

概要
OceanBaseデータベースは、シェアードナッシング(Shared-Nothing、SN)モードと共有ストレージ(Shared-Storage、SS)モードの2種類のデプロイモードをサポートしています。
シェアードナッシングモード
シェアードナッシング(SN)モードでは、各ノード間が完全に対等であり、各ノードには独自のSQLエンジン、ストレージエンジン、トランザクションエンジンが備わっています。一般的なPCサーバーで構成されるクラスタ上で動作し、高い拡張性、高可用性、高性能、低コスト、そして主要なデータベースとの高い互換性という核心的な特徴を備えています。
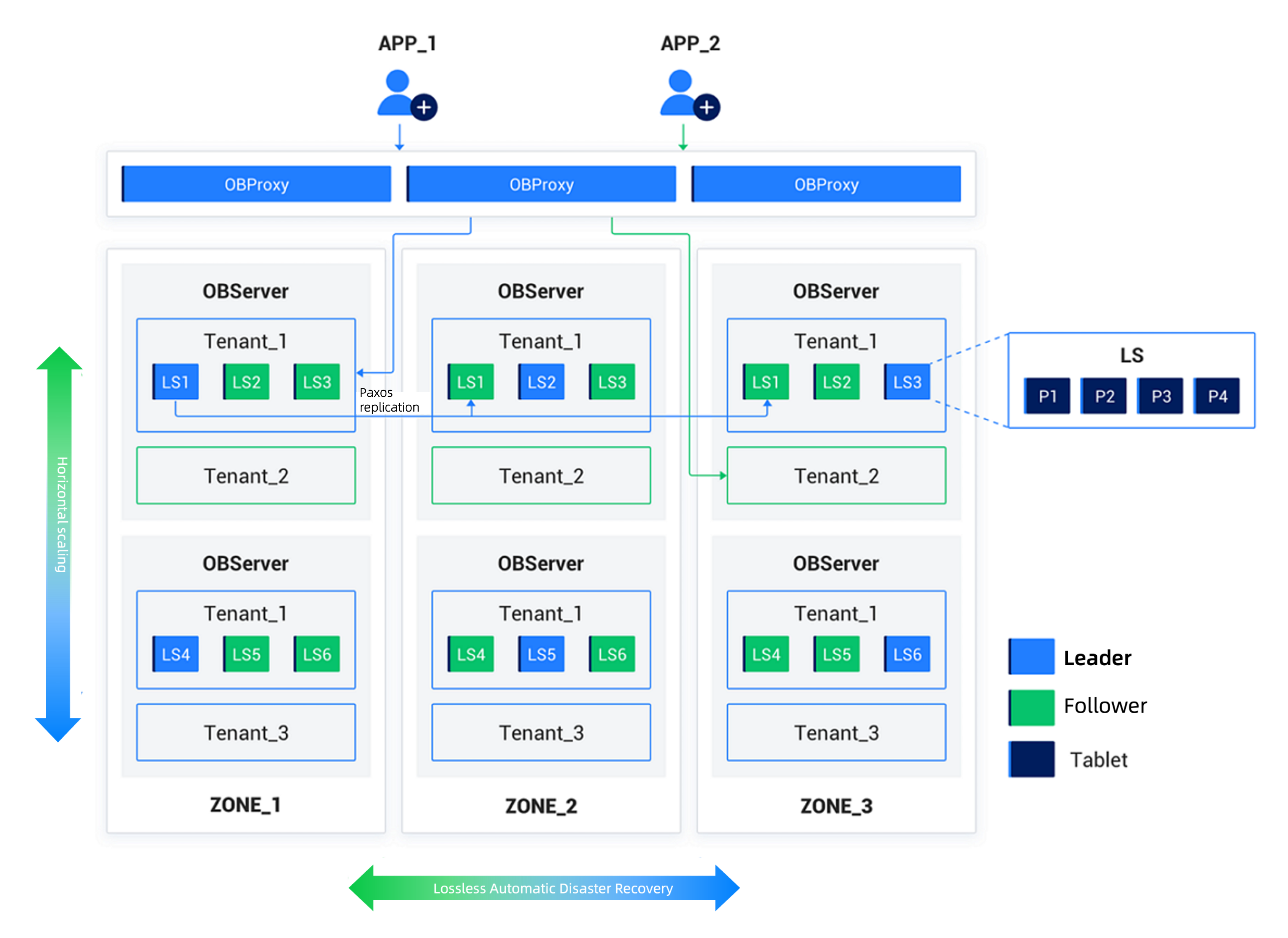
OceanBaseデータベースは汎用的なサーバーハードウェアを使用し、ローカルストレージに依存します。また、分散デプロイメントで使用する複数のサーバーも対等であり、特別なハードウェア要件はありません。OceanBaseデータベースの分散データ処理はShared Nothingアーキテクチャを採用しており、データベース内のSQL実行エンジンは分散実行機能を持っています。
OceanBaseデータベースのサーバー上では、observerという単一プロセスのプログラムがデータベースの実行インスタンスとして稼働し、ローカルのファイルを使用してデータとトランザクションRedoログを格納します。
OceanBaseクラスタのデプロイにはアベイラビリティゾーン(Zone)の設定が必要であり、各アベイラビリティゾーンは複数のサーバーで構成されます。アベイラビリティゾーンは論理的概念であり、クラスタ内で同様のハードウェア可用性を持つノードグループを表します。その意味合いはデプロイモードによって異なります。例えば、クラスタ全体が同一のデータセンター(IDC)内に配置されている場合、あるアベイラビリティゾーンのノードは同一のラックやスイッチに属することがあります。一方、クラスタが複数のデータセンターに分散されている場合、各アベイラビリティゾーンはそれぞれのデータセンターに対応することがあります。
ユーザーが保存したデータは、分散クラスタ内で複数のレプリカとして格納され、障害時の耐災性や読み取り負荷の分散に利用されます。同一テナント内のデータはあるアベイラビリティゾーン内に1つのレプリカしか存在せず、異なるアベイラビリティゾーンには同一データの複数のレプリカを格納できます。レプリカ間のデータ整合性はPaxosプロトコルによって保証されます。
OceanBaseデータベースは組み込みのマルチテナント機能を備えており、各テナントは独立したデータベースインスタンスと同等です。各テナントはテナントレベルで自身のデータ配布戦略やレプリカの種類・数を設定できます。また、各テナント間ではCPU、メモリ、I/Oなどのリソースが相互に隔離されています。
共有ストレージモード
共有ストレージ(SS)モードでは、システムはストレージと計算を分離したアーキテクチャを採用しています。各テナントは共有オブジェクトストレージ上にデータとログを1つずつ保存し、ノードのローカルストレージ上にはホットデータとログをキャッシュします。
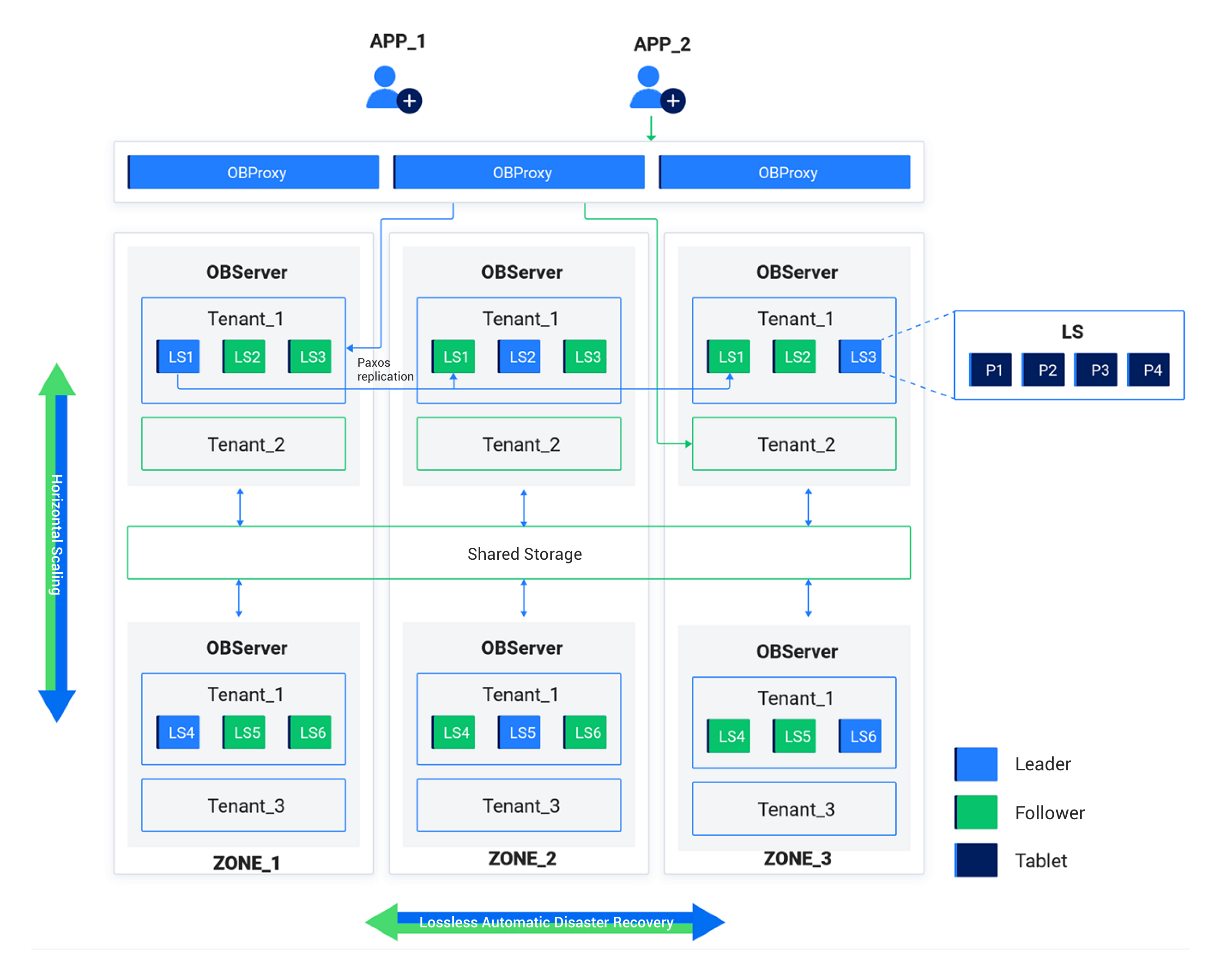
OceanBaseデータベースのデプロイアーキテクチャの詳細については、システムアーキテクチャを参照してください。
OceanBaseクラスタのデータベースインスタンス内部では、さまざまなコンポーネントが相互に協力して動作します。これらのコンポーネントは、下から順にマルチテナント層、ストレージ層、レプリケーション層、バランシング層、トランザクション層、SQL層、アクセス層から構成されています。
マルチテナント層
大規模な複数業務データベースのデプロイ管理を簡素化し、リソースコストを削減するために、OceanBaseデータベースは独自のマルチテナント機能を提供しています。1つのOceanBaseクラスタ内では、互いに隔離された複数のデータベース「インスタンス」を作成でき、これをテナントと呼びます。アプリケーションの観点から見ると、各テナントは独立したデータベースインスタンスと同等です。さらに、各テナントはMySQLまたはOracle互換モードを選択できます。アプリケーションがMySQLテナントに接続すると、そのテナント内でユーザーやデータベースを作成でき、これは独立したMySQLデータベースと同じ使い勝手です。同様に、アプリケーションがOracleテナントに接続すると、そのテナント内でスキーマやロールを作成・管理でき、これは独立したOracleデータベースと同じ使い勝手です。新しいクラスタが初期化されると、sysという特殊なテナントが自動的に作成されます。これをシステムテナントと呼びます。システムテナントにはクラスタのメタデータが保存されており、MySQL互換モードのテナントです。
テナントのリソースを隔離するために、各observerプロセス内には、異なるテナントに属する複数の仮想コンテナが存在します。これをリソースユニット(UNIT)と呼びます。リソースユニットにはCPUとメモリリソースが含まれます。各テナントの複数ノード上のリソースユニットが、1つのリソースプールを形成します。
ストレージ層
ストレージ層は、テーブルまたはパーティションを単位としてデータの保存とアクセスを提供します。各パーティションには、データを格納するためのTablet(シャード)が対応しており、ユーザー定義の非パーティションテーブルもまたTabletに対応します。
Tabletの内部は階層型ストレージ構造であり、合計4つの層が存在します:MemTable、L0層Mini SSTable、L1層Minor SSTable、そしてMajor SSTableです。DML操作による挿入、更新、削除などはまずMemTableに書き込まれ、MemTableが一定のサイズに達するとディスクにダンプされてL0層Mini SSTableとなります。L0層Mini SSTableの数がしきい値に達すると、複数のL0層Mini SSTableが1つのL1層Minor SSTableにメジャーコンパクションされます。毎日設定されたビジネスオフピーク時には、システムはすべてのMemTable、L0層Mini SSTable、およびL1層Minor SSTableを1つのMajor SSTableにコンパクションします。
各SSTableは、サイズが2MBの固定長マクロブロックで構成されており、各マクロブロック内部には複数の可変長マイクロブロックが含まれています。
Major SSTableのマイクロブロックは、コンパクションプロセスにおいてエンコーディング方式によってフォーマット変換され、マイクロブロック内のデータは列次元ごとにそれぞれインラインエンコーディングされます。エンコーディングルールには、辞書、ラン長、定数、または差分などが含まれます。各列の圧縮が完了した後、さらに複数の列に対して列間等値または部分文字列などのルールに基づくエンコーディングが行われます。エンコーディングによりデータは大幅に圧縮され、同時に抽出された列内特徴情報はその後のクエリ速度をさらに高速化します。
エンコーディング圧縮後、ユーザーが指定した汎用的な圧縮アルゴリズムを用いて無損失圧縮を行うことで、データ圧縮率をさらに向上させることができます。
レプリケーション層
レプリケーション層は、ログストリーム(LS、Log Stream)を使用して複数のレプリカ間で状態を同期します。各Tabletには特定のログストリームが対応し、各ログストリームには複数のTabletが対応します。DML操作によってTabletに書き込まれたデータによって生成されるRedoログは、ログストリームに永続化されます。ログストリームの複数のレプリカは異なるアベイラビリティゾーンに分散され、複数のレプリカ間ではコンセンサスアルゴリズムが維持されており、そのうちの1つのレプリカをリーダーレプリカとし、他のレプリカはすべてフォロワーレプリカとなります。TabletのDMLおよび強整合性クエリは、対応するログストリームのリーダーレプリカ上でのみ実行されます。
通常、各テナントは各マシン上に1つのログストリームのリーダーレプリカしか持たず、他の複数のログストリームのフォロワーレプリカを持つ可能性があります。テナントの総ログストリーム数は、Primary ZoneとLocalityの設定によって決まります。
ログストリームは、改良されたPaxosプロトコルを使用して、Redoログを本サーバーに永続化すると同時に、ネットワークを通じてログストリームのフォロワーレプリカに送信します。フォロワーレプリカはそれぞれの永続化を完了した後にリーダーレプリカに応答し、リーダーレプリカは多数派のレプリカがすべて永続化に成功したことを確認した後に、対応するRedoログの永続化が成功したことを確認します。フォロワーレプリカはRedoログの内容をリアルタイムで再生し、自身の状態がリーダーレプリカと一致するように保証します。
ログストリームのリーダーレプリカがリーダー(Leader)に選出されると、リース(Lease)を獲得します。正常に動作するリーダーレプリカは、リースの有効期間中、選出プロトコルを通じてリース期間を延長し続けます。リーダーレプリカは、リースが有効な限りプライマリの業務のみを実行し、リースメカニズムはデータベースの異常処理能力を保証します。
レプリケーション層は、サーバー障害に自動的に対応し、データベースサービスの継続的な可用性を保証します。サーバーの障害が発生し、過半数未満のフォロワーレプリカが存在する場合でも、すなわち残りの半数以上のレプリカが正常に動作している場合、データベースのサービスに影響はありません。リーダーレプリカが存在するサーバーに問題が発生した場合、そのリースは延長されず、リースが失効した後、他のフォロワーレプリカが選出プロトコルによって新しいプライマリを選出し、新しいリースを付与することで、その後データベースのサービスを再開できます。
バランシング層
新規テーブルや新規パーティションを作成する際、システムはバランシング原則に基づいて適切なログストリームを選択し、Tabletを作成します。テナントの属性が変更されたり、新たにマシンリソースが追加されたり、長時間の使用によりTabletが各マシン上で均等にならなくなった場合、バランシング層はログストリームの分割およびコンパクション操作を行い、このプロセスにおいてログストリームレプリカの移動を組み合わせることで、データとサービスを複数のサーバー間で再び均衡させます。
テナントが拡張操作を行い、より多くのサーバーリソースを獲得した場合、バランシング層はテナント内の既存のログストリームを分割し、適切な数のTabletを新しいログストリームに一緒に分割した後、新しいログストリームを新規のサーバーに移行することで、拡張後のリソースを最大限に活用します。テナントが縮小操作を行う場合、バランシング層は縮小対象のサーバー上のログストリームを他のサーバーに移行し、他のサーバー上の既存のログストリームとコンパクションすることで、マシンのリソース占有を削減します。
データベースを長期間使用するにつれて、ユーザーが継続的にテーブルを作成または削除し、さらに多くのデータを書き込むことで、たとえサーバーリソースの数が変化しなくても、元々の均衡状態が破壊される可能性があります。最も一般的なケースとして、ユーザーが一連のテーブルを削除した後、削除されたテーブルが元々特定のマシンに集中していた場合、削除後のこれらのマシン上のTablet数が減少し、他のマシン上のTabletをこれらの少ないマシンに均衡させる必要があります。バランシング層は定期的にバランシング計画を生成し、Tabletが多いサーバー上のログストリームから一時ログストリームを分割し、移動する必要があるTabletを含めます。一時ログストリームは移行先のサーバーに移行した後、移行先のサーバー上のログストリームとコンパクションすることで、均衡効果を達成します。
トランザクション層
トランザクション層は、単一のログストリームおよび複数のログストリームに対するDML操作のコミットの原子性を保証し、同時実行されるトランザクション間のマルチバージョン分離機能も保証します。
原子性
あるログストリーム上でのトランザクションの変更は、複数のTabletに関与する場合でも、ログストリームのWrite-Ahead Logによってトランザクションコミットの原子性を保証できます。トランザクションの変更が複数のログストリームに及ぶ場合、各ログストリームはそれぞれ独自のWrite-Ahead Logを生成して永続化します。トランザクション層は、最適化された2段階コミットプロトコルを通じて、トランザクションコミットの原子性を保証します。
複数のログストリームに関連するトランザクションがコミットを開始すると、トランザクションはそのうちの1つのログストリームを2段階コミットのコーディネーターとして選択します。コーディネーターは、トランザクションによって変更されたすべてのログストリームと通信し、Write-Ahead Logが永続化されているかどうかを判断します。すべてのログストリームが永続化を完了した後、トランザクションはコミット状態に入ります。その後、コーディネーターはすべてのログストリームに対して、そのトランザクションのCommitログを書き込み、トランザクションの最終的なコミット状態を示します。レプリカからの再生やデータベースの再起動時には、既にコミット済みのトランザクションはすべて、Commitログに基づいて各ログストリームのトランザクション状態を決定します。
ダウンタイムからの再起動シナリオでは、ダウンタイム前に完了していないトランザクションについて、Write-Ahead Logは書き込まれているものの、まだCommitログが書き込まれていない状況が発生します。各ログストリームのWrite-Ahead Logには、トランザクションのすべてのログストリームリストが含まれているため、この情報を用いてどのログストリームがコーディネーターであるかを再決定し、コーディネーターの状態を復旧させることができます。そして、再び2段階コミットプロトコルを進め、トランザクションが最終的なCommitまたはAbort状態に達するまで続けます。
分離性
GTS(Global Timestamp Service)サービスは、テナント内で連続的に増加するタイムスタンプを生成するサービスであり、複数のレプリカによって可用性を保証します。その基盤となる仕組みは、上記のレプリケーション層で説明されているログストリームレプリカ同期メカニズムと同一です。
各トランザクションがコミットされる際、GTSからタイムスタンプを取得してトランザクションのコミットバージョン番号とし、ログストリームのWrite-Ahead Logに永続化します。トランザクション内のすべての変更データは、このコミットバージョン番号でマークされます。
各ステートメントの開始時(Read Committed分離レベルの場合)または各トランザクションの開始時(Repeatable ReadおよびSerializable分離レベルの場合)、GTSからタイムスタンプを取得して、ステートメントまたはトランザクションの読み取りバージョン番号とします。データの読み取り時には、自身より大きいトランザクションバージョン番号をスキップし、現在の読み取りバージョン番号より小さいすべてのバージョン番号の中で最大のバージョン番号のデータを選択します。この方法により、読み取り操作に統一されたグローバルデータスナップショットが提供されます。
SQL層
SQL層は、ユーザーのSQLリクエストを1つまたは複数のTabletへのデータアクセスに変換します。
SQL層のコンポーネント
SQL層がリクエストの実行プロセスを処理する際の流れは、Parser、Resolver、Transformer、Optimizer、Code Generator、Executorです。その中で:
Parserは、構文解析を担当します。ユーザーのSQLを個々の「Token」に分割し、事前に設定された文法ルールに基づいてリクエスト全体を解析し、構文木(Syntax Tree)に変換します。
Resolverは、意味解析を担当します。データベースのメタ情報に基づき、SQLリクエスト内のTokenを対応するオブジェクト(例えば、データベース、テーブル、列、インデックスなど)に翻訳し、生成されるデータ構造をStatement Treeと呼びます。
Transformerは、論理的な書き換えを担当します。内部のルールやコストモデルに基づいて、SQLをそれと同等の他の形式に書き換え、その後のオプティマイザーによるさらなる最適化に供給します。
Transformerの動作方式は、元のStatement Treeに対して等価変換を行うことであり、変換結果も依然としてStatement Treeです。
Optimizer(オプティマイザー)は、SQLリクエストに対して最適な実行計画を生成します。SQLリクエストの意味、オブジェクトデータの特徴、オブジェクトの物理的配置など、多くの要素を総合的に考慮し、アクセスパスの選択、結合順序の選択、結合アルゴリズムの選択、分散計画の生成などの問題を解決し、最終的に実行計画を生成します。
Code Generator(コード生成器)は、実行計画を実行可能なコードに変換しますが、いかなる最適化も行いません。
Executor(実行エンジン)は、SQLの実行プロセスを開始します。
標準的なSQLプロセスに加えて、SQL層にはPlan Cache機能も備わっており、履歴の実行計画をメモリ内にキャッシュし、後続の実行ではこの計画を繰り返し実行できるため、重複したクエリの最適化プロセスを回避します。Fast-parserモジュールと組み合わせることで、構文解析のみを使用してテキスト文字列を直接パラメータ化し、パラメータ化後のテキストと定数パラメータを取得することで、SQLが直接Plan Cacheにヒットし、頻繁に実行されるSQLを高速化します。
複数の計画
SQL層の実行計画は、ローカル、リモート、分散の3種類に分かれます。ローカル実行計画は、同一サーバー上のデータのみにアクセスします。リモート実行計画は、ローカル以外のサーバー上のデータのみにアクセスします。分散計画は、複数のサーバー上のデータにアクセスし、実行計画は複数のサブ計画に分割されて複数のサーバー上で実行されます。
SQL層のパラレル実行機能は、実行計画を複数の部分に分解し、複数の実行スレッドによって実行することで、一定のスケジューリング手法を通じて実行計画の並列処理を実現します。パラレル実行は、サーバーのCPUおよびI/O処理能力を十分に活用し、単一クエリの応答時間を短縮できます。パラレルクエリ技術は、分散実行計画にもローカル実行計画にも適用できます。
アクセス層
OceanBaseデータベースプロキシODP(OceanBase Database Proxy、OBProxyとも呼ばれる)は、OceanBaseデータベースのアクセス層であり、ユーザーのリクエストを適切なOceanBaseデータベースインスタンスに転送して処理を行う役割を担います。
ODPは独立したプロセスインスタンスであり、OceanBaseデータベースインスタンスから独立してデプロイされます。ODPはネットワークポートを監視し、MySQLネットワークプロトコルに互換性があり、MySQLドライバーを使用するアプリケーションが直接OceanBaseデータベースに接続することをサポートします。
ODPは、OceanBaseクラスタのテナントおよびデータ分布情報を自動的に検出でき、プロキシする各SQL文について、その文がアクセスするデータを可能な限り特定し、その文を直接データが存在するサーバー上のOceanBaseデータベースインスタンスに転送します。
ODPには2種類のデプロイ方法があります。一つは、データベースにアクセスする必要があるすべてのアプリケーションサーバーにODPをデプロイする方法、もう一つは、OceanBaseデータベースノードが配置されているマシンにODPをデプロイする方法です。前者のデプロイ方法では、アプリケーションは同一サーバー上にデプロイされたODPに直接接続し、すべてのリクエストはODPによって適切なOceanBaseデータベースサーバーに送信されます。後者のデプロイ方法では、ネットワークロードバランシングサービスを使用して複数のODPを統合し、アプリケーションにサービスを提供するための単一のエントリアドレスとします。