0に低下した後、迅速に回復する
考えられる原因:Clogディスクが上限になって書き込みができなくなり、TPSが0に低下します。その後、Clogの領域が回収されると、TPSが回復します。
対処方法:テナントのディスク容量使用量を確認します:
SELECT tenant_id, svr_ip, svr_port, log_disk_in_use, log_disk_size FROM oceanbase.gv$ob_units;より大きなディスク容量の割り当てを検討します。
上記の原因を除外しても問題が解決しない場合は、技術サポートスタッフに連絡し、調査を依頼してください。
問題現象3:Sysbenchが異常終了またはエラーを報告する
TPSが一時的に0に低下した後、断続的に回復し、時折エラー6002または1213が報告される
- 考えられる原因:デッドロックが発生したり、データセットが小さすぎたり、
rand-typeが設定されていない場合、デフォルトのSpecial型によりKeyの比較が集中することがあります。長時間終了しないのは、ほとんどのSQLがまだデッドロック状態であり、スレッドがSQLの実行終了を待機しているためです。 - 対処方法:
まずデッドロックが発生していないか確認します。
SELECT * FROM oceanbase.cdb_ob_deadlock_event_history ORDER BY create_time DESC LIMIT 10;確認後、以下の操作を実行します。
- Sysbenchに
--rand-type=uniformパラメータを追加します。 - データセットを増やします。例えば、
tables=100、table_size=1000000;(table_sizeのデフォルト値は10000です)。
- Sysbenchに
Sysbenchが異常終了し、エラー1062を報告する
- 考えられる原因:1062は主キーまたは一意インデックスの競合を示します。Sysbenchはランダムにデータを生成するため、主キーの競合が発生する可能性があります。
- 対処方法:Sysbenchにパラメータを追加します:
--mysql-ignore-errors=1062
Sysbenchが異常終了し、エラー1213を報告する
- 考えられる原因:デッドロックが発生し、デッドロックしている一部のトランザクションが強制終了されました。
- 対処方法:データセットが非常に大きく、
--rand-type=uniformパラメータを使用していても、デッドロックが発生する可能性があります。そのため、--mysql-ignore-errors=1062,1213パラメータを使用して、デッドロックエラーを無視できます。
Sysbenchが異常終了し、エラー6002を報告する
- 考えられる原因:6002はデッドロックによって引き起こされる可能性がありますが、最終的に1213ではなく6002が報告されました。
- 対処方法:データセットを増やし、
--rand-type=uniformパラメータを追加して、ロック競合を減らします。Sysbenchパラメータを追加します:--mysql-ignore-errors=1062,1213,6002。
Sysbenchが異常終了し、エラー4012を報告する
考えられる原因:ロック競合が激しい、またはデッドロックが発生している可能性があります。または、単にOBServerノードのパフォーマンスが低く、クライアント側の負荷が高すぎてタイムアウトした可能性もあります。
対処方法:タイムアウト時間(単位:us)を延長します:
set global ob_query_timeout = 50000000000;
Sysbenchが異常終了し、エラー5930を報告する
考えられる原因:SQLプリコンパイル機能、つまり
--db-ps-mode=autoが有効になっていますが、OceanBaseデータベースはプリコンパイルを十分にサポートしていません。対処方法:
- テナントパラメータを増やします:
alter system set open_cursors=65535;。 - SQLプリコンパイル機能を無効にしてテストすることもできます:
--db-ps-mode=disable;。
- テナントパラメータを増やします:
Sysbenchが異常終了し、他のエラーが報告される
- 考えられる原因:OceanBaseデータベースのBUGの可能性があります。
- 対処方法:エラーログを記録し、技術サポート担当者に連絡して調査を依頼してください。
Sysbenchの問題に対する通常のトラブルシューティングプロセス
問題を迅速に特定できない場合は、完全なチェックプロセスに従ってトラブルシューティングを行うことができます。このプロセスで理解できない点がある場合は、後続の該当する章またはリンク先のドキュメントを参照してください。それでも問題が解決しない場合は、テクニカルサポートに連絡し、協力してトラブルシューティングを行ってください。
通常の分析手順:
- ハードウェアリソースを確認します。CPU、メモリ、ディスクリソースが不足しているとパフォーマンスに直接影響し、TPSが0に低下する可能性があります。
- テナント設定を確認します。テナントに割り当てられたリソースが少なすぎると、ハードウェアが十分に活用されません。
- Sysbenchパラメータを確認します。スレッド数はTPSに直接影響します。データセットが小さすぎるか、データの分布が集中しすぎると、ロック競合やデッドロックが発生する可能性があります。
- 最後に、OBServerにBUGがないかどうかを検討します。
説明
以下の内容で提供されるコマンドは必要に応じて使用してください。すべて一度に実行する必要はありません。
ハードウェアチェック
CPUやメモリなどのハードウェアリソースが不足している場合、例えばCPUコア数が4未満、メモリ容量が8GB未満であると、パフォーマンスは自然と低下します。また、ディスクがほぼいっぱいになっていると書き込み速度にも影響が出ます。さらに、ネットワーク遅延が高すぎる場合も同様にパフォーマンスに影響を与えます。
- CPU:
lscpu - メモリ:
top、cat /proc/meminfo - ディスク:
df -h - ネットワーク遅延:
ping ip
OceanBaseデータベースのデプロイ設定チェック
マシンのハードウェアリソースに余裕がある場合でも、OceanBaseデータベースのデプロイ時に設定したパラメータが小さすぎてリソースを十分に活用できないと、パフォーマンスが低下することがあります。ほとんどの設定は動的に調整可能ですが、ごく一部はデプロイ時にのみ設定できます。
SYSテナントに接続し、グローバルビューを確認します。
SELECT * FROM GV$OB_SERVERS;ネットワークスレッド数を確認します(この構成パラメータは動的に変更できません)。
show parameters where name = 'net_thread_count';デプロイ済みのクラスタを確認します。
obd cluster listデプロイ済みのクラスタの設定を確認します。
obd cluster edit-config [cluster name]
OBServerが存在するマシン上で、OBServerの起動パラメータを確認します。
ps -ef | grep observer
テナント設定チェック
OBServerノードのリソースに余裕がある場合、テナントのリソースがボトルネックになっていないか、以下のコマンドで確認できます。
テナントの基本情報を確認します。
SELECT * FROM oceanbase.dba_ob_tenants;テナント作成コマンドを確認します。
show create tenant [tenant name];テナントに対応するリソースプールを確認します(
tenant_idを追加してフィルタリング可能)。SELECT * FROM oceanbase.dba_ob_resource_pools;対応するユニットの設定を確認します。
SELECT * FROM oceanbase.dba_ob_units;
Sysbenchパラメータチェック
SysbenchパラメータはSysbench実行コマンド内に記載されており、パラメータの説明と照らし合わせて一つずつ確認できます。
デッドロック問題の特定
デッドロックレコードを確認します。
SELECT * FROM oceanbase.cdb_ob_deadlock_event_history ORDER BY create_time DESC LIMIT 10;ここで、
role=victimは殺されたトランザクションを表します。トランザクション関連のSQLを確認します。
SELECT usec_to_time(REQUEST_TIME), TRACE_ID, TX_ID, QUERY_SQL FROM gv$ob_sql_audit WHERE TX_ID=52635 ORDER BY REQUEST_TIME;関連するトランザクションが見つからない場合は、SQL Audit機能が有効になっていないことを意味します。
enable_sql_audit構成パラメータがTrueに設定されているかどうか確認してください。show parameters where name = 'enable_sql_audit';クエリ結果がFalseの場合、トランザクションに対応するSQLコマンドは表示されません。ログをフィルタリングしてトランザクションIDを特定することで、いくつかの情報を見つけることができる可能性があります。
SQLに対応するログを照会します。
トランザクション関連のSQLを見つけた後、競合したSQLのTrace IDを使用して、ログ内で検索します。
grep '[trace id]' observer.log*このSQLのすべてのログが表示されます。通常、最後のログにはクライアントに返されるエラーコードが含まれています。
sending error packet(err=-4101最後の
commitまたはbeginコマンドのTrace IDを使用しても、関連ログを検索できます。sending error packet(err=-6002ログがない場合は、ログレベルが間違っているか、ログの制限がかかっている可能性があります。ログレベルを
WDIAGに設定し、ログ帯域幅の制限を引き上げる必要があります。alter system set syslog_level='WDIAG'; alter system set syslog_io_bandwidth_limit='2G';注意
構成パラメータを変更する前に発生したデッドロック情報は検索できません。
ダンプ・コンパクションの分析
実行時間が5秒を超えるダンプ・コンパクションタスクを確認します。
SELECT * FROM GV$OB_MERGE_INFO WHERE tenant_id=1002 AND (END_TIME-START_TIME)>5 LIMIT 10;特定のテーブルのコンパクションレコードを確認します。
SELECT * FROM GV$OB_TABLET_COMPACTION_HISTORY WHERE TABLET_ID IN (SELECT TABLET_ID FROM oceanbase.CDB_OB_TABLE_LOCATIONS WHERE TABLE_NAME = 'sbtest1') ORDER BY START_TIME DESC;ダンプを強制的にトリガーします。
alter system minor freeze tenant=xxx;
OBServerノードでtop -Hを実行して、MINI_MERGEおよびMINOR_EXEスレッドのオーバーヘッドを観察することもできますが、持続時間は比較的短いです。
スローSQLクエリ
5秒を超えるスローSQLクエリを照会し、すべての情報を出力します。
SELECT * FROM gv$ob_sql_audit WHERE elapsed_time > 5000000 LIMIT 10;キー情報をカスタマイズして出力します。
SELECT SVR_IP, SVR_PORT, SQL_EXEC_ID, TRACE_ID, TENANT_ID, SQL_ID, QUERY_SQL, PLAN_ID, PARTITION_CNT, IS_INNER_SQL, ELAPSED_TIME, EXECUTE_TIME, APPLICATION_WAIT_TIME FROM gv$ob_sql_audit WHERE elapsed_time > 5000000 ORDER BY elapsed_time DESC LIMIT 10;データが見つからない場合は、SQL監査機能が有効になっていない可能性があります:
show parameters where name = 'enable_sql_audit'; alter system set enable_sql_audit = true;
ログ問題のトラブルシューティング
ディスク容量使用状況を確認します。
SELECT tenant_id, svr_ip, svr_port, LOG_DISK_IN_USE, LOG_DISK_SIZE FROM gv$ob_units;
問題再現プロセス
最初に、以前の
sql_auditレコードをクリアできます。alter system set enable_sql_audit = false; alter system flush sql audit global;sql_auditレコードを有効にします。alter system set enable_sql_audit = true;ログレベルを変更します。
alter system set syslog_level='WDIAG';SQLレコードのしきい値を小さくし、より多くのSQLを記録できるようにします。
alter system set trace_log_slow_query_watermark = '10ms';システムログ帯域幅制限を引き上げ、制限による重要なログの損失を防ぎます。
alter system set syslog_io_bandwidth_limit='2G';トランザクションのタイムアウトを望まない場合は、タイムアウト時間を引き上げることもできます。
set global ob_query_timeout = 50000000000;
その後、問題シナリオと同じパラメータを設定して、Sysbenchの実行を開始します。
Sysbenchのパフォーマンス問題のケース分析
SysbenchのTPSが0に低下し、時折エラーが報告されるという問題を例に分析および対処方法を説明します。
現象
OceanBaseデータベースCommunity Edition V4.1.0を使用し、以下のコマンドでSysbenchテストを実行すると、TPSが0に低下し、エラーが報告されます。
sysbench --db-driver=mysql --threads=500 --time=300000 --mysql-host=xxxxxxx --mysql-port=2883 --mysql-user='tpcc@t1' --mysql-password='******' --report-interval=2 --tables=100 /usr/share/sysbench/oltp_read_write.lua --db-ps-mode=disable run
マシン構成:
問題の原因と分析
初期の判断では、table_size が小さく、データの分布がデフォルトでspecialモードになっているため、データが集中し、主キーの競合が深刻化し、最終的にデッドロックが発生し、TPSが0に低下したと考えられます。
まず、テナントのタイムアウト時間を長く設定します。
set global ob_query_timeout = 50000000000; set global ob_trx_timeout = 50000000000;早期の再現を図るため、
Tablesを1に設定し、他のパラメータは変更しません。sysbench oltp_read_write.lua --mysql-host=[ip] --mysql-port=2881 --mysql-user=root@user --mysql-db=test --table_size=10000 --tables=1 --threads=500 --time=3600 --report-interval=1 --db-ps-mode=disable run現象の生成:TPSは0に急落しますが、時折TPSとQPSが0より大きくなることがあります。
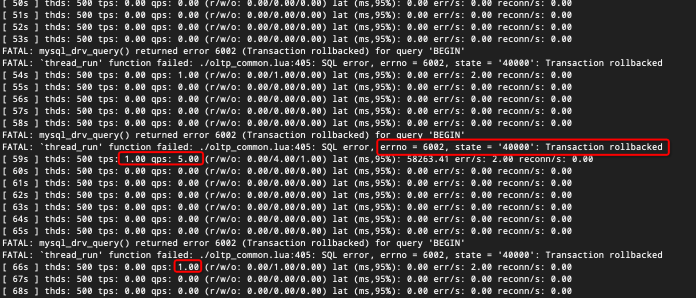
デッドロックビューを確認します。
SELECT * FROM oceanbase.CDB_OB_DEADLOCK_EVENT_HISTORY ORDER BY create_time DESC LIMIT 10;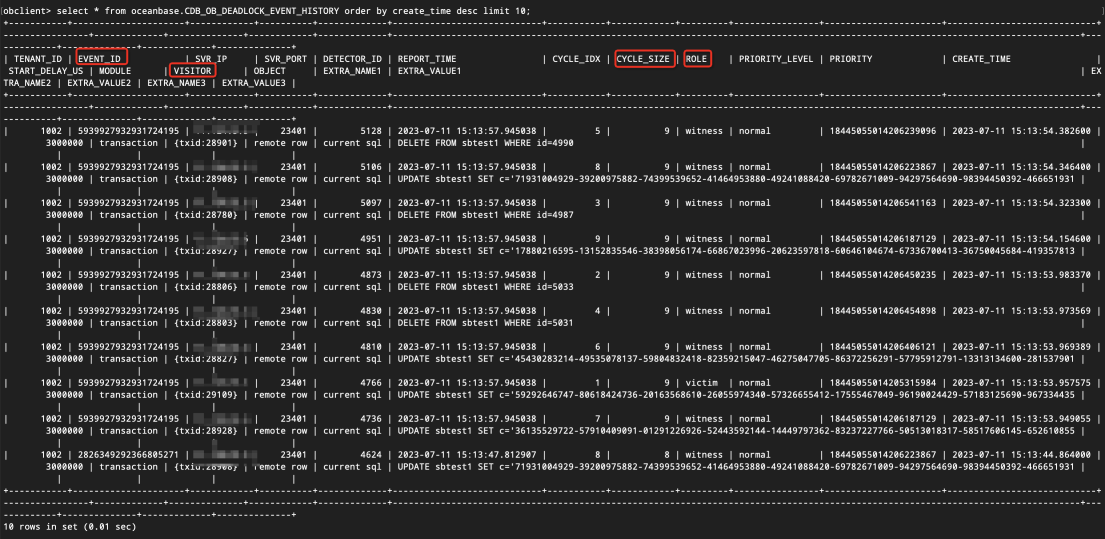
最近のデッドロックレコードが表示されます。
role=victimは殺されたトランザクションを表し、role=witnessは証人競合のトランザクションを表します。cycle_size=2は2つのトランザクションのみが互いに競合していることを示し、cycle_size>2は複数のトランザクションが1つのトランザクションと競合していることを示します。ここでは観察を容易にするために、cycle_size=2のイベントを選択し、event_idで一連の競合するトランザクションをフィルタリングできます。SELECT * FROM oceanbase.CDB_OB_DEADLOCK_EVENT_HISTORY WHERE cycle_size=2 ORDER BY create_time DESC LIMIT 10;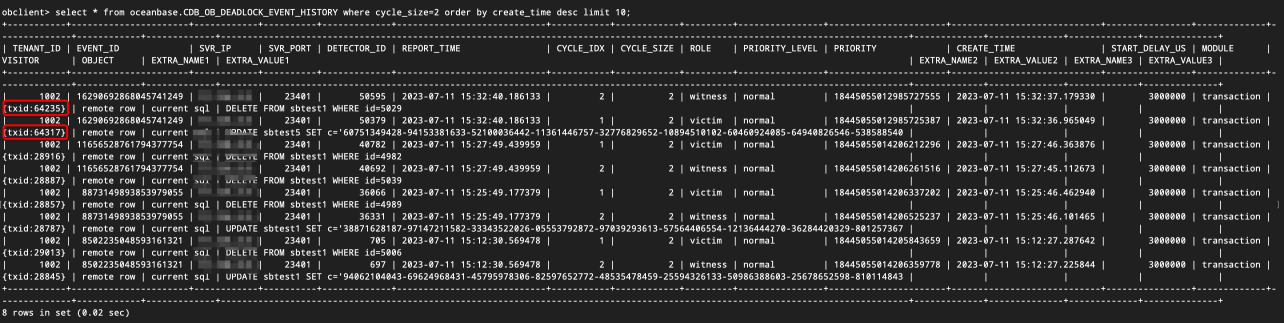
VisitorフィールドからトランザクションIDを確認でき、トランザクションIDからそのトランザクションに関連するすべてのSQLコマンドを見つけることができます:
SELECT TRACE_ID, TX_ID, QUERY_SQL FROM gv$ob_sql_audit WHERE TX_ID=5042912 ORDER BY REQUEST_TIME; SELECT TRACE_ID, TX_ID, QUERY_SQL FROM gv$ob_sql_audit WHERE TX_ID=5042591 ORDER BY REQUEST_TIME;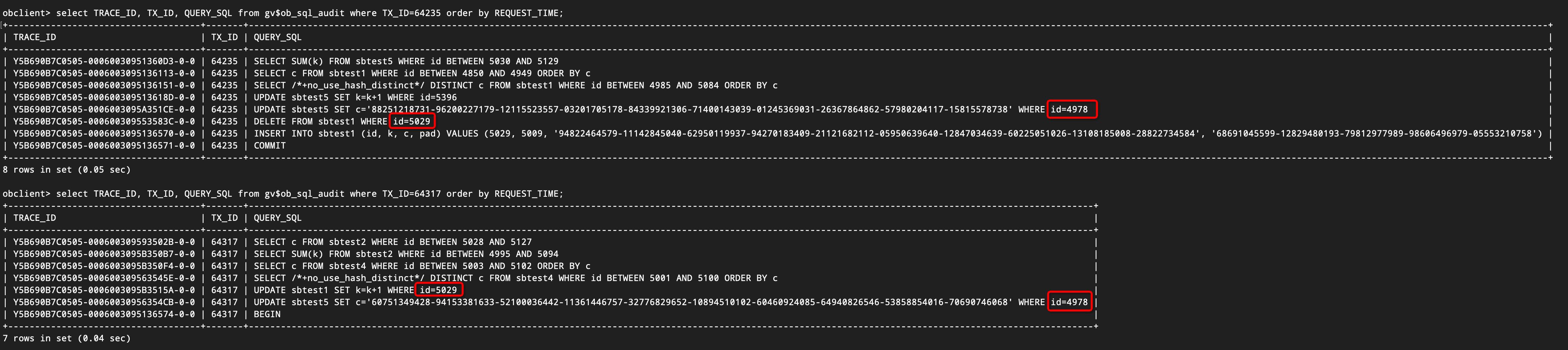
図から、2つのトランザクションが交差依存している状況がわかります。すなわち:
- トランザクション1はid=4978を更新します。
- トランザクション2はid=5049を更新します。
- トランザクション1はid=4978を更新します。
- トランザクション2はid=5049を削除します。
デッドロックが発生した後、トランザクション64317はロールバックされ、トランザクション64235は正常にコミットされました。トランザクション64317の作成時間が遅いため、sql_auditを確認してトランザクションの最初のSQLを見つけ、SQLの
request_timeで判断します。SELECT REQUEST_TIME, SVR_IP, SVR_PORT, SQL_EXEC_ID, TRACE_ID, TENANT_ID, TX_ID, SQL_ID, QUERY_SQL, PLAN_ID, PARTITION_CNT, IS_INNER_SQL, ELAPSED_TIME, EXECUTE_TIME, APPLICATION_WAIT_TIME FROM gv$ob_sql_audit WHERE TX_ID=64317 ORDER BY REQUEST_TIME;trace idに基づいてログを確認すると、ロールバックされたトランザクションが見えます。エラーコードは6002(ロールバック)、Abortの原因は4101(デッドロック)です。
殺されたトランザクションが競合したSQLログを検索すると、最後のログが4101エラーコードを送信していることがわかります。しかし、最後にSysbench側はデッドロックエラーを報告せず、6002のロールバックエラーを報告しました。
[2023-07-11 15:32:40.263794] INFO [SERVER] send_error_packet (obmp_packet_sender.cpp:317) [28473][T1002_L0_G0][T1002][Y5B690B7C0505-00060030956354CB-0-0] [lt=14] sending error packet(err=-4101, extra_err_info=NULL, lbt()="0x1029cb40 0x832fadc 0x82e32f7 0x5b65d4f 0x5960718 0x595c58f 0x595a25a 0x8075f6c 0x595964c 0x80754ea 0x595665a 0x8075b24 0x1061b777 0x10613e9f 0x7f0215489e25 0x7f0214f48f1d")トランザクションの最後の「BEGIN」コマンドに対応するログを検索します(トランザクションは明示的に
commitコマンドを実行していないため、次のトランザクションのbeginコマンドにより、現在のトランザクションが暗黙的にコミットされるため、beginは現在のトランザクションの最後のSQLです)。6002のロールバックエラーを返すログが見つかります。SysbenchはデッドロックSQLを処理せず、6002エラーを報告したことがわかります。[2023-07-11 15:32:40.305922] INFO [SERVER] send_error_packet (obmp_packet_sender.cpp:317) [28472][T1002_L0_G0][T1002][Y5B690B7C0505-0006003095136574-0-0] [lt=37] sending error packet(err=-6002, extra_err_info=NULL, lbt()="0x1029cb40 0x832fadc 0x82e32f7 0x5a55e57 0x5960c40 0x595c58f 0x595a25a 0x8075f6c 0x595964c 0x80754ea 0x595665a 0x8075b24 0x1061b777 0x10613e9f 0x7f0215489e25 0x7f0214f48f1d")ログが見つからない場合は、ログの制限による可能性があります。システムログ帯域幅の制限を引き上げることを推奨します:
alter system set syslog_io_bandwidth_limit='2G';
解決策
上記の問題原因の分析に基づき、以下の結論が得られます:
- デフォルトの
rand-type=specialのシナリオでは、キー競合が多すぎるためデッドロックが発生し、Sysbenchの負荷テストが終了する可能性があります。 - デフォルトの
rand-type=specialのシナリオで、tablesとtable_sizeも比較的小さい場合、デッドロックがより頻繁に発生し、多数のトランザクションがスタックされ、テストスレッドが適時に終了できないため、数分間TPSが0になることがあります。ただし、時折TPSが0を超えることもあります。 - デッドロックしたトランザクションはエラーを報告してロールバックされ、エラーコードは1213ではなく6002になる可能性があります。
ob_query_timeoutが長く設定されている場合、偶然にもデッドロック検出機能が有効になっておらず、トランザクションが強制終了できないため、SQLがブロックされ続けると、TPSは長期間0になり、エラーも報告されません。
これらの問題を解決するために、以下の方法を試すことができます:
- 最初に、データ分布タイプを調整し、
--rand-type=uniformを設定することを検討します。 - データ分布タイプの調整を考慮しない場合は、データセットを拡大することを推奨します。例えば、
tables=100、table_size=1000000などです。 - データのランダムタイプとデータセットの調整をどちらも考慮しない場合は、エラーコードを無視することを試すことができますが、これではデッドロックを回避することはできません。そのため、
--mysql-ignore-errors=1062,1213,6002を使用します。