

OceanBaseデータベースV3.x系では、レプリカはパーティション単位で複数のノードに分散されており、ロードバランシングモジュールはパーティションのリーダー切り替えやパーティションレプリカの移行などの方法でテナント内のパーティションロードバランシングを実現します。V4.x系では、スタンドアロンログストリームアーキテクチャへとアップグレードされたため、レプリカはログストリーム単位で分散され、各ログストリームには多数のパーティションが存在します。そのため、V4.2.x系では、ロードバランシングモジュールは直接パーティションの分散を制御することができず、まずLS(Log Stream)の数とリーダーを均衡させた上で、その後にログストリームの分散に基づいてパーティションの均衡を図る必要があります。
注意
パーティションの均衡はユーザーテーブルに対してのみ適用されます。
LS均衡とパーティション均衡の優先順位は以下の通りです:
LS均衡 > パーティション均衡
LS均衡
LS数の均衡
ユーザーがテナントに対して UNIT_NUM の変更、PRIMARY_ZONE の第一優先順位の変更、ローカリティの変更(PRIMARY_ZONE に影響を与える)などの操作を実行すると、ロードバランシングモジュールのバックグラウンドスレッドは直ちにLSの分割、LSの統合、LSグループの変更などのアクションを通じて、LSの数と位置を変更し、ユーザーが変更した後のテナント状態を満たします。すなわち、各テナントのUnitには1つのログストリームグループがあり、ログストリームグループ内のログストリームの数は PRIMARY_ZONE の第一優先順位の数に等しく、リーダーはログストリームグループ内で各Zoneに均等に分散されます。
説明
- LSグループはLSの属性であり、LSグループIDが同一のログストリームはまとめて扱われます。
- V4.0.0以降のバージョンから、OceanBaseデータベースではテナント内の各ZoneのUnit数を一定に保つことが求められます。各ZoneのUnitを一元管理しやすくするため、システムはUnitグループメカニズムを導入しました。これにより、異なるZone間で同一の番号(UNIT_GROUP_ID)を持つUnitは同一のUnitグループに属します。Unitグループ内のすべてのUnit上のデータ分布は同一であり、同一のログストリームレプリカを持ち、同一のパーティションデータにサービスを提供します。リソースコンテナ上では、Unitグループは一連のデータを定義し、このデータは1つまたは複数のログストリームによってサービスされ、読み書きサービス能力はUnitグループ内の複数のUnitに拡張可能です。
- 1つのLSグループは唯一のUnitグループに対応し、同一のLSグループIDを持つログストリームは同一のUnitグループ内に配置されます。
LS数の計算式は以下のとおりです:
LS数 = UNIT_NUM * first_level_primary_zone_num
LS数の均衡のシナリオは以下の表のとおりです。
| バランシングがトリガーされるシナリオ例 | バランシング条件 | バランシングアルゴリズム | LSバランシングポリシー |
|---|---|---|---|
PRIMARY_ZONE:z1, z2 から z1 へ変更同時に UNIT_NUM:1 から 2 へ変更 |
LS Group内にLSが不足しているものと、LSが過剰なものが混在するが、LSの総数は最終状態に合致する | 冗長LSをLSが不足しているLS Groupに移行 | LS_BALANCE_BY_MIGRATE |
PRIMARY_ZONE: z1 から z1,z2 へ変更 または UNIT_NUM:2 から 3 へ変更 |
LS GroupがLS不足のみ存在 | 現在のLS数をM、拡張後のLS数をN(M < N)と仮定すると、不足している各LSには M/N のTabletが必要になります |
LS_BALANCE_BY_EXPAND |
PRIMARY_ZONE: z1,z2 から z1 へ変更 または UNIT_NUM:3 から 2 へ変更 |
LS GroupがLS過剰のみ存在 | 現在のLS数をM、縮小後のLS数をN(M > N)と仮定すると、残りの各LSには (M-N)/N のTabletを割り当てる必要があります |
LS_BALANCE_BY_SHRINK |
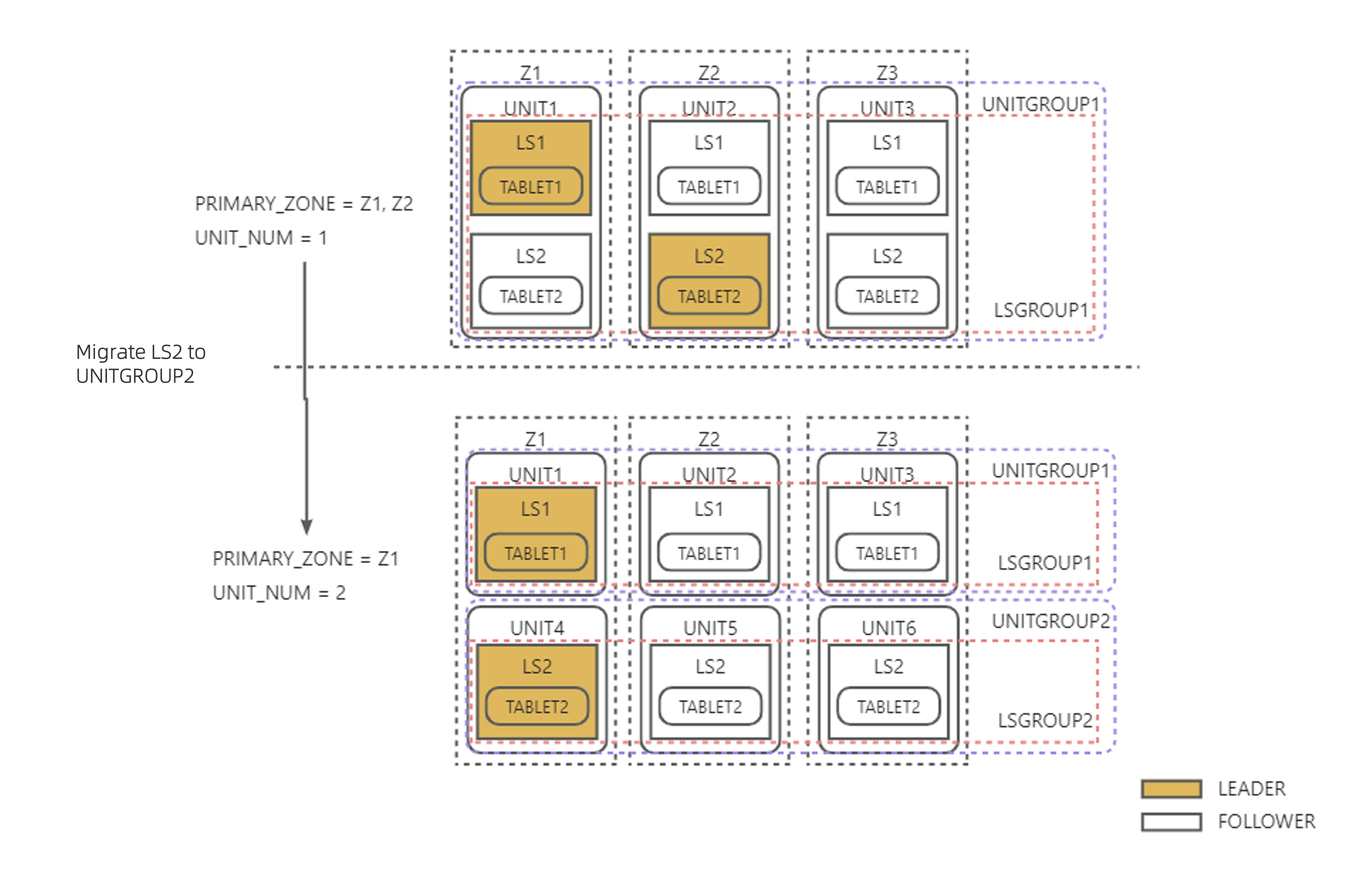
例1:以下の図に示すように、PRIMARY_ZONE の第一優先順位が Z1, Z2 から Z1 に変更されます。同時に UNIT_NUM は 1 から 2 に変更する必要があります。変更前後でLS数は変わらず、LS2 を新規作成されたUnitに直接移行し、LS2 は PRIMARY_ZONE の変更に基づいて Z1 へのリーダー切り替えを行い、最終的にLSの均衡が完了します。
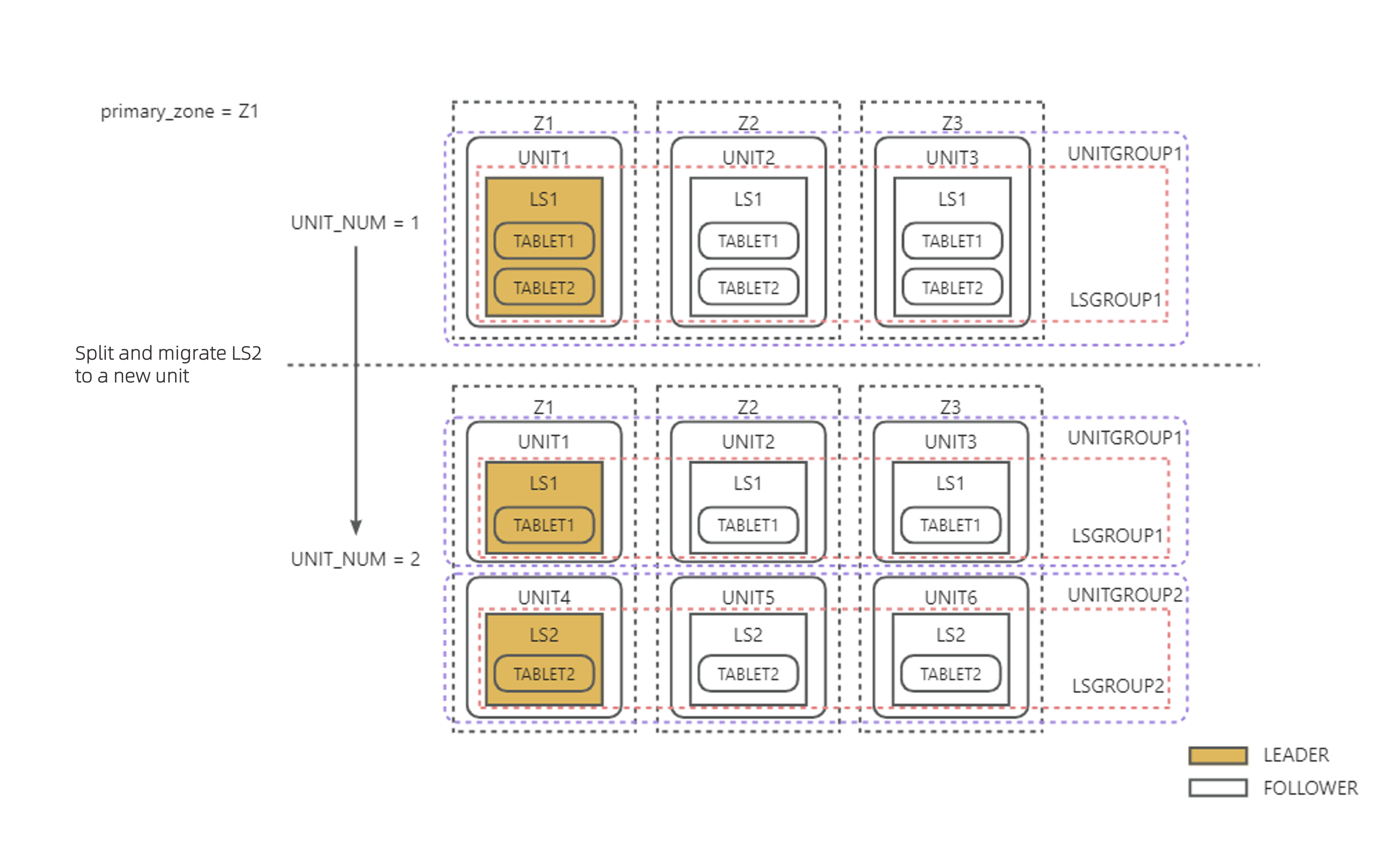
例2:以下の図に示すように、PRIMARY_ZONE = Z1 で、UNIT_NUM が 1 から 2 に変更されます。各UnitにLSが存在するようにするため、LS2を分割し、Tabletの1/2を引き継いで新しいUnitに移行します。
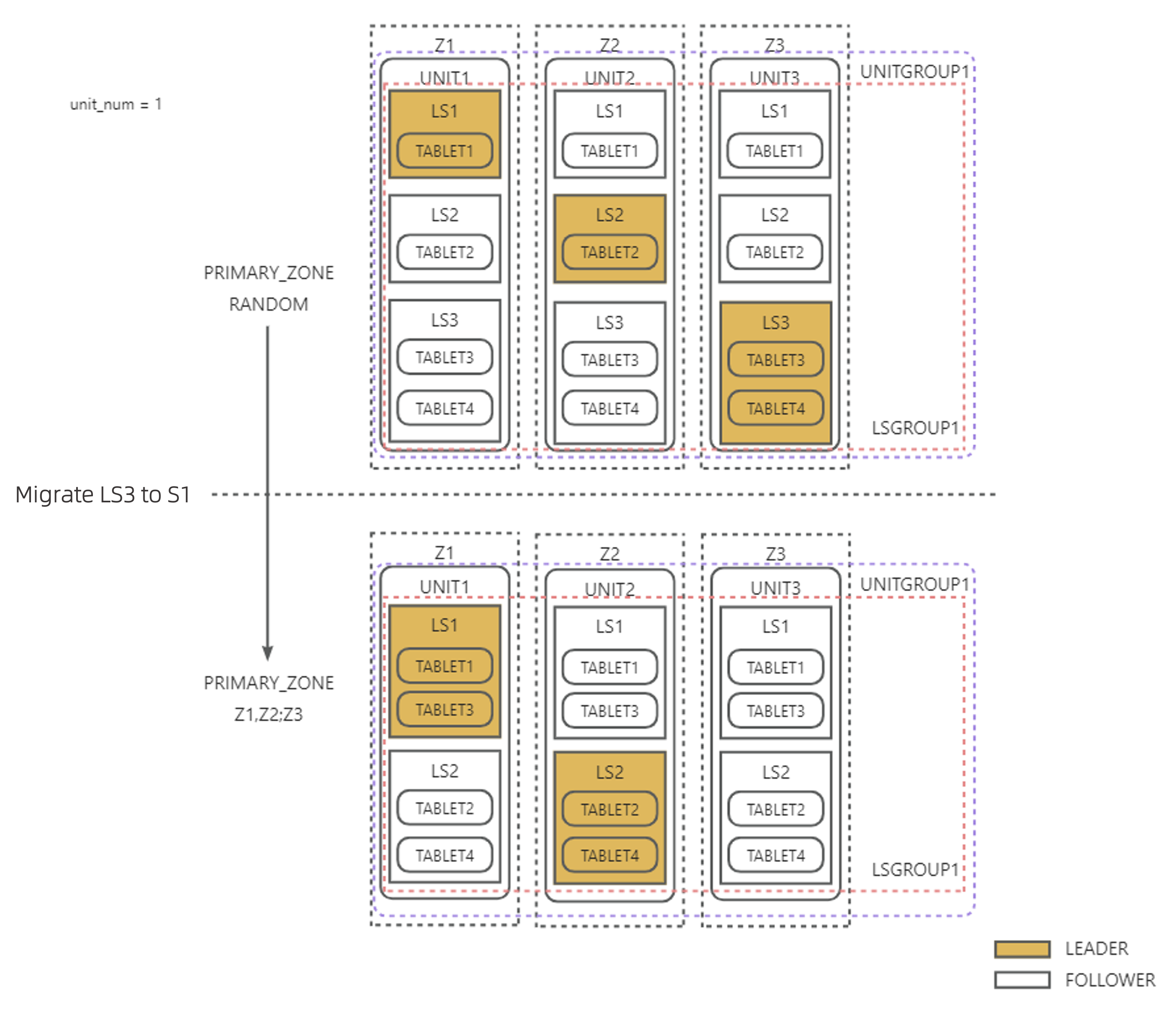
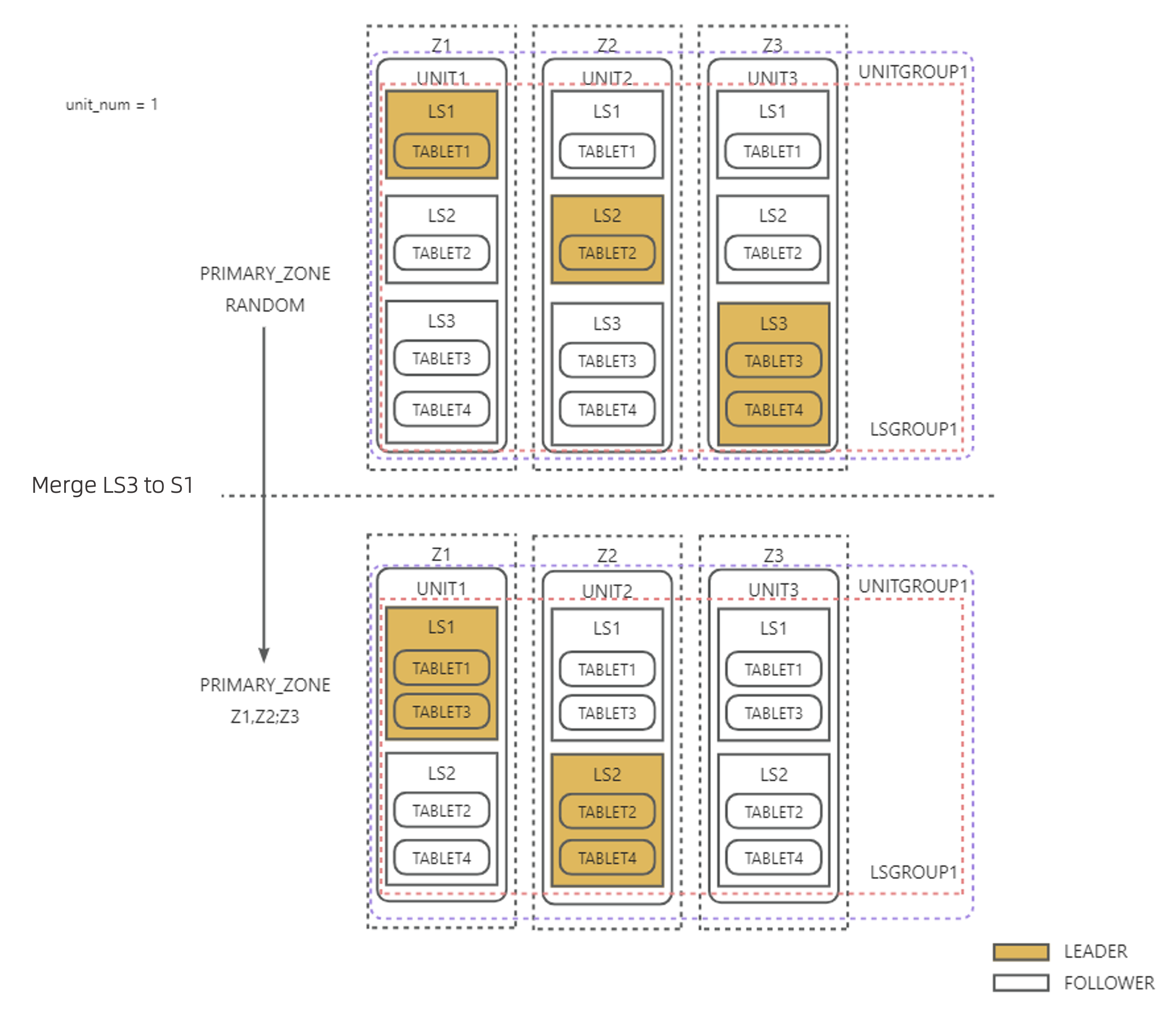
例3:以下の図に示すように、UNIT_NUM = 1 で、PRIMARY_ZONE の第一優先順位が RANDOM から Z1,Z2 に変更されます。リーダーが PRIMARY_ZONE の第一優先順位のZone上にのみ存在するようにするとともに、均衡後にログストリーム上のTablet数も均衡させる必要があります。LS3 は他のLSと同一のLSグループ内にあるため、LS3 からTabletの1/2を直接 LS1 に転送し、その後 LS3 を LS2 に統合して、残りのTabletの1/2を LS2 が担うようにすることで、LS数を減らしつつTablet数の均衡を維持できます。
LSリーダーの均衡
LSリーダーの均衡とは、LS数が均衡していることを前提に、LSリーダーをプライマリゾーン上に均等に配置することです。例えば、ユーザーがテナントのPRIMARY_ZONEを変更した後、ロードバランシングのバックグラウンドスレッドはPRIMARY_ZONEの第一優先順位に基づいて動的にLS数を調整し、その後LSのリーダー切り替えを行い、第一優先順位の各ゾーン内にリーダーが1つだけ存在するようにします。
例1:以下の図のように、UNIT_NUM = 1で、PRIMARY_ZONEの第一優先順位がZ1からZ1,Z2に変更された場合、PRIMARY_ZONEの第一優先順位のすべてのゾーンにリーダーが存在するように、同一Unit内で新しいLSを分裂させ、その後LSリーダーの均衡によって新しいLSのリーダーをZ2に切り替えます。
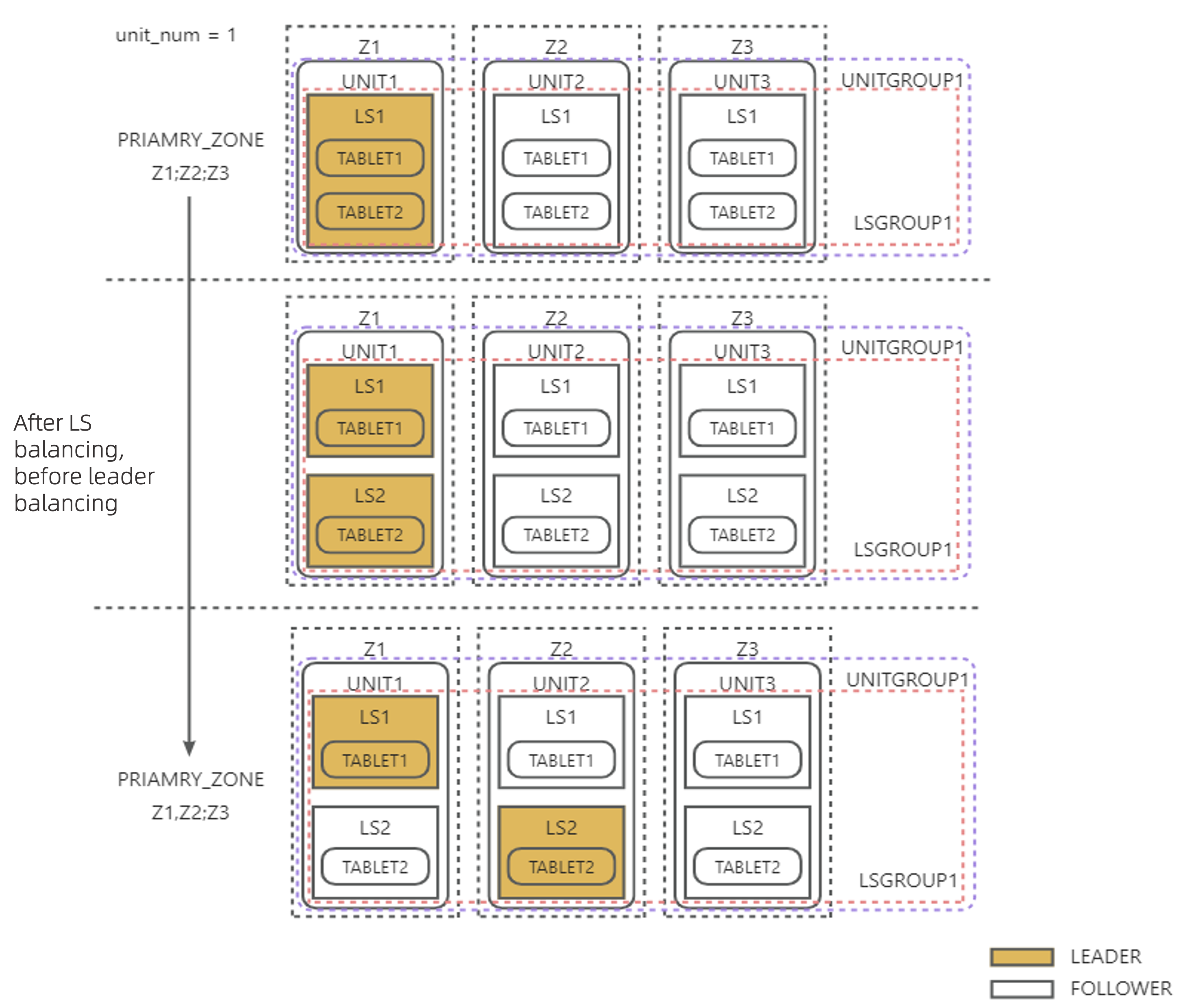
例2:以下の図のように、UNIT_NUM = 1で、PRIMARY_ZONEの第一優先順位がRANDOMからZ1,Z2に変更された場合、LS数の均衡によってLS3を他のLSに統合した後、残りのLSリーダーは自然にZ1とZ2に均等に分散され、追加のLSリーダーの均衡は不要です。
テーブル作成時のパーティションの割り当て
ユーザーがユーザーテーブルを作成する際、OceanBaseデータベースは一連の均等な割り当て戦略を用いて、各ユーザーログストリームにパーティションを分散または集約し、各ログストリーム上のパーティションが相対的に均等になるようにします。
指定されたTable Groupのユーザーテーブル
ユーザーはTable Groupを指定することで、異なるテーブル間の集約および分散ルールを柔軟に設定できます。ユーザーテーブルを作成する際に、対応するShardingプロパティのTable Groupが指定されている場合、新規ユーザーテーブルのパーティションはTable Groupのルールに従って対応するユーザーのLSに割り当てられます。Table Groupのルールは以下の表に示されています。
| テーブルグループのシャーディングプロパティ | 説明 | パーティショニング方式の要件 | アライメントルール |
|---|---|---|---|
| NONE | すべてのテーブルのすべてのパーティションが同一サーバーに集約される | 制限なし | すべてのパーティションと、テーブルグループ内でtable_idが最小のテーブルのパーティションが同一LSに集約される |
| PARTITION | パーティション単位で分散する。コンポジット・パーティションテーブルの場合は、パーティション単位のすべてのコンポジット・パーティションがまとめられる | すべてのテーブルのパーティション単位のパーティショニング方式が同一であること。また、コンポジット・パーティションテーブルの場合も、パーティション単位のパーティショニング方式のみを検証する。したがって、パーティション単位のパーティショニング方式が同一であれば、パーティション単位のパーティションテーブルとコンポジット・パーティションテーブルを同時に存在させることが可能である。 | 同一パーティション値のパーティションがまとめられる。これには、パーティション単位のパーティションテーブルのパーティションおよび、コンポジット・パーティションテーブルの対応するパーティション単位のすべてのコンポジット・パーティションが含まれる。 |
| ADAPTIVE | アダプティブ分散方式。テーブルグループ内がパーティション単位のパーティションテーブルの場合はパーティション単位で分散し、コンポジット・パーティションテーブルの場合は各パーティション単位のコンポジット・パーティションごとに分散する。 |
|
|
注意
テーブル作成前にTable Group内にユーザーテーブルが既に存在している場合、その後に作成されるテーブルはTable Group内のtable_idが最小のユーザーテーブルに対応するパーティションの分布に従って整合します。
Table Groupの詳細については、Table Groupについてを参照してください。
通常のユーザーテーブル
Table Groupを指定せずに通常のユーザーテーブルを作成する場合、OceanBaseデータベースは新規パーティションをすべてのユーザーLSに分散させるようデフォルトで設定されています。具体的なルールは以下のとおりです。
パーティションテーブル以外:新規パーティションは、パーティション数が最も少ないユーザーLSに割り当てられます。
パーティションテーブル:パーティションテーブルでは、パーティションがRound Robinアルゴリズムに基づいて、すべてのユーザーLSに均等に分散されます。
サブパーティションテーブル:サブパーティションテーブルでは、各パーティションのすべてのサブパーティションがRound Robinアルゴリズムに基づいて、すべてのユーザーLSに均等に分散されます。
以下の例をいくつか挙げて説明します。
例1:MySQLモードでそれぞれ
tt1、tt2、tt3、tt4の4つのパーティションテーブルを作成します。obclient [test]> CREATE TABLE tt1(c1 int);obclient [test]> CREATE TABLE tt2(c1 int);obclient [test]> CREATE TABLE tt3(c1 int);obclient [test]> CREATE TABLE tt4(c1 int);4つのテーブルのパーティションの分布状況を照会します。
obclient [test]> SELECT table_name,partition_name,subpartition_name,ls_id,zone FROM oceanbase.DBA_OB_TABLE_LOCATIONS WHERE table_name in('tt1','tt2','tt3','tt4') AND role='LEADER';クエリ結果は次のとおりです。
+------------+----------------+-------------------+-------+------+ | table_name | partition_name | subpartition_name | ls_id | zone | +------------+----------------+-------------------+-------+------+ | tt1 | NULL | NULL | 1001 | z1 | | tt2 | NULL | NULL | 1002 | z2 | | tt3 | NULL | NULL | 1003 | z3 | | tt4 | NULL | NULL | 1001 | z1 | +------------+----------------+-------------------+-------+------+ 4 rows in set例2:さらにパーティションテーブル
tt5を作成します。obclient [test]> CREATE TABLE tt5(c1 int) PARTITION BY HASH(c1) PARTITIONS 6;このパーティションテーブルの分布状況を確認します。
obclient [test]> SELECT table_name,partition_name,subpartition_name,ls_id,zone FROM oceanbase.DBA_OB_TABLE_LOCATIONS WHERE table_name ='tt5' AND role='LEADER';クエリ結果は次のとおりです。このテーブルのパーティションは、Round Robinアルゴリズムに基づいて、
1001、1002、1003などのログストリームに均等に分散されています。+------------+----------------+-------------------+-------+------+ | table_name | partition_name | subpartition_name | ls_id | zone | +------------+----------------+-------------------+-------+------+ | tt5 | p0 | NULL | 1003 | z3 | | tt5 | p1 | NULL | 1001 | z1 | | tt5 | p2 | NULL | 1002 | z2 | | tt5 | p3 | NULL | 1003 | z3 | | tt5 | p4 | NULL | 1001 | z1 | | tt5 | p5 | NULL | 1002 | z2 | +------------+----------------+-------------------+-------+------+ 6 rows in set例3:サブパーティションテーブル
tt8を作成します。obclient [test]> CREATE TABLE tt8 (c1 int, c2 int, PRIMARY KEY(c1, c2)) PARTITION BY HASH(c1) SUBPARTITION BY RANGE(c2) SUBPARTITION TEMPLATE (SUBPARTITION p0 VALUES LESS THAN (1990), SUBPARTITION p1 VALUES LESS THAN (2000), SUBPARTITION p2 VALUES LESS THAN (3000), SUBPARTITION p3 VALUES LESS THAN (4000), SUBPARTITION p4 VALUES LESS THAN (5000), SUBPARTITION p5 VALUES LESS THAN (MAXVALUE)) PARTITIONS 2;テーブル
tt8のパーティションの分布状況を確認します。obclient [test]> SELECT table_name,partition_name,subpartition_name,ls_id,zone FROM oceanbase.DBA_OB_TABLE_LOCATIONS WHERE table_name ='tt8' AND role='LEADER';クエリ結果は次のとおりです。このテーブルのサブパーティションのすべてのサブパーティションは、Round Robinアルゴリズムに基づいて、ユーザーのすべてのLSに均等に分散されています。
+------------+----------------+-------------------+-------+------+ | table_name | partition_name | subpartition_name | ls_id | zone | +------------+----------------+-------------------+-------+------+ | tt8 | p0 | p0sp0 | 1001 | z1 | | tt8 | p0 | p0sp1 | 1002 | z2 | | tt8 | p0 | p0sp2 | 1003 | z3 | | tt8 | p0 | p0sp3 | 1001 | z1 | | tt8 | p0 | p0sp4 | 1002 | z2 | | tt8 | p0 | p0sp5 | 1003 | z3 | | tt8 | p1 | p1sp0 | 1002 | z2 | | tt8 | p1 | p1sp1 | 1003 | z3 | | tt8 | p1 | p1sp2 | 1001 | z1 | | tt8 | p1 | p1sp3 | 1002 | z2 | | tt8 | p1 | p1sp4 | 1003 | z3 | | tt8 | p1 | p1sp5 | 1001 | z1 | +------------+----------------+-------------------+-------+------+ 12 rows in set
特殊なユーザーテーブル
通常のユーザーテーブルに加えて、ローカルインデックステーブル、グローバルインデックステーブル、レプリケーションテーブルといった特殊なユーザーテーブルがあり、それぞれ特別な割り当てルールを持っています。具体的には以下の通りです:
ローカルインデックステーブル:ユーザーテーブルのパーティションルールと同じで、各パーティションはメインテーブルのパーティション配置と結びついています。
グローバルインデックステーブル:デフォルトではパーティション化されておらず、テーブル作成時にパーティション数が最も少ないユーザーLSに分散されます。
レプリケーションテーブル:レプリケーションテーブルはブロードキャストログストリーム上にのみ存在します。
パーティションの均衡
LS均衡の基礎の上で、ロードバランシングモジュールはTransferを通じて、パーティショントータルを異なるLSに分散または集約し、テナント内のパーティションの均衡を実現します。パーティションの均衡時間間隔は、テナントレベルの構成パラメータpartition_balance_schedule_intervalで制御され、デフォルトでは2時間ごとに実行され、各実行では1種類のパーティション均衡戦略のみが実行されます。構成パラメータpartition_balance_schedule_intervalの値を0sに設定すると、パーティションの均衡は行われないことを意味します。
パーティション均衡戦略の優先順位は以下のとおりです:
パーティション属性の整合性 > パーティション数の均衡 > パーティションディスクの均衡
パーティション属性の整列
テーブルグループの整列
ユーザーがSQLステートメントを使用してテーブルのテーブルグループ属性またはテーブルグループのシャーディング属性を変更する場合、バックグラウンドで実行されるパーティション均衡タスクが完了するまで待機する必要があります。これにより、期待どおりのパーティション分布が実現します。迅速な整列を実現するために、一時的にテナントレベルの構成パラメータpartition_balance_schedule_intervalの値を小さく設定できます。
テーブルグループ内のテーブルのパーティション分布ルールについては、本記事のTable Groupを指定するユーザーテーブルの内容を参照してください。
テーブルグループの詳細については、テーブルグループについてを参照してください。
duplicate_scopeの整列
OceanBaseデータベースV4.3.5では、V4.3.5 BP1以降のバージョンから複製テーブルの属性変更がサポートされています。複製テーブルはブロードキャストログストリーム上にのみ存在できます。ユーザーがduplicate_scope属性を変更した後、パーティション均衡の実行が完了するまで、期待どおりの属性で使用することはできません。迅速な整列を実現するために、一時的にテナントレベルの構成パラメータpartition_balance_schedule_intervalの値を小さく設定できます。
複製テーブルの属性変更の詳細な手順については、複製テーブルの属性の変更(MySQLモード)および複製テーブルの属性の変更(Oracleモード)を参照してください。
パーティション数の均衡化
パーティション数の均衡化とは、すべてのユーザーのLS上におけるユーザーテーブルの主テーブルパーティション数を均等にすることを目指します(数値の偏差は1以下です)。
実装面では、OceanBaseデータベースは「均衡グループ」という概念を用いて分散関係を記述し、分散させる必要があるパーティションを同一の均衡グループ内に分類し、グループ内均衡とグループ間均衡の手法によってパーティション数の均衡化を実現します。
Table Groupがない場合、均衡グループの分割方法は以下の通りです:
| テーブルタイプ | バランスグループ分割 | 分散方式(Table Groupなし) |
|---|---|---|
| 非パーティションテーブル | テナント内のすべての非パーティションテーブルは1つのバランスグループです。 | テナント内のすべての非パーティションテーブルが、ユーザーのすべてのLSに均等に分散されます(数の偏差は1以下)。 |
| パーティションテーブル | 各テーブルのすべてのパーティションは1つのバランスグループです。 | 各テーブル単位で、パーティションがユーザーのすべてのLSに均等に分散されます。 |
| サブパーティションテーブル | 単一テーブル内の各パーティションのすべてのサブパーティションは1つのバランスグループです。 | 単一テーブル内の各パーティションのすべてのサブパーティションが、ユーザーのすべてのLSに均等に分散されます。 |
均衡化段階では、システムはまずすべての均衡グループに対してグループ内均衡を行い、つまりグループ内のパーティションを均等に分布させます。その後、グループ内均衡を基に、パーティション数が最も多いLSから一部のパーティションを転送し、グループ間均衡を行うことで、パーティション数の均衡化を実現します。
例えば、既存の4つのテーブルのすべてのパーティションがLS1上にあり、3つの均衡グループに分かれている場合:
均衡グループ1:非パーティションテーブル
non_part_t1、non_part_t2均衡グループ2:パーティションテーブルの2つのパーティション
part_one_t3_p0、part_one_t3_p1均衡グループ3:サブパーティションテーブルの4つのパーティション
part_two_t4_p0s0、part_two_t4_p0s1、part_two_t4_p1s0、part_two_t4_p1s1
初期分布では、各パーティションの分布は8-0-0です。

グループ内均衡後、各パーティションの分布は4-4-0となり、各均衡グループは均衡化されましたが、全体としては均衡化されていません。

グループ間均衡後、パーティションの分布は3-3-2となり、パーティション数が最も多いLS1、LS2からそれぞれ1つのパーティションをパーティション数が最も少ないLS3に転送することで、全体として均衡化されます。

Table Groupが存在する場合、各Table Groupは独立した均衡グループとなり、システムはTable Groupが要求する集約パーティションを結合し、1つのパーティションと見なします。その後、同様のグループ内均衡およびグループ間均衡の手法を用いてパーティション数の均衡化を行います。Table Groupが存在する場合、テナント内のすべてのパーティション数が完全に均等になるとは限りません。
Table Groupが存在する場合、均衡グループの分割方法は以下の通りです:
| テーブルタイプ | バランスグループ分割 | 分散方式 |
|---|---|---|
Table GroupのShardingプロパティがNONEのテーブル |
単独でバランスグループを形成 | Table Group内のすべてのパーティションは1つのログストリームに分散される |
Table GroupのShardingプロパティがPARTITIONまたはADAPTIVEのパーティションテーブル |
すべてのテーブルのパーティションは1つのバランスグループ | 最初のテーブルのパーティションはすべてのログストリームに均等に分散され、その後のテーブルの位置はすべて最初のテーブルに集約される |
Table GroupのShardingプロパティがADAPTIVEのコンポジット・パーティションテーブル |
すべてのテーブルのパーティション内のすべてのコンポジット・パーティションは1つのバランスグループ | 最初のテーブルの各パーティション内のすべてのコンポジット・パーティションはすべてのログストリームに均等に分散され、その後のテーブルの位置はすべて最初のテーブルに集約される |
例えば、上記の均衡化後に、さらにsharding = 'NONE'のTable Group tg1を追加します。このtg1にはnon_part_t5_in_tg1、non_part_t6_in_tg1、non_part_t7_in_tg1、non_part_t8_in_tg1、non_part_t9_in_tg1の5つの非パーティションテーブルが含まれます。tg1内のすべてのテーブルは必ず結合されるため、均衡化後のテーブルのパーティション分布は4-4-5となります。

パーティションディスクの均衡
パーティション数が均衡していることを前提に、ロードバランシングモジュールは可能な限りパーティションを交換することで、各ログストリーム間のディスク使用量の差がクラスタレベルの構成パラメータ balancer_tolerance_percentage で設定された割合を超えないようにします。単一パーティションのディスク使用量が過大になると、この均衡効果を得られない場合があります。
少量データのシナリオで頻繁に均衡が行われるのを避けるため、現行バージョンではパーティションディスクの均衡がトリガーされるしきい値は「50GB」です。個々のLSのディスク使用量がこのしきい値未満の場合、ディスクの均衡はトリガーされません。
パーティション均衡の判断方法
パーティション均衡はユーザーテーブルの主テーブルに対して行われ、クエリ時には table_type='USER TABLE' を指定する必要があります。パーティションディスクの均衡は主にビュー CDB_OB_TABLET_REPLICAS 内の data_size フィールドによって判断されます。
パーティション数の均衡のクエリ方法
obclient [test]> SELECT svr_ip,svr_port,ls_id,count(*) FROM oceanbase.CDB_OB_TABLE_LOCATIONS WHERE tenant_id=xxx AND role='leader' AND table_type='USER TABLE' GROUP BY svr_ip,svr_port,ls_id;パーティションディスクの均衡のクエリ方法
obclient [test]> SELECT a.svr_ip,a.svr_port,b.ls_id,sum(data_size)/1024/1024/1024 as total_data_size FROM oceanbase.CDB_OB_TABLET_REPLICAS a, oceanbase.CDB_OB_TABLE_LOCATIONS b WHERE a.tenant_id=b.tenant_id AND a.svr_ip=b.svr_ip AND a.svr_port=b.svr_port AND a.tablet_id=b.tablet_id AND b.role='leader' AND b.table_type='USER TABLE' AND a.tenant_id=xxxx GROUP BY svr_ip,svr_port,ls_id;