

基礎理論
パフォーマンスチューニング
パフォーマンスチューニングとは、ソフトウェアおよびハードウェアの能力を最大限に引き出し、実際の環境においてシステムの最適なパフォーマンスを実現することで、ソフトウェアとハードウェアのコストパフォーマンスを向上させ、顧客のコストを削減することを目的としています。以下のように、perf stat コマンドを使用して一定期間のハードウェア性能指標データを収集できます。
Performance counter stats for process id '3260':
182250.331423 task-clock (msec) # 18.221 CPUs utilized
3,259,379 context-switches # 0.018 M/sec
1,628,966 cpu-migrations # 0.009 M/sec
51 page-faults # 0.000 K/sec
442,995,845,816 cycles # 2.431 GHz
226,812,458,841 instructions # 0.51 insn per cycle
45,556,284,037 branches # 249.965 M/sec
662,510,643 branch-misses # 1.45% of all branches
10.002402740 seconds time elapsed
パフォーマンスチューニングの手順
パフォーマンスチューニングの主な手順は以下の通りです:
最適化目標を決定します。
スループット:スループットは主にCPU情報とコンポーネントのボトルネックに焦点を当てています。現在、ODPとOceanBaseデータベースはどちらもCPUをフル稼働させることができます。
レイテンシー:アクセスチェーン上のコンポーネント数と各区間の所要時間に注意が必要です。また、ネットワークレイテンシーも重要な要素です。
実績:全体を考慮すると、ビジネス側に近いほど最適化効果が顕著になる可能性があります。
ストレステストと情報収集:ターゲットデータを収集するだけでなく、各コンポーネントのCPU消費量やネットワークレイテンシーなどのデータも収集する必要があります。
ストレスを分析してパフォーマンスのボトルネックを特定します:上記で収集したデータをもとに、まずボトルネックを引き起こすコンポーネントを特定し、その後さらに詳細な分析を進めます。
最適化を実施します:現在の最適化は主にパラメータ調整やデプロイメントの調整などですが、特殊な場合はコードの修正やバージョンアップデートが必要になる場合もあります。
最適化効果を確認します:主にレイテンシーとスループットが顧客の要件またはテスト結果を満たしているかどうかを確認します。
ODPの性能
関連データのまとめ
パフォーマンス関連データのまとめは以下の通りです:
qps = 並行数 × (1000ms / RT)。
RT = 1000ms / (qps / 並行数)。
同じデータセンター内でのネットワーク遅延は基本的に100us以内です。
OceanBaseデータベースの転送効率はODPの50%未満です。
ODPのパフォーマンスデータのまとめ:
マシン全体の専有パフォーマンスは2万~3万5千の間であり、CPU型番などの影響を受けます。負荷が小さい場合、HTを使用しない方がパフォーマンスは高くなります。
OceanBaseデータベースとの混合デプロイでは、ODPへのリソース競合が発生し、ODPに対するロードバランシングパフォーマンスが向上します。
他のデプロイ方法と比較して、クライアント側にデプロイすることが最もパフォーマンスが良い方法です。
ARMプラットフォームをサポートしていますが、ARMプラットフォームのパフォーマンスはx86系より劣ります。
問題処理
ODPの主な問題はQPSとRTです:
QPS:一般的にはスケールアップで解決できます。スケールアップが不可能な場合は、単一マシンのパフォーマンス向上を検討します。CPUが十分でもQPSが上がらない場合は、具体的な問題に応じて分析する必要があります。
RT:Slow Queryログを確認することでODPの実行時間を把握できます。ODP自体の実行時間はusレベルであり、全体的なアーキテクチャの方がRTに与える影響が大きいです。
問題を処理する際には、実装の目的を明確に区別する必要があります。例えば、ODPがボトルネックとなり(CPUがフルになった場合)、OMSによるデータ移行が遅くなるため、ODPインスタンス数を増やすことでより迅速に問題を解決できます。
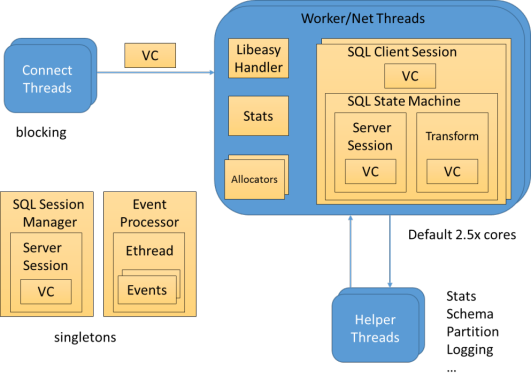
スレッドモデル
topコマンドの-Hオプションを使用するとスレッド状況を確認できます。ODPのワーカースレッドはobproxyおよびスレッド名がET NETで始まるスレッドです。ODPはスレッド間での共有をほぼ排除しているため、各スレッドは独立して動作可能であり、各リクエストは均等に各ワーカースレッドに分散されます。
パラメータ調整
パフォーマンスチューニングに関わる主なパラメータは以下の通りです:
alter proxyconfig set enable_compression_protocol=false; --圧縮を無効にし、CPU使用率を低下させる
alter proxyconfig set proxy_mem_limited='16G'; --OOMを防ぐため、実際の環境に応じて動的に調整可能
alter proxyconfig set enable_prometheus=false;
alter proxyconfig set enable_metadb_used=false;
alter proxyconfig set enable_standby=false;
alter proxyconfig set enable_strict_stat_time=false;
alter proxyconfig set use_local_dbconfig=true; --3.x系でのみ利用可能
alter proxyconfig set work_thread_num= xxx; --xxxは実際のコア数以下に設定する
ルーティングの正確性
OceanBaseデータベースの転送効率はODPほど高くないため、ODPのルーティングの正確性は重要です。可能な限りlocal計画を実現することが望ましいです。非コアシナリオでは、これほど厳密に要求する必要はありません。現在、ODPは通常のテーブル、パーティションテーブル、LDC、Primary Zoneなどのルーティングをサポートしています。詳細については、データルーティングの章を参照してください。
プロセス性能分析
スレッドモデルデータ
一定の10万qpsのデータにおけるCPU消費量は以下の表のとおりです:
| スレッド数 | qps | CPU | IPC | コンテキストスイッチ |
|---|---|---|---|---|
| 4 | 100021.12 | 3.979 | 0.49 | 19746 コンテキストスイッチ # 0.165 K/秒 4043 cpu-migrations # 0.034 K/秒 |
| 8 | 99985.25 | 5.816 | 0.36 | 1294736 コンテキストスイッチ # 0.007 M/秒 (100.00%) 19267 cpu-migrations # 0.110 K/秒 (100.00%) |
| 12 | 99943.38 | 6.763 | 0.33 | 2239606 コンテキストスイッチ # 0.011 M/秒 (100.00%) 80049 cpu-migrations # 0.395 K/秒 (100.00%) |
| 16 | 99912.43 | 7.345 | 0.31 | 2885634 コンテキストスイッチ # 0.013 M/秒 (100.00%) 172082 cpu-migrations # 0.781 K/秒 (100.00%) |
| 20 | 99959.15 | 8.102 | 0.33 | 3256951 コンテキストスイッチ # 0.013 M/秒 (100.00%) 296914 cpu-migrations # 0.001 M/秒 (99.99%) |
| 24 | 100032.52 | 8.156 | 0.29 | 3673410 コンテキストスイッチ # 0.015 M/秒 (100.00%) 471850 cpu-migrations # 0.002 M/秒 (100.00%) |
ツールによる確認
ツールによる確認の主な方法は以下のとおりです:
topコマンド
topコマンドを使用してODPのCPU使用率をリアルタイムで確認します。CPU使用率がOceanBaseデータベースを上回る場合、パフォーマンスが異常である可能性があり、さらなる分析が必要です。
top -Hを使用してスレッドのCPU消費量を確認します。ODPのスレッド消費は非常に均等です。
perfコマンド
perf topを使用してホットスポット関数を確認します。現在、ODPではどの関数も5%を超えていません。
perf statを使用してハードウェア指標を確認します。これは、異なるCPUを分析する際に役立ちます。
ログ出力
ログはパフォーマンスに大きな損失を与えるため、ODPのログ生成速度を確認することができます。1~2秒ごとにログが生成される場合、パフォーマンスへの影響は非常に大きいです。