

本記事では、OceanBaseデータベースのパス選択ルール体系について説明します。
現在、OceanBaseデータベースのパス選択ルール体系は、フロントエンドルール(フォワードルール)とSkyline剪定ルール(バックワードルール)に分かれています。フロントエンドルールは、クエリがどのインデックスを使用するかを直接決定し、強力なマッチングルール体系です。
Skyline剪定ルールは、2つのインデックスを比較し、ある定義された次元で一方のインデックスがもう一方のインデックスよりも優れている場合、劣るインデックスは削除されます。最終的に削除されなかったインデックスに対してコスト比較を行い、最適な計画を選択します。
現在、OceanBaseデータベースのオプティマイザーは、まずフロントエンドルールを優先してインデックスを選択します。一致するインデックスがない場合、Skyline剪定ルールが一部の劣るアクセスパスを削除し、最後にコストモデルが削除されなかったインデックスの中からコストが最も低いパスを選択します。
以下の例のように、OceanBaseデータベースの計画表示では、対応するパス選択ルール情報が出力されます。
obclient> CREATE TABLE t1(a INT PRIMARY KEY, b INT, c INT, d INT, e INT,
UNIQUE INDEX k1(b), INDEX k2(b,c), INDEX k3(c,d));
Query OK, 0 rows affected
obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE b = 1;
+-----------------------------------------------------------------+
| Query Plan |
+-----------------------------------------------------------------+
| =====================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
-------------------------------------
|0 |TABLE SCAN|t1(k1)|2 |94 |
=====================================
Outputs & filters:
-------------------------------------
0 - output([t1.a(0x7f3178058bf0)], [t1.b(0x7f3178058860)], [t1.c(0x7f3178058f80)], [t1.d(0x7f3178059310)], [t1.e(0x7f31780596a0)]), filter(nil),
access([t1.b(0x7f3178058860)], [t1.a(0x7f3178058bf0)], [t1.c(0x7f3178058f80)], [t1.d(0x7f3178059310)], [t1.e(0x7f31780596a0)]), partitions(p0),
is_index_back=true,
range_key([t1.b(0x7f3178058860)], [t1.shadow_pk_0(0x7f31780784b8)]), range(1,MIN ; 1,MAX),
range_cond([t1.b(0x7f3178058860) = 1(0x7f31780581d8)])
Optimization Info:
-------------------------------------
t1:optimization_method=rule_based, heuristic_rule=unique_index_with_indexback
obclient> EXPLAIN EXTENDED SELECT * FROM t1 WHERE c < 5 ORDER BY c;
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Query Plan |
+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
| ================================================== |
| |ID|OPERATOR |NAME |EST.ROWS|EST.TIME(us)| |
| -------------------------------------------------- |
| |0 |TABLE RANGE SCAN|t1(k3)|1 |7 | |
| ==================================================
Outputs & filters:
-------------------------------------
0 - output([t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.c(0x7f3178058e90)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), filter(nil), sort_keys([t1.c(0x7f3178058e90), ASC])
1 - output([t1.c(0x7f3178058e90)], [t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), filter([t1.c(0x7f3178058e90) < 5(0x7f3178058808)]),
access([t1.c(0x7f3178058e90)], [t1.a(0x7f3178059220)], [t1.b(0x7f31780595b0)], [t1.d(0x7f3178059940)], [t1.e(0x7f3178059cd0)]), partitions(p0),
is_index_back=false, filter_before_indexback[false],
range_key([t1.a(0x7f3178059220)]), range(MIN ; MAX)always true
t1:optimization_method=cost_based, avaiable_index_name[t1,k3], pruned_index_name[k1,k2]
ここで、optimization_method は具体的なルール情報を示しており、以下の2つの形式があります:
optimization_method=rule_basedと表示されている場合、フロントエンドルールにヒットしたことを意味し、同時に具体的なヒットしたルール名も表示されます。unique_index_with_indexbackは、フロントエンドルールの3番目のルール(一意性インデックスの完全一致 + テーブルへの再アクセス + テーブルへの再アクセス数が一定のしきい値未満)にヒットしたことを示します。optimization_method=cost_basedと表示されている場合、コストに基づいてルールが選択されたことを意味し、同時にSkyline剪定ルールによってどのアクセスパスが削除されたか(pruned_index_nameフィールド)およびどのアクセスパスが保持されたか(available_index_nameフィールド)も表示されます。
前置ルール
現在、OceanBaseデータベースの前置きルールは単純な単一テーブルスキャンにのみ使用されています。前置きルールは強力なマッチングルールであり、ヒットした場合はそのままヒットしたインデックスが選択されるため、誤った計画を選択することを避けるために、その使用シナリオを制限する必要があります。
現在、OceanBaseデータベースでは、「クエリ条件がすべてのインデックスキーをカバーできるかどうか」と「そのインデックスを使用する際にテーブルへのアクセスが必要かどうか」という2つの情報に基づいて、前置きルールを優先順位に応じて以下の3種類のマッチングタイプに分類しています:
「一意性インデックスの完全一致 + テーブルへのアクセス不要(主キーは一意性インデックスとして扱われる)」にマッチする場合、そのインデックスを選択します。複数のこのようなインデックスが存在する場合は、インデックス列数が最も少ないものを選択します。
「通常インデックスの完全一致 + テーブルへのアクセス不要」にマッチする場合、そのインデックスを選択します。複数のこのようなインデックスが存在する場合は、インデックス列数が最も少ないものを選択します。
「一意性インデックスの完全一致 + テーブルへのアクセス + テーブルへのアクセス回数が一定のしきい値未満」にマッチする場合、そのインデックスを選択します。複数のこのマッチングタイプのインデックスが存在する場合は、テーブルへのアクセス回数が最も少ないものを選択します。
ここで注意が必要なのは、インデックスの完全一致とは、インデックスキーすべてに等しい条件(getまたはmulti-getに対応)が存在することを指します。
以下の例では、クエリQ1はインデックスuk1(一意性インデックスの完全一致 + テーブルへのアクセス不要)にヒットし、クエリQ2はインデックスuk2(一意性インデックスの完全一致 + テーブルへのアクセス + テーブルへのアクセス行数が最大4行)にヒットします。
obclient> CREATE TABLE test(a INT PRIMARY KEY, b INT, c INT, d INT, e INT,
UNIQUE KEY UK1(b,c), UNIQUE KEY UK2(c,d) );
Query OK, 0 rows affected
Q1:
obclient> SELECT b,c FROM test WHERE (b = 1 OR b = 2) AND (c = 1 OR c =2);
Q2:
obclient> SELECT * FROM test WHERE (c = 1 OR c =2) AND (d = 1 OR d = 2);
Skyline剪枝ルール
Skyline演算子は、2001年に学術界で提案された新しいデータベース演算子です(標準的なSQL演算子ではありません)。それ以来、学術界ではSkyline演算子について多くの研究が行われています(構文、意味論、実行などを含みます)。
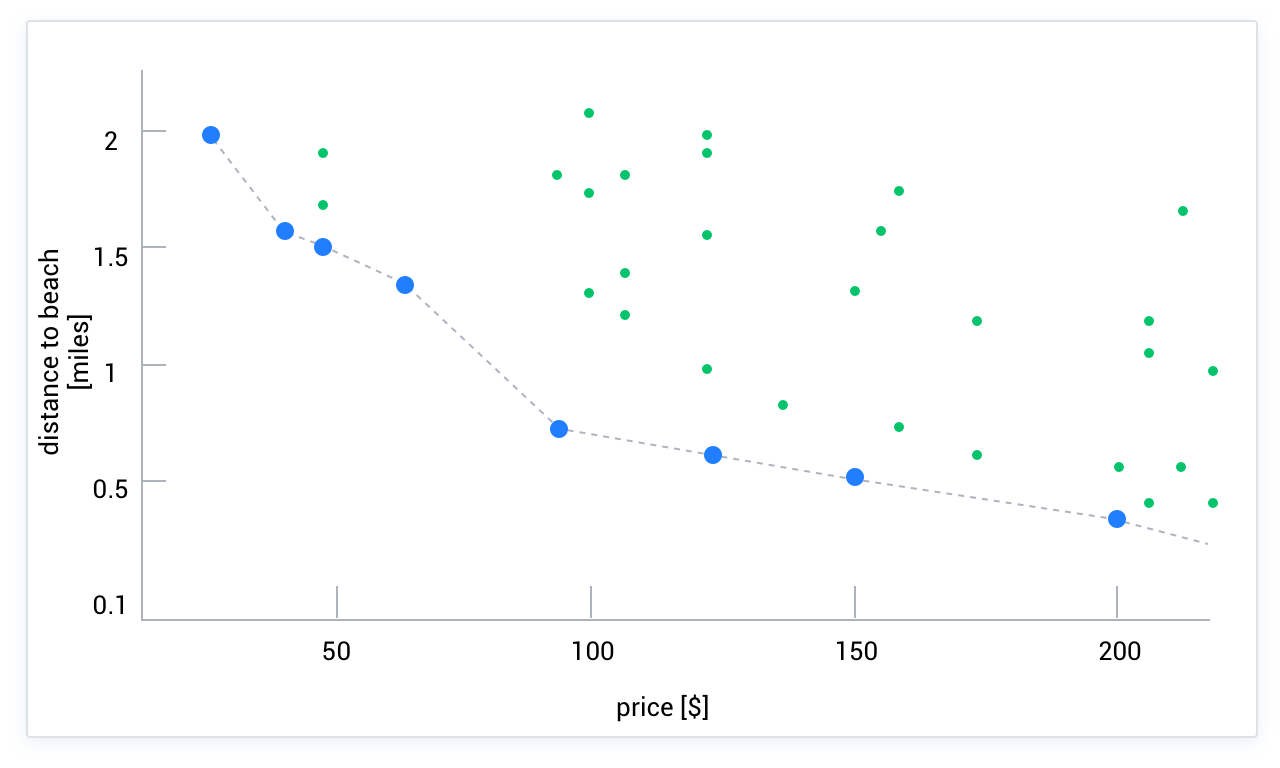
文字通りの意味でのSkylineとは、空の中のいくつかの境界点を指し、これらの点が探索空間内の最適解の集合を形成します。例えば、価格が最も低く、かつ距離が最も短いホテルを探す場合、2次元空間を想像することができます。横軸は価格を表し、縦軸は距離を表し、2次元空間上の各点は一つのホテルを表します。以下の図に示すように、最適解は必ずこの空の境界線上に存在します。点AがSkyline上にないと仮定すると、Skyline上にはAよりも2つの次元で優れた点Bが存在するはずです。このシナリオでは、それはより近く、より安いホテルであり、点BがAを支配すると呼ばれます。したがって、ユーザーが複数の次元の重要性を測定できない場合、または複数の次元を総合的に定量化できない場合(総合的に定量化できる場合は、「SQL関数+ ORDER BY」を使用して解決できます)、Skylineアルゴリズムを使用できます。
Skylineの原理は、与えられたオブジェクト集合Oから、他のオブジェクトに支配されないオブジェクトの集合を見つけ出すことです。あるオブジェクトAがすべての次元で別のオブジェクトBに支配されず、かつAが少なくとも一つの次元でBを支配する場合、AはBを支配すると言います。したがって、Skylineにおいて重要なのは次元の選択と、各次元における支配関係の定義です。N個のインデックスを持つパス<idx_1,idx_2,idx_3...idx_n>がオプティマイザーによって選択可能であり、クエリQに対してインデックスidx_xが定義された次元でインデックスidx_yを支配する場合、インデックスidx_yを事前に切り捨てて、最終的なコスト計算に参加させないようにすることができます。
次元の定義
Skylineチップインルールは、各インデックス(主キーもインデックスの一種です)に対して以下の3つの次元を定義します:
テーブルへのアクセスが必要かどうか
Interesting Orderが存在するかどうか
インデックスのプレフィックスからQuery Rangeを抽出できるかどうか
以下の例を通じて分析します:
obclient> CREATE TABLE skyline(
pk INT PRIMARY KEY, a INT, b INT, c INT,
KEY idx_a_b(a, b),
KEY idx_b_c(b, c),
KEY idx_c_a(c, a));
Query OK, 0 rows affected
テーブルへのアクセス:このクエリで主テーブルへのアクセスが必要かどうか。
/* インデックス idx_a_b を使用する場合、主テーブルへのアクセスが必要です。なぜなら、インデックス idx_a_b にはc列がないため*/ obclient>SELECT /*+INDEX(skyline idx_a_b)*/ * FROM skyline;Interesting Order:適切な順序を利用できるかどうかを検討します。
/* インデックス idx_b_c を使用すると、ORDER BY ステートメントを省略できます*/ obclient>SELECT pk, b FROM skyline ORDER BY b;インデックスのプレフィックスからQuery Rangeを抽出できるかどうか。
/* インデックス idx_c_a を使用すると、必要な行の範囲を迅速に特定でき、テーブル全体のスキャンは不要です*/ obclient>SELECT pk, b FROM skyline WHERE c > 100 AND c < 2000;
これら3つの次元に基づいて、Skylineはインデックス間のDominant関係を定義します。インデックスAが3つの次元すべてにおいてインデックスBより劣っておらず、かつ少なくとも1つの次元でBより優れている場合、インデックスBに基づいて最終的に生成される計画はインデックスAより優れている可能性がないと推測できるため、インデックスBを直接削除できます。判断基準は以下のとおりです:
インデックス
idx_Aでテーブルへのアクセスが不要であり、インデックスidx_Bでテーブルへのアクセスが必要な場合、この次元においてインデックスidx_Aはidx_BをDominatesします。インデックス
idx_Aから抽出されるInteresting OrderがベクトルVa<a1, a2, a3 ...an>であり、インデックスidx_Bから抽出されるInteresting OrderがベクトルVb<b1, b2, b3...bm>であり、かつn > mである場合、ai = bi (i=1..m)に対して、この次元においてインデックスidx_Aはidx_BをDominatesします。インデックス idx_A で抽出可能な Query Range の列集合が
Sa<a1, a2, a3 ...an>であり、インデックスidx_Bで抽出可能な Query Range の列集合がSb <b1, b2, b3...bm>である場合、SaがSbの Super Set であれば、この次元においてインデックスidx_Aはidx_Bを Dominates します。
テーブルへの回帰
テーブルへの回帰とは、必要な列がインデックスに存在するかどうかを照会することです。主表とインデックス表の両方にInteresting Orderがなく、Query Rangeを抽出できない場合など、特定のシナリオでは、直接主表を参照することが必ずしも最適な解ではないため、特別な考慮が必要です。
obclient> CREATE TABLE t1(
pk INT PRIMARY KEY, a INT, b INT, c INT, v1 VARCHAR(1000),
v2 VARCHAR(1000), v3 VARCHAR(1000), v4 VARCHAR(1000),INDEX idx_a_b(a, b));
Query OK, 0 rows affected
obclient>SELECT a, b,c FROM t1 WHERE b = 100;
| インデックス | Index Back | Interesting Order | Query Range |
|---|---|---|---|
| primary | no | no | no |
| idx_a_b | yes | no | no |
主表は非常に幅広く、インデックス表は非常に狭いため、次元から分析すると主表のidx_a_bが支配的です。しかし、インデックススキャンとテーブルへの回帰を組み合わせるコストが、主表全体のスキャンよりも高いとは限りません。簡単に言えば、インデックス表は1つのマクロブロックしか読み取らない可能性がありますが、主表は10個のマクロブロックを読み取る必要があるかもしれません。このような場合、ルールを緩めて、具体的なフィルタ条件を総合的に考慮する必要があります。
Interesting Order
オプティマイザーは、Interesting Orderを利用して下層の順序を活用することで、下層でスキャンされる行をソートする必要がなくなり、ORDER BYを省略したり、MERGE GROUP BYを実行したり、パイプライン(マテリアライズが不要)を向上させたりできます。
obclient> CREATE TABLE skyline(
pk INT PRIMARY KEY, v1 INT, v2 INT, v3 INT, v4 INT, v5 INT,
KEY idx_v1_v3_v5(v1, v3, v5),
KEY idx_v3_v4(v3, v4));
Query OK, 0 rows affected
obclient> CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
Query OK, 0 rows affected
obclient> (SELECT DISTINCT v1, v3 FROM skyline JOIN tmp WHERE skyline.v1 = tmp.c1
ORDER BY v1, v3) UNION (SELECT c1, c2 FROM tmp);

実行計画を見ると、ORDER BYが省略されており、同時にMERGE DISTINCTが使用されています。また、UNIONでもSORTが行われていません。これにより、下層のTABLE SCANから出力される順序が、上位の演算子で利用できることがわかります。言い換えれば、idx_v1_v3_v5から出力される行の順序を保持することで、後続の演算子は順序を保ちながらより優れた操作を実行できます。オプティマイザーは、これらの順序を認識した場合にのみ、より優れた実行計画を生成できます。
そのため、Skylineの剪定におけるInteresting Orderの判断では、各インデックスが最大限に活用できる順序を十分に考慮する必要があります。例えば、上記の例では最大の順序は実際には(v1, v3)であり、単にv1だけではありません。それはMERGE JOINから出力される順序(v1, v3)から始まり、MERGE DISTINCT演算子を経て、最終的にUNION DISTINCT演算子に至ります。
クエリ範囲
クエリ範囲を抽出することで、下層が抽出された範囲に基づいて具体的なマクロブロックを直接特定しやすくなり、ストレージ層のI/Oが削減されます。
例えば、SELECT * FROM t1 WHERE pk < 100 AND pk > 0 の場合、一次インデックスの情報に基づいて具体的なマクロブロックを直接特定できるため、クエリが高速化されます。より正確なクエリ範囲は、データベースがスキャンする行数を減らすことができます。
obclient> CREATE TABLE t1 (
pk INT PRIMARY KEY, a INT, b INT,c INT,
KEY idx_b_c(b, c),
KEY idx_a_b(a, b));
Query OK, 0 rows affected
obclient> SELECT b FROM t1 WHERE a = 100 AND b > 2000;
インデックス idx_b_c から抽出できるクエリ範囲のインデックスプレフィックスは (b) であり、インデックス idx_a_b から抽出できるクエリ範囲のインデックスプレフィックスは (a, b) です。したがって、この観点から見ると、インデックス idx_a_b は idx_b_c をドミネートします。
総合的な例
obclient> CREATE TABLE skyline(
pk INT PRIMARY KEY, v1 INT, v2 INT, v3 INT, v4 INT, v5 INT,
KEY idx_v1_v3_v5(v1, v3, v5),
KEY idx_v3_v4(v3, v4));
Query OK, 0 rows affected
obclient> CREATE TABLE tmp (c1 INT PRIMARY KEY, c2 INT, c3 INT);
Query OK, 0 rows affected
obclient> SELECT MAX(v5) FROM skyline WHERE v1 = 100 AND v3 > 200 GROUP BY v1;
| インデックス | Index Back | Interesting order | Query range |
|---|---|---|---|
| primary | 不要です | いいえ | いいえ |
| idx_v1_v3_v5 | 不要です | (v1) | (v1, v3) |
| idx_v3_v4 | 必要です | いいえ | (v3) |
インデックスidx_v1_v3_v5は、3つの次元においても主キーインデックスやインデックスidx_v3_v4より劣っていないことがわかります。そのため、Skylineのトリミングルールに基づき、主キーインデックスとインデックスidx_v3_v4は直接削除されます。次元の適切な定義が、Skylineのトリミングが合理的であるかどうかを決定します。誤った次元設定では、そのインデックスが早期に削除され、最適な計画が生成されない可能性があります。