

ヒストグラムとは、特別なタイプの列統計情報であり、データを一連の順序付きバケットに保存することで、その列のデータ分布特性を記述します。これにより、オプティマイザーはヒストグラムに基づいてより正確な行数を推定できます。
デフォルトでは、オプティマイザーは列のデータが均等に分布していると仮定し、この特性に基づいて行数を推定します。しかし、実際のシナリオでは、ほとんどのテーブルのデータ分布は不均等であるため、この場合はヒストグラムを使用する必要があります。
OceanBaseデータベースのオプティマイザーでは、列のヒストグラム情報はビューALL_TAB_HISTOGRAMS、DBA_TAB_HISTOGRAMS、およびUSER_TAB_HISTOGRAMSに格納され、以下の情報が含まれます:
適用対象
現在、OceanBaseデータベースCommunity Editionは ALL_TAB_HISTOGRAMS および USER_TAB_HISTOGRAMS ビューをサポートしていません
ヒストグラムの基本情報(
tenant_id、table_id、partition_id、column_idを含む)ヒストグラムの統計情報タイプ(情報レベルは
GLOBAL、PARTITION、およびSUBPARTITIONに分類されます)ヒストグラム内の各バケットに累積されたデータ量(現在のバケットとそれ以前のバケットの合計を含む)
ヒストグラム内の各バケットの最大値
ヒストグラム内の各バケットの最大値の頻度
ヒストグラムの種類
OceanBaseデータベースのオプティマイザーは、頻度ヒストグラム、Topkヒストグラム、およびハイブリッドヒストグラムの3種類のヒストグラムをサポートしています。
頻度ヒストグラムでは、各異なる列値がヒストグラムの単一のバケットに対応し、指定されたバケット数は列のNDV値以上である必要があります。
Topkヒストグラムは頻度ヒストグラムの変種であり、Lossy Countingアルゴリズムに基づいています。一部のデータ特徴を取得することで全体のデータ分布を推定します。記録されるデータ数と総データ数の比率は、1-(1/bucket_size) 以上である必要があります。
ハイブリッドヒストグラムは、指定されたデータ量を収集してヒストグラムを構築するものであり、頻度ヒストグラムとTopkヒストグラムの機能を補完するものです。
頻度ヒストグラム
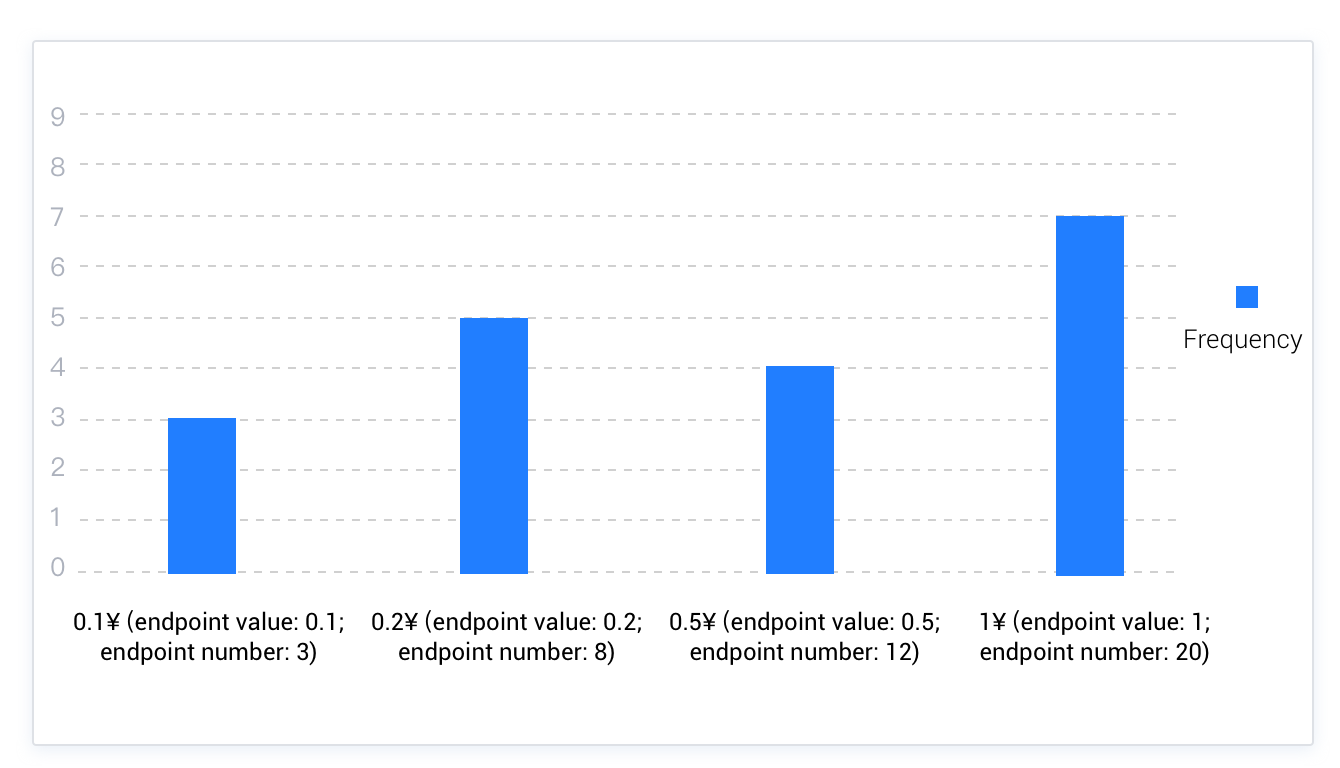
頻度ヒストグラムでは、各異なる列値がヒストグラムの個々のバケットに対応します。各値には専用のバケットが割り当てられているため、一部のバケットには多くの値が含まれる可能性があり、他のバケットには少ない値しか含まれない場合もあります。頻度ヒストグラムの類推としては、硬貨を分類することが挙げられます。例えば、ある財布に0.1元、0.2元、0.5元、1元の4種類の異なる額面の硬貨が合計20枚入っているとします。この場合、0.1元の硬貨をすべて最初のバケットに、0.2元の硬貨をすべて2番目のバケットに、0.5元の硬貨をすべて3番目のバケットに、1元の硬貨をすべて4番目のバケットに分類し、以下のような頻度ヒストグラムが得られます。頻度ヒストグラムの特性を総合すると、指定されたバケット数は列のNDV値以上である必要があります。
Topkヒストグラム
Topkヒストグラムは頻度ヒストグラムの変形であり、指定したバケット数がすべてのNDVを収容するには不十分な場合に選択されます。Topkヒストグラムは本質的に頻度が低いデータを無視し、主に頻度が高いデータの分布を考慮します。例えば、ある財布に0.1元、0.2元、0.5元、1元の4種類の異なる額面の硬貨が合計100枚入っているとします。そのうち0.1元の硬貨はわずか1枚しかありません。また、硬貨を収容するためのバケットは3つしかありません。そのため、0.1元の硬貨は無視して、残りの3種類の硬貨の分布のみを考慮することができ、以下のようなTopkヒストグラムが得られます。
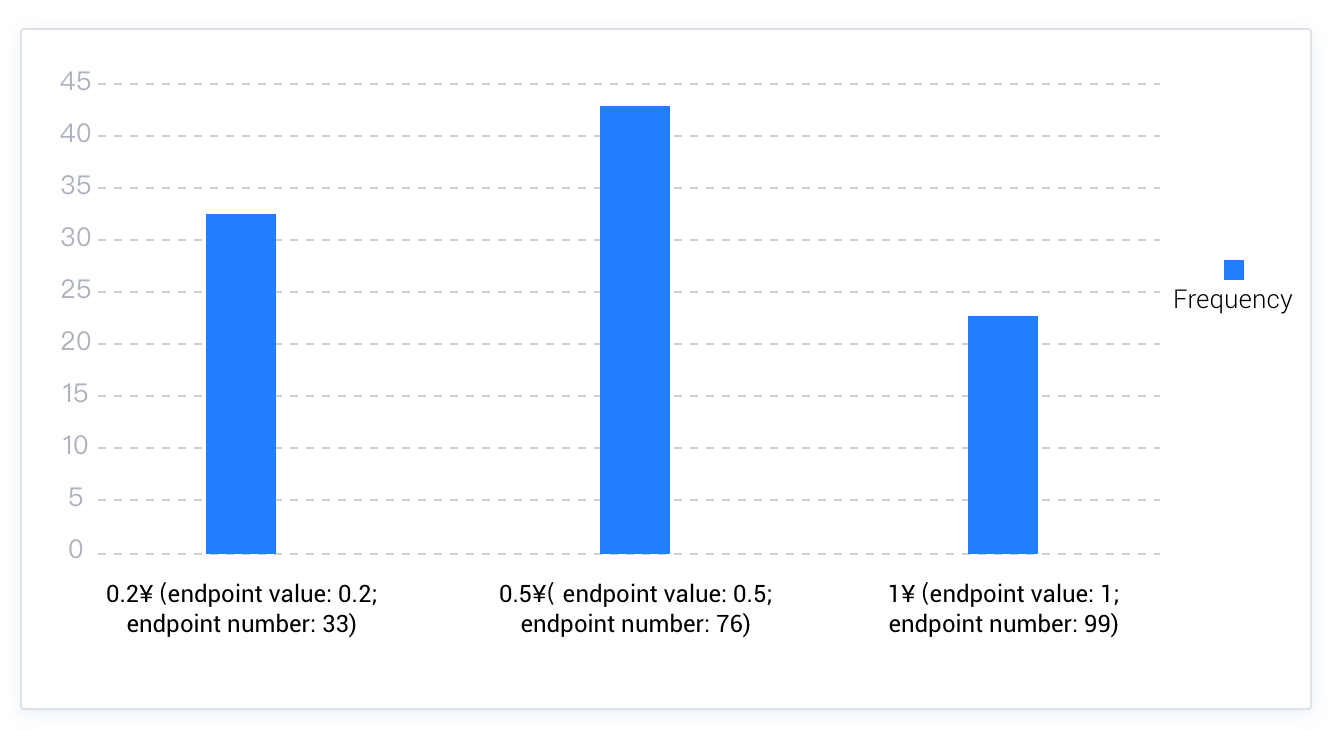
Topkヒストグラムは一部のデータ特徴を取得して全体のデータ分布を推定するため、誤差が大きくならないようにするために、Topkヒストグラムが記録するデータ数と全データ数の比率は1–(1/bucket_size)以上である必要があります。例えば、上記のシナリオでバケット数を3、硬貨の合計数を100と指定し、Topkヒストグラムが99枚のデータを記録した場合、明らかに99/100 > 2/3となり、要件を満たしています。現在、OceanBaseデータベースのオプティマイザーは主にLossy Countingアルゴリズムを用いてTopkヒストグラムを実装しています。
ハイブリッドヒストグラム
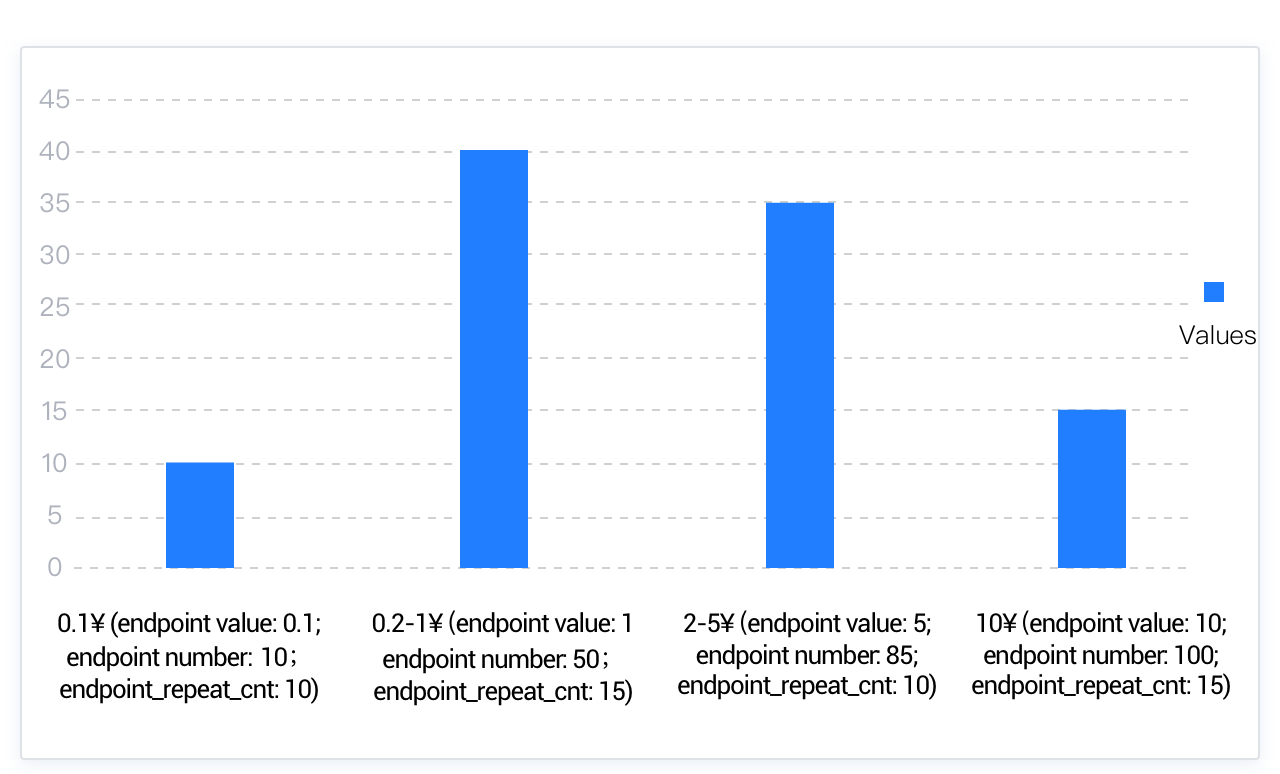
データ量が非常に多い大規模テーブルのシナリオにおいて、指定されたヒストグラムのバケット数がNDV値よりも低く、同時にTopkヒストグラムでも最小限のデータ占有率を満たせない場合、より均等なヒストグラムを用いてデータ分布の特徴を記述する必要があります。これによりハイブリッドヒストグラムが導入されました。ハイブリッドヒストグラムは、指定されたデータ量を収集してヒストグラムを構築します。頻度ヒストグラムやTopkヒストグラムと異なる点として、一つのバケット内に複数の異なるValue値を格納できることが挙げられます。収集したデータ量をバケット数に応じて分割し、各区間内のすべてのデータを対応するバケットに配置することで、より少ないバケット数でより多くのデータ量の分布を表現できます。また、バケット内の最大Value値をendpoint_valueとし、さらにendpoint_repeat_cntというフィールドを追加してendpoint_valueの頻度を記録します。
例えば、同じく100枚のコインがあるとします。0.1元が10枚、0.2元が10枚、0.5元が15枚、1元が15枚、2元が25枚、5元が10枚、10元が15枚です。これに基づいて計算すると、Topkヒストグラムがカバーするデータの割合は(25+15+15+15)/100=0.7となります。一方、Topkヒストグラムがカバーするデータの割合の最小しきい値は1-1/N =3/4=0.75です。このしきい値に達していないため、Topkヒストグラムの条件を満たしていません。そのため、バケット数を4と指定した場合(バケット数が列のNDV値よりも低く、頻度ヒストグラムの条件を満たしていない)、構築されるハイブリッドヒストグラムは以下のようになります。
ヒストグラムの選択ポリシー
OceanBaseデータベースのオプティマイザーは、列から収集した情報をもとにヒストグラムを作成する際、バケット数がオプティマイザーのパフォーマンスに与える影響を考慮します(バケット数が多すぎると検索性能やデータストレージに悪影響を及ぼします)。そのため、一般的にはデフォルトで1つの列のNDV値がヒストグラムのバケット数(bucket_size)以下であることが望ましいとされており、デフォルト値は254です。
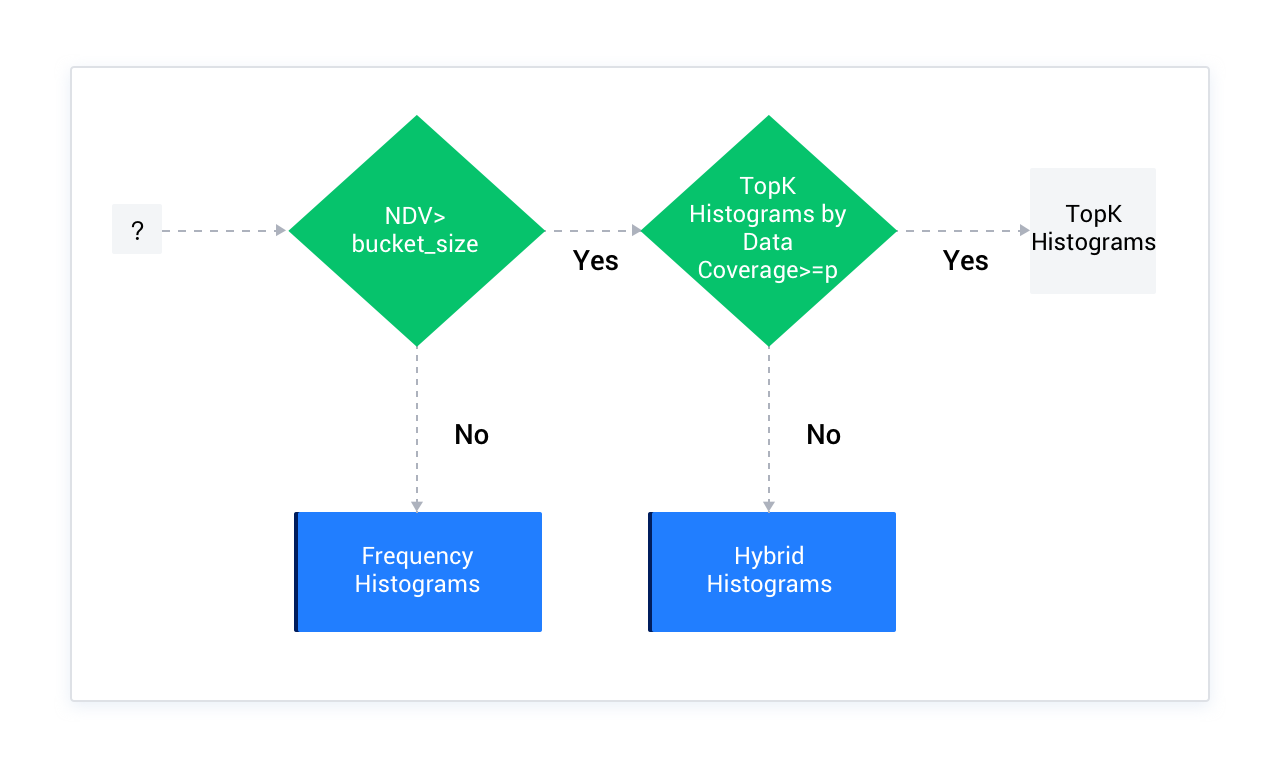
指定された列上の異なる値のNDV(Number of Distinct Values)の数が254以下の場合、頻度ヒストグラムを使用します。
254を超える場合は、TopKヒストグラムを優先的に使用します。具体的な方法としては、列の情報を統計処理した後、バケットに対応する頻度を降順にソートし、番号が254を超えるバケットを除外します。ただし、この254個のバケットによって統計されたデータ量と総データ量の比率が1 - (1/bucket_size)以上であることを保証する必要があります。デフォルト値は99.6%です。
2の条件を満たさない場合は、ハイブリッドヒストグラムを使用します。バケットを再定義することで、各バケットがより多くのデータを表現できるようにし、同時に新しい値を導入してバケットの定義を詳細に記述します。これには、バケットの端点値(endpoint_value)と端点値の頻度(endpoint_repeat_cnt)が含まれます。