

ディストリビューション実行計画はHintを使用して管理でき、SQLクエリのパフォーマンスを向上させることができます。
ディストリビューション実行フレームワークがサポートするHintには、ORDERED、LEADING、USE_NL、USE_HASH、USE_MERGEなどが含まれます。
PARALLEL ヒント
分散実行の並列度を指定します。次の例のように、3つのワーカーで並列スキャンを有効にします。
obclient> SELECT /*+ PARALLEL(3) */ MAX(L_QUANTITY) FROM tbl1;
OceanBaseデータベースは、テーブルレベルのPARALLELヒントもサポートしており、構文は以下のとおりです。
/*+ PARALLEL(table_name n) */
グローバル並列度とテーブルレベルの並列度が同時に指定されている場合、テーブルレベルの並列度は適用されません。
注意
複雑なクエリでは、スケジューラーは2つのDFOを並列的にスイムステート実行することができます。この場合、有効なワーカー数は並列度の2倍、つまりPARALLEL * 2となります。
ORDEREDヒント
ORDERED ヒントは、パラレルクエリ計画内の JOIN の順序を指定し、FROM ステートメントの順序に厳密に従って生成されます。
以下の例のように、customer を左側のテーブル、orders を右側のテーブルとして強制的に指定し、NESTED LOOP JOIN を使用します。
obclient> CREATE TABLE lineitem(
l_orderkey NUMBER(20) NOT NULL ,
l_linenumber NUMBER(20) NOT NULL ,
l_quantity NUMBER(20) NOT NULL ,
l_extendedprice DECIMAL(10,2) NOT NULL ,
l_discount DECIMAL(10,2) NOT NULL ,
l_tax DECIMAL(10,2) NOT NULL ,
l_shipdate DATE NOT NULL,
PRIMARY KEY(L_ORDERKEY, L_LINENUMBER));
Query OK, 1 row affected
obclient> CREATE TABLE customer(
c_custkey NUMBER(20) NOT NULL ,
c_name VARCHAR(25) DEFAULT NULL,
c_address VARCHAR(40) DEFAULT NULL,
c_nationkey NUMBER(20) DEFAULT NULL,
c_phone CHAR(15) DEFAULT NULL,
c_acctbal DECIMAL(10,2) DEFAULT NULL,
c_mktsegment CHAR(10) DEFAULT NULL,
c_comment VARCHAR(117) DEFAULT NULL,
PRIMARY KEY(c_custkey));
Query OK, 1 row affected
obclient> CREATE TABLE orders(
o_orderkey NUMBER(20) NOT NULL ,
o_custkey NUMBER(20) NOT NULL ,
o_orderstatus CHAR(1) DEFAULT NULL,
o_totalprice DECIMAL(10,2) DEFAULT NULL,
o_orderdate DATE NOT NULL,
o_orderpriority CHAR(15) DEFAULT NULL,
o_clerk CHAR(15) DEFAULT NULL,
o_shippriority NUMBER(20) DEFAULT NULL,
o_comment VARCHAR(79) DEFAULT NULL,
PRIMARY KEY(o_orderkey,o_orderdate,o_custkey));
Query OK, 1 row affected
obclient> INSERT INTO lineitem VALUES(1,2,3,6.00,0.20,0.01,'01-JUN-02');
Query OK, 1 row affected
obclient> INSERT INTO customer VALUES(1,'Leo',null,null,'1390000****',null,'BUILDING',null);
Query OK, 1 row affected
obclient> INSERT INTO orders VALUES(1,1,null,null,'01-JUN-20',10,null,8,null);
Query OK, 1 row affected
obclient>SELECT /*+ ORDERED USE_NL(orders) */o_orderdate, o_shippriority
FROM customer, orders WHERE c_mktsegment = 'BUILDING' AND
c_custkey = o_custkey GROUP BY o_orderdate, o_shippriority;
+-------------+----------------+
| O_ORDERDATE | O_SHIPPRIORITY |
+-------------+----------------+
| 01-JUN-20 | 8 |
+-------------+----------------+
1 row in set
手書きのSQLでは、ユーザーが JOIN の最適な順序を知っている場合、テーブルを FROM の後に順番に記述し、その後に ORDERED ヒントを追加することで、ORDERED ヒントは非常に便利です。
LEADING ヒント
LEADING ヒントは、パラレルクエリ計画で最初に JOIN するテーブルを指定します。LEADING 内のテーブルの順序は、左から右への順序であり、これが JOIN の順序でもあります。これは ORDERED よりも柔軟性が高いです。
注意
ORDERED と LEADING ヒントを同時に使用した場合、ORDERED ヒントのみが有効になります。
PQ_DISTRIBUTE ヒント
PQ ヒント、すなわち PQ_DISTRIBUTE は、パラレルクエリ計画内のデータ配布方法を指定するために使用されます。PQ ヒントは、分散 JOIN 時のデータ配布方法を変更します。
PQ ヒントの基本構文は次のとおりです:
PQ_DISTRIBUTE(tablespec outer_distribution inner_distribution)
パラメータの説明は以下のとおりです:
tablespecは、対象となるテーブルを指定し、JOINの右側のテーブルに注目します。outer_distributionは、左側のテーブルのデータ配布方法を指定します。inner_distributionは、右側のテーブルのデータ配布方法を指定します。
2つのテーブルのデータ配布方法には、以下の6種類があります:
HASH,HASHBROADCAST,NONENONE,BROADCASTPARTITION,NONENONE,PARTITIONNONE,NONE
そのうち、パーティションを伴う2つの配布方法では、左側または右側のテーブルにパーティションが存在し、かつパーティションキーが JOIN のキーであることが求められます。要件を満たさない場合、PQ ヒントは有効になりません。
obclient> CREATE TABLE t1(c1 INT PRIMARY KEY, c2 INT, c3 INT, c4 DATE);
Query OK, 0 rows affected
obclient> CREATE INDEX i1 ON t1(c3);
Query OK, 0 rows affected
obclient> CREATE TABLE t2(c1 INT(11) NOT NULL, c2 INT(11) NOT NULL, c3 INT(11) NOT NULL, PRIMARY KEY (c1, c2, c3)) PARTITION BY KEY(c2) PARTITIONS 4;
Query OK, 0 rows affected
obclient> EXPLAIN BASIC SELECT /*+USE_PX PARALLEL(3) PQ_DISTRIBUTE
(t2 BROADCAST NONE) LEADING(t1 t2)*/ * FROM t1 JOIN t2 ON
t1.c2 = t2.c2;
Query Plan:
================================================
|ID|OPERATOR |NAME |
------------------------------------------------
|0 |EXCHANGE IN DISTR | |
|1 | EXCHANGE OUT DISTR |:EX10001|
|2 | HASH JOIN | |
|3 | EXCHANGE IN DISTR | |
|4 | EXCHANGE OUT DISTR (BROADCAST)|:EX10000|
|5 | PX BLOCK ITERATOR | |
|6 | TABLE SCAN |t1 |
|7 | PX BLOCK ITERATOR | |
|8 | TABLE SCAN |t2 |
================================================
USE_NL ヒント
USE_NL ヒントは、NESTED LOOP JOIN を使用することを指定し、かつ USE_NL で指定されたテーブルが JOIN の右側のテーブルである必要があります。
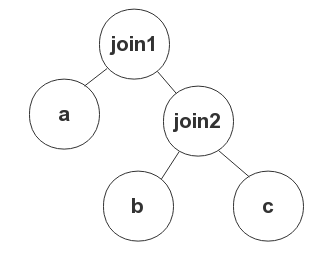
以下の例のように、join1 を NESTED LOOP JOIN にしたい場合、ヒントの書き方は LEADING(a, (b,c)) USE_NL((b,c)) となります。
USE_NL ヒントと ORDERED、LEADING ヒントを一緒に使用する場合、USE_NL で指定されたテーブルが右側のテーブルでない場合、USE_NL ヒントは無視されます。
USE_HASH ヒント
USE_HASH ヒントは、HASH JOIN を使用することを指定し、かつ USE_HASH で指定されたテーブルが JOIN の右側のテーブルである必要があります。
注意
ORDERED および LEADING ヒントを使用していない場合、かつオプティマイザーが生成した結合順序で指定されたテーブル間に直接 JOIN の関係がない場合、USE_HASH ヒントは無視されます。
USE_MERGE ヒント
USE_MERGE ヒントは、MERGE JOIN を使用することを指定し、かつ USE_MERGE で指定されたテーブルが JOIN の右側のテーブルである必要があります。
注意
ORDERED および LEADING ヒントを使用していない場合、かつオプティマイザーが生成した結合順序で指定されたテーブル間に直接 JOIN の関係がない場合、USE_MERGE ヒントは無視されます。