

JOIN操作は、2つのデータソース(例えばテーブルやビュー)からの出力を結合し、1つのデータソースを返します。複数テーブルのJOINのタイプは、SQL文のWHERE(非ANSI)またはFROM ... JOIN(ANSI)句で定義されます。FROM句に複数のテーブルが存在する限り、データベースはジョインを実行します。
ジョイン条件は、テーブル間の関連関係を定義するために使用されます。このステートメントでジョイン条件が指定されていない場合、データベースはデカルト積ジョインを実行し、1つのテーブルの各行と別のテーブルの各行をすべてマッチングします。
接合ツリー
一つの接合ツリーは一般的に反転した樹形構造として表され、以下の図のように、T1 は左側に接合されるテーブルであり、ドライバーテーブルとも呼ばれ、通常はディメンショナルテーブルです。T2 は右側に接合されるテーブルであり、通常はファクトテーブルです。オプティマイザーは一般的に左から右へと接合されるテーブルを処理します。

接合されるデータソースは、別の接合結果から得られる場合もあります。左側のデータソースが別の接合結果から、右側のデータソースがベーステーブルから得られる場合、これを左深いツリーと呼び、ほとんどのビジネスプランは左深いツリーです。以下の図のように示されています。
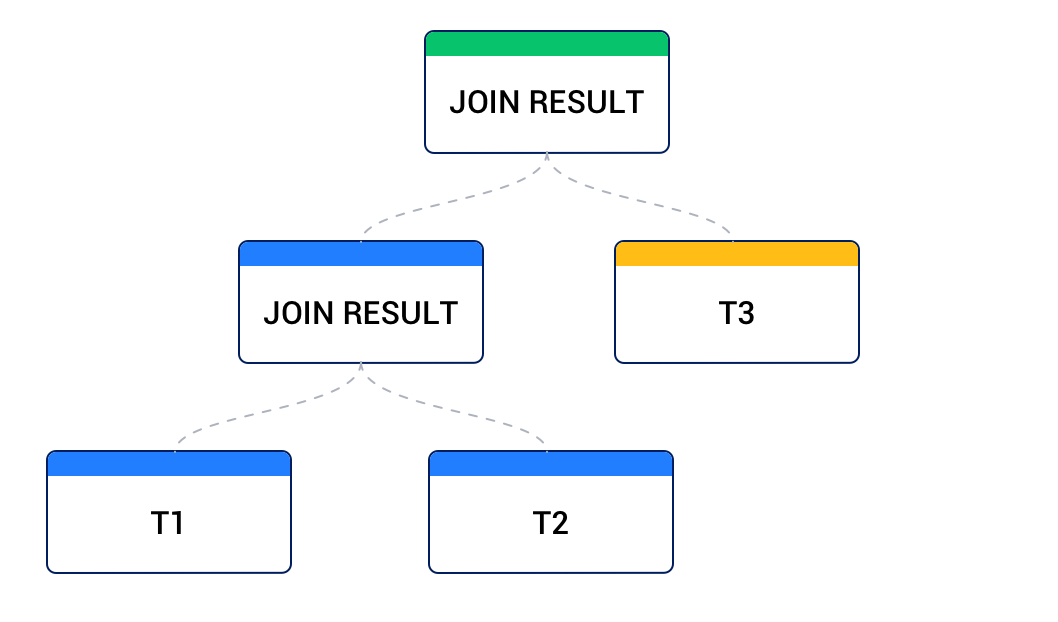
右側のデータソースが別の接合結果から、左側のデータソースがベーステーブルから得られる場合、これを右深いツリーと呼びます。以下の図のように示されています。
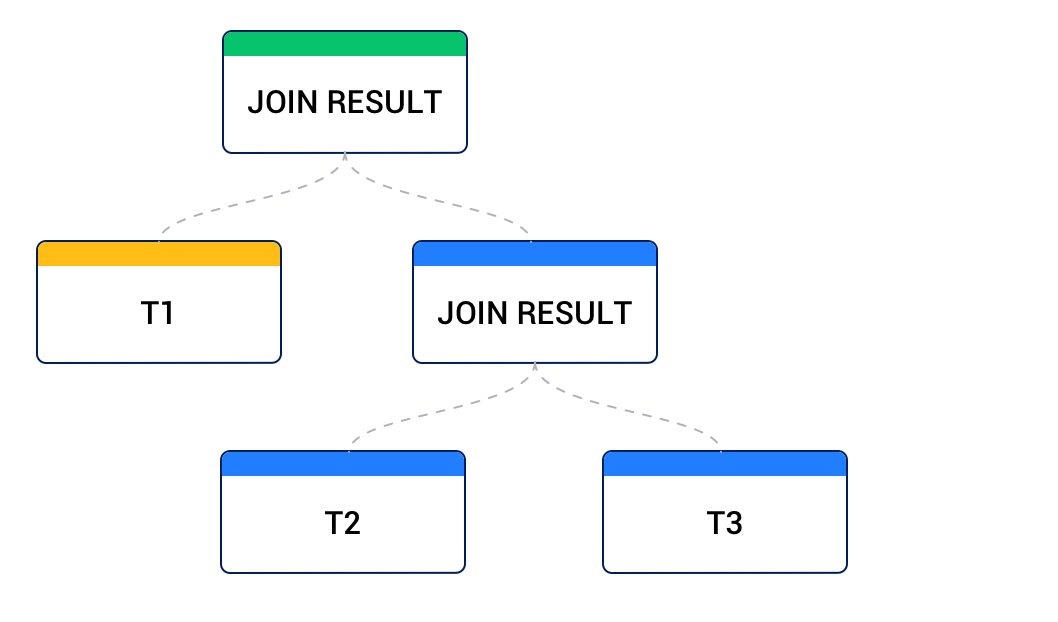
いずれかの接合ノードが他の接合ノードと異なる形状をしている場合、これを濃密接合ツリーと呼びます。以下の図のように示されています。

オプティマイザーはどのように接合を最適化するのか
FROM句に複数のテーブルが存在する場合、オプティマイザーは各テーブルペアに対する最も効率的な接合操作を決定しなければなりません。オプティマイザーは以下のいくつかの観点から意思決定を行います。
| 次元 | 説明 |
|---|---|
| ベーステーブルパス | 各ベーステーブルについて、オプティマイザーは主テーブルスキャンやインデックススキャンなど、最適なスキャン方法を選択する必要があります。 |
| 結合アルゴリズム | 2つのデータソースを結合するために、オプティマイザーは2つのデータソースをどのように関連付けるかを決定する必要があります。選択可能な結合アルゴリズムには、nested loop join、merge join、hash joinがあります。それぞれの結合アルゴリズムには効率的なシナリオがあり、オプティマイザーは統計情報に基づいて最適な結合アルゴリズムを選択する必要があります。 |
| 結合タイプ | オプティマイザーがサポートする結合タイプには、inner join、left join、right join、full join、left semi join、right semi join、left anti join、right anti join、connect by joinが含まれます。後者5種類の結合は、オプティマイザーが再構築した結合タイプであり、SQLではこれらの結合タイプを構文で指定することはできません。 |
| 結合順序 | 結合するテーブルの数が2つを超える場合、オプティマイザーは最適な結合順序を決定する必要があります。例えば、FROM T1, T2, T3の場合、考えられる結合順序には、T1 JOIN T2 JOIN T3、T1 JOIN T3 JOIN T2などがあります。オプティマイザーは、実行性能が最も優れた結合順序を可能な結合順序から決定する必要があります。 |
オプティマイザーはどのように接合計画を決定するのか
接合の順序と方法を決定する際、オプティマイザーの目標はSQL文全体の実行過程で実行する作業量を少なくするために、できるだけ早く接合データ量を削減することです。オプティマイザーは、考えられる接合順序、接合方法、利用可能なアクセスパスに基づいて一連の実行計画を生成し、それぞれの計画のコストを推定してコストが最も低い計画を選択します。
オプティマイザーは、I/O、ネットワーク、CPUのオーバーヘッドを計算することでクエリ計画のコストを推定します。異なるデータ配布方式ではネットワークオーバーヘッドが異なり、さらに異なる関数や式ではCPUオーバーヘッドが異なります。オプティマイザーはこれらの指標を用いてクエリ計画の総コストを決定します。これらの指標は、PARALLEL、ENABLE_ROWSETS、システム統計情報などの多くの初期化パラメータやセッション設定によってコンパイル時に影響を受ける可能性があります。
例えば、オプティマイザーは以下の方法でコストを見積もります:
- ネステッドループ結合のコストは、外部テーブルの各行と内部テーブルの各マッチング行をメモリに読み込むコストに依存します。オプティマイザーは内部テーブルの統計情報を使用してこれらのコストを推定します。
- マージ結合のコストは、主にすべてのソースをメモリに読み込んでソートするコストに依存します。
- ハッシュ結合のコストは、主に接合の入力端の一方にハッシュテーブルを構築し、もう一方の端の行を使用してそれを検出するコストに依存します。