

OceanBaseデータベースのモニタリングは現在、主にOCPのモニタリング機能に依存しています。データベースクラスタ、テナント、ノードの各レベルでのパフォーマンス、容量、稼働状態などの指標を7×24時間監視収集し、グラフィカルに可視化することで、ユーザーがOceanBaseクラスタの利用状況を包括的に把握し、クラスタの異常を迅速に検出し、イベント発生時に即時警告を発することで、データベースの安定かつ効率的な運用を確保します。
モニタリング
OceanBaseデータベースのモニタリングは、処理チェーンの観点から以下のいくつかの部分に分けられます:
メトリックチェーン(通常のモニタリング指標):OBServerノードの状態監視、obproxyの状態監視、ホスト指標の監視。
OB SQLチェーン:OceanBaseデータベース関連のSQL、Plan指標を含みます。
OBリソースウォーターマークチェーン:OceanBaseクラスタ、テナントのリソース使用状況を収集します。
メトリックチェーン
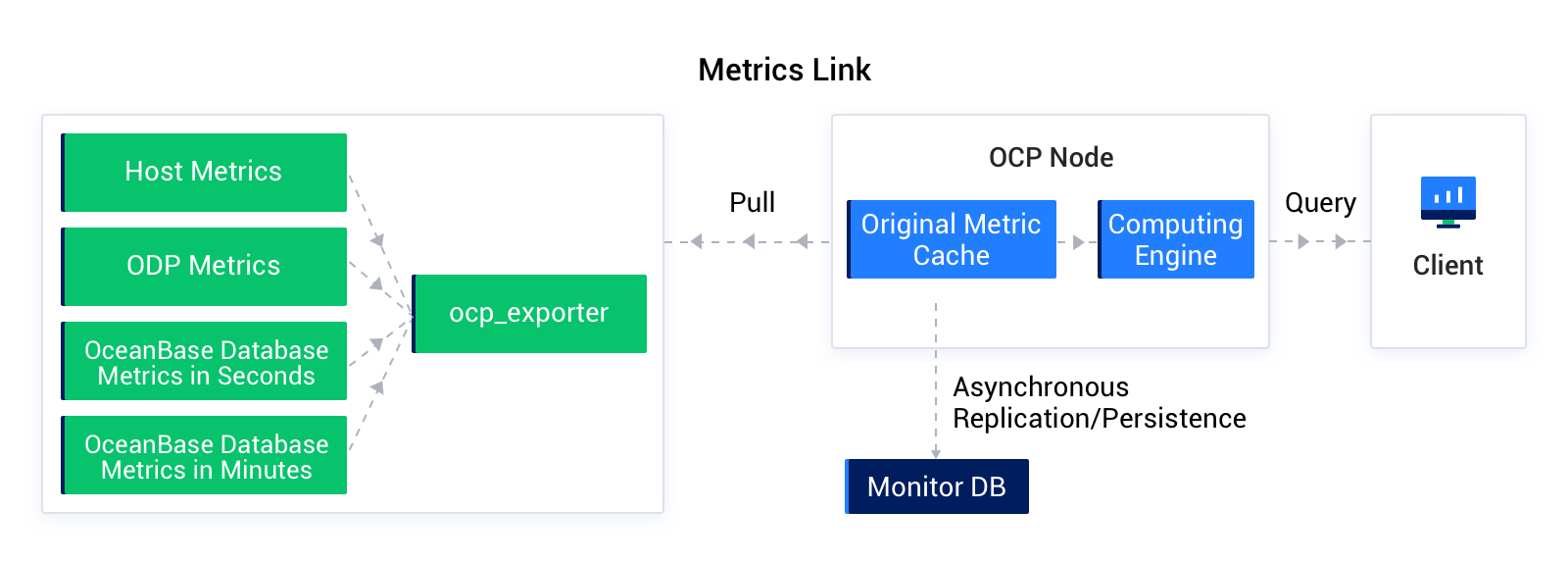
このチェーンは、以下の種類のメトリックを収集します:
ホストメトリック:ホストおよびホスト上にデプロイされた関連サービス(例えば、OBServerノード、obproxy)のCPU、ディスク、I/O、LOADなどの情報が含まれます。
obproxyメトリック:obproxyの関連リクエスト、セッション、トランザクションなどの情報。
OB秒(分)レベルのメトリック:対応するOBノードのリソース状態、QTPSなどのパフォーマンス監視情報。
メトリックチェーンは、OCP管理下のホスト上にデプロイされたOCP Agentのocp_exporterプログラムに依存して収集を行います。ocp_exporterは外部にRESTfulサービスを提供し、Prometheus仕様の監視メトリックを収集します。内部ではNodeExporter(ホスト監視)、OBProxyExporter(obproxy監視)、OBCollector(OceanBase監視)に依存してさまざまなメトリックを収集します。OCPは指定されたタイプの監視メトリックを収集した後、監視メトリックを集計・変換してモニタリングデータベース(MonitorDB)に保存します。監視計算エンジンは、監視式(Prometheusに基づく式)に基づいてモニタリングデータベースから監視データを照会し、計算を行った後、クライアントに返します。クライアントは返された計算済みの情報に基づいて監視グラフを表示します。
OB SQLチェーン

このチェーンは、各OBクラスタのSQLデータとSQL実行計画データを収集するために使用され、主に以下のビューからデータを収集します:
v$sql_audit:SQLの実行監査情報を記録します。
v$plan_cache_plan_explain:実行計画の各演算子の情報を記録します。
v$plan_cache_plan_stat:実行計画の監査情報を記録します。
SQLデータとSQL実行計画のデータ量が非常に大きいことを考慮し、パフォーマンスの向上とリソース消費の低減のため、このチェーンの収集プログラムであるobstat2は、C++で開発された高性能かつ軽量なプログラムです。収集頻度の設定に基づき、収集期間中にビューからSQLおよび実行計画情報を収集し、ローカルで集計計算を行った後、OCPのモニタリングデータベース(MonitorDB)に保存します。OCPのバックグラウンドタスクは定期的にモニタリングデータベースで集計計算を行い、最小粒度のSQL auditおよびSQL planデータを大きな時間粒度の結果に集計して保存します。Webページからのクエリ時に、選択された時間区間が短い場合は、元のレポートテーブルを直接照会し、時間粒度が大きい場合は集計テーブルを照会します。
OBリソースウォーターマーク
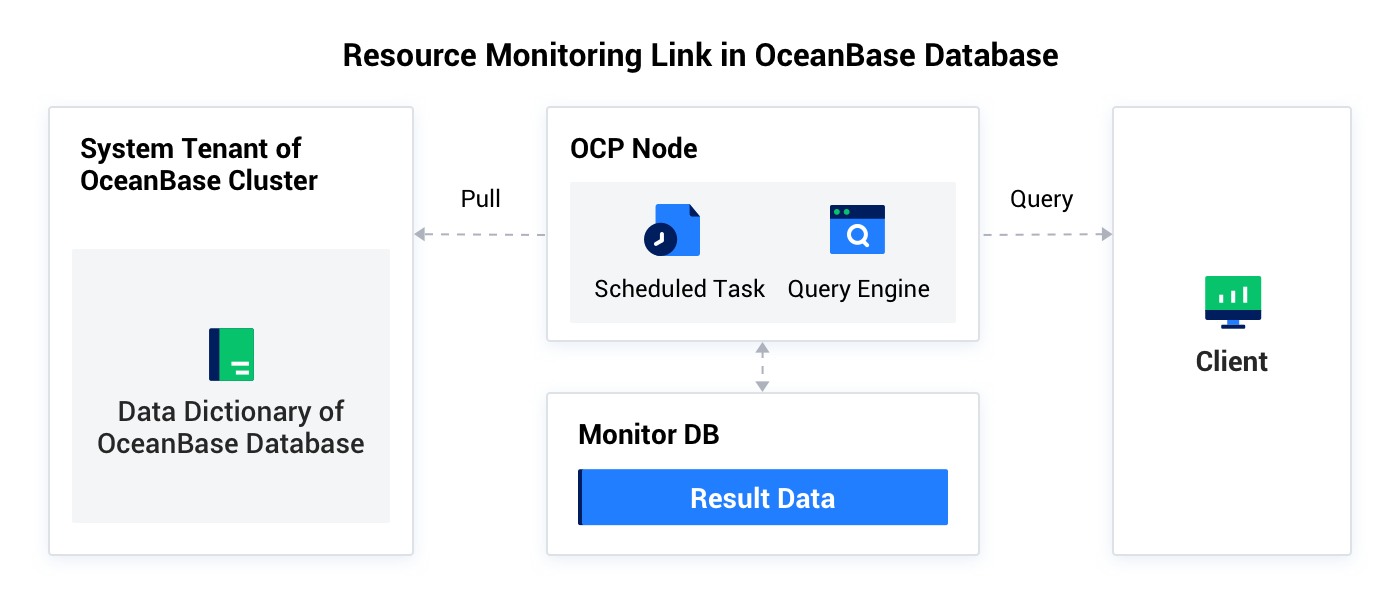
このルートは、OceanBaseクラスタのリソースウォーターマークを収集する役割を担っており、主に以下のデータソースからデータを収集します:
CPU情報:
- GV$OB_SERVERS:CPUの総コア数、割り当てられたコア数。
メモリ情報
- GV$OB_SERVERS:メモリの総サイズ、使用済みサイズ。
ディスク情報
- GV$OB_SERVERS:ディスクの総サイズ、使用済み情報。
システムイベント情報
- oceanbase.DBA_OB_ROOTSERVICE_EVENT_HISTORY:OceanBaseクラスタのシステムイベント情報。
OBリソースウォーターマークルートは、OCPのスケジュールタスクによってトリガーされ、各クラスタのsysテナントがクラスタ、テナント、データベース、テーブルなどの次元でOBServerノード上のCPU、Memory、Diskなどの利用率を収集し、データを監視データベースに保存します。クライアントがクエリリクエストを発行すると、クエリエンジンはクラスタ、テナント、データベース、テーブルなどの次元で統計を取り、統計後のデータをフロントエンドに返して表示します。
アラート
OceanBaseデータベースは主にOCPアラートを通じて、本番環境のホストやデータベースのリスク、障害に対する予警を実現します。データベースおよびそのホスト環境で障害が発生しようとしている場合、または実際に障害が発生した場合、組み込みのアラート項目が異常を検出し、アラートチャネルを通じてアラートをアラートサブスクライバーに送信します。アラート機能については、アラート項目の設定、アラート検出、アラート集計、アラートサブスクリプションの4つの側面から説明します。
アラート項目
OCPには約60個のアラート項目が組み込まれており、各アラート項目はアラート名、レベル、概要テンプレート、詳細テンプレートなどの基本的な情報と、アラート検出に関連するルール情報を説明しています。
アラートのリスク度合いに基づき、5つのアラートレベルに分類されています:停止、重大、警告、注意、リマインダー。アラートが発生すると、関連するテンプレート変数が生成され、これらの変数は概要テンプレートや詳細テンプレートで設定可能であり、必要なコンテキスト情報を表示します。アラート検出ルールは、監視式に基づく検出ルールであり、検出時間、検出周期、アラート回復周期、検出式の設定などが含まれます。
これらの組み込みアラート項目は、データベースリソース、データベースイベント、ホストリソース、OCPイベントなどの観点からアラートを説明しており、例えばデータベースのCPU、メモリ、MemStore、ディスク使用率などのデータベースリソースアラート、コンパクションタイムアウト、ハングしたトランザクションなどのデータベースイベントアラート、ホストネットワーク、ディスクアラート、およびOCPの監視API状態異常、metadb同期OBクラスタなどのアラートが含まれます。
アラート検出
アラート検出とは、組み込みのアラート項目を検出し、アラートをトリガーするプロセスであり、監視式に基づく検出とスケジュールタスクによる論理検出の2種類に分かれます。アラート検出後、アラートイベントが生成され、つまりアラートが発生します。ただし、このアラートイベントをユーザーに通知するかどうかは、その後のアラート集約ロジックに依存します。大量のアラートメッセージを避けるために、アラートに対して抑制操作を行う必要がある場合もあります。
監視式に基づくアラートでは、監視APIを通じて異なる次元から監視データを集約し、APIのクエリ結果にしきい値をマッチングさせることで、アラートトリガールールを満たすとアラートイベントが生成されます。

上図は、監視式に基づくアラート検出における状態遷移を示しています。durationはアラートの検出時間を指し、duration時間内に連続してアラートがトリガーされると、アラートイベントが生成されます。durationは、異常状態に対するフォールトトレランスシナリオでよく使用されます。偶発的な一度の異常は即座にアラートをトリガーすることを望まず、継続的な異常のみがアラートをトリガーします。
スケジュールタスクによる論理検出は、複雑なシナリオに対応し、スクリプト言語を使用して検出する必要があります。この検出方法は、アラートAPIを直接呼び出してアラートイベントを生成するものであり、OceanBaseログアラート、OMSアラートなどが該当します。外部システム(OCP以外のシステム)におけるイベントベースのアラートに適しています。
アラートの集約
アラートの集約とは、アラートメッセージを事前に設定されたルールに基づいて少数のアラートメッセージ(これを集約メッセージと呼ぶ)に統合し、アラートストームを防ぐことを指します。
以下はアラートの集約設定です。これはディープパーストマッチングルールであり、例えばOceanBaseログアラート(ob_log_alarm)の集約次元はalarm_type(アラート項目)+ob_error_code(ログエラーコード)+obregion(OceanBaseクラスタ名)です。
aggregate:
# root層はデフォルトの集約であり、アラートタイプ、オブジェクトに基づいて集約されます
match: {}
group_by:
- "alarm_type"
aggregate_wait_seconds: 10
aggregate_interval_seconds: 60
repeat_interval_seconds: 3600
aggregates:
# OBアラートについては、アラートタイプ、OBクラスタに基づいて集約されます
- match:
app: "OB"
group_by:
- "alarm_type"
- "obregion"
aggregate_wait_seconds: 10
aggregate_interval_seconds: 60
repeat_interval_seconds: 3600
aggregates:
# OBログアラートについては、アラートタイプ、ログエラーコード、OBクラスタに基づいて集約されます
- match:
alarm_type: "ob_log_alarm"
group_by:
- "alarm_type"
- "ob_error_code"
- "obregion"
aggregate_wait_seconds: 10
aggregate_interval_seconds: 60
repeat_interval_seconds: 3600
aggregate_wait_secondsは、最初のアラートが発生した際の待機時間であり、この時間内に同じ集約次元で発生したアラートは1つのアラートメッセージに集約されます。
aggregate_interval_secondsは、同じ集約次元の集約周期、すなわち新しい集約アラートメッセージが生成されるまでの時間です。
repeat_interval_secondsは、同一アラート(同一アラートID、アラートが回復するまでIDは増加しません)の送信周期であり、同一アラートは次のrepeat_interval_seconds周期になって初めて集約されます。
アラートサブスクリプション
アラートサブスクリプション機能は、アラートメッセージを異なるユーザーに送信するためのものです。
まず、アラート項目を異なるグループに分類し、サブスクライブ時にそのアラートグループを直接サブスクライブできます。現在のOCPでは、以下の6つのアラートグループに分類されています:
ocp:OCP関連のアラート項目。
dba:OceanBaseデータベース関連のアラート項目。
info:操作系(Infoレベル)のアラート項目。
oms:OMSアプリケーションのアラート項目。
backup:バックアップ・リカバリのアラート項目。
dev:運用保守関連のアラート項目。
クラスタやレベルごとにアラートをサブスクライブし、異なるアラートを異なるアラートチャネルに送信できます。アラートチャネルは、アラートをどのように送信するかを定義しており、現在はbash/pythonスクリプトによる送信やHTTP APIによる送信がサポートされています。また、チャネル上でレート制限ポリシーを設定することで、過剰なアラートの送信を防ぐことも可能です。