

本記事では、OceanBaseでサポートされているベクトル関数とその使用上の注意点を紹介します。
使用上の注意点
- 次元の異なるベクトルデータに対して、以下の演算は許可されていません。
different vector dimensions %d and %dエラーが発生します。 - 結果が浮動小数点数の範囲を超えた場合、
value out of range : overflow / underflowエラーが発生します。 - ベクトルインデックス検索は、本記事にある
L2_distance、Cosine_distance、Inner_product、Negative_inner_productの距離関数、およびinner_product_similarity、cosine_similarity、l2_similarityの類似度関数を呼び出すことができます。
注意
V4.3.5 BP5バージョン以降、類似度関数がサポートされています。
ベクトルインデックスのメモリの設定
OceanBaseのベクトル検索では、ob_vector_memory_limit_percentage設定を使ってベクトルインデックスのメモリを設定できます。
V4.3.5 BP3以前では、
ob_vector_memory_limit_percentageを手動で設定してベクトル機能を有効にする必要があります。最適なクエリパフォーマンスを得るために、値は30に設定することをお勧めします。デフォルト値のままだと、ベクトルインデックスにメモリが割り当てられず、インデックス作成時にエラーが発生します。設定例は以下の通りです:ALTER SYSTEM SET ob_vector_memory_limit_percentage = 30;V4.3.5 BP3以降では、ベクトル検索機能がデフォルトで有効になっています。デフォルト値の
0は適応モードを意味し、システムがテナント内のベクトルインデックスデータのメモリ使用率を自動的に調整します。手動で調整する必要はありません:- テナントの実際のメモリが8GB以下の場合、この値は自動的に
40に設定されます。 - テナントの実際のメモリが8GBを超える場合、この値は自動的に
50に設定されます。
- テナントの実際のメモリが8GB以下の場合、この値は自動的に
距離関数
距離関数は、2つのベクトルの間の距離を計算するために使用され、具体的な計算方法は、距離アルゴリズムによって異なります。
L2_distance
ユークリッド距離は比較対象のベクトル座標間の距離を表しており、基本的には2つのベクトル間の直線距離です。ベクトルの座標にピタゴラスの定理を適用して計算します:
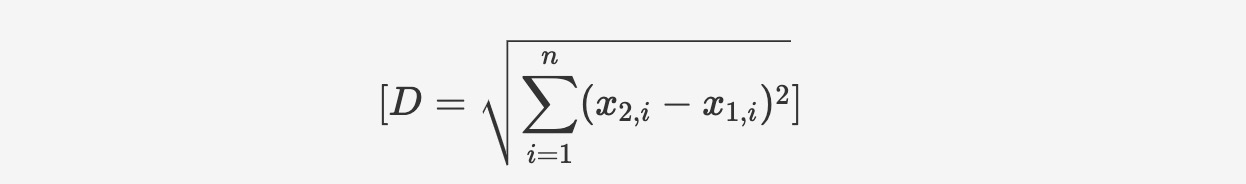
関数構文は以下のとおりです:
l2_distance(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。これには、1次元配列(例:
[1,2,3,..])と文字列(例:'[1,2,3]')が含まれます。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素にNULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)で表される距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t1(c1 vector(3));
INSERT INTO t1 VALUES('[1,2,3]');
SELECT l2_distance(c1, [1,2,3]), l2_distance([1,2,3],[1,1,1]), l2_distance('[1,1,1]','[1,2,3]') FROM t1;
結果は次のとおりです:
+--------------------------+------------------------------+----------------------------------+
| l2_distance(c1, [1,2,3]) | l2_distance([1,2,3],[1,1,1]) | l2_distance('[1,1,1]','[1,2,3]') |
+--------------------------+------------------------------+----------------------------------+
| 0 | 2.23606797749979 | 2.23606797749979 |
+--------------------------+------------------------------+----------------------------------+
1 row in set
L1_distance
マンハッタン距離は、標準的な座標系において2点間の絶対軸距離の合計を計算するために使用されます。計算式は次のとおりです:
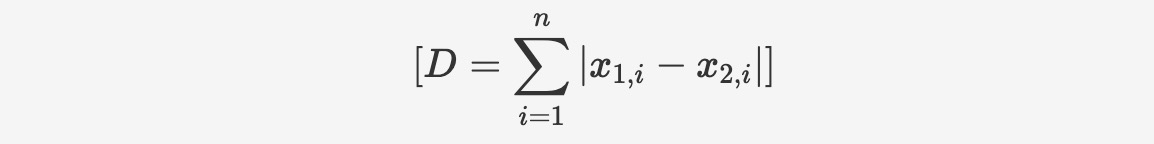
関数構文は以下のとおりです:
l1_distance(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。これには、1次元配列(例:
[1,2,3,..])と文字列(例:'[1,2,3]')が含まれます。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素にNULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)で表される距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t2(c1 vector(3));
INSERT INTO t2 VALUES('[1,2,3]');
INSERT INTO t2 VALUES('[1,1,1]');
SELECT l1_distance(c1, [1,2,3]) FROM t2;
結果は次のとおりです:
+--------------------------+
| l1_distance(c1, [1,2,3]) |
+--------------------------+
| 0 |
| 3 |
+--------------------------+
2 rows in set
Cosine_distance
コサイン類似度(cosine similarity)は2つのベクトルの角度の差異を測るもので、2つのベクトルの方向上の類似度を示し、ベクトルの長さ(サイズ)とは無関係となります。コサイン類似度の値の範囲は [-1, 1] であり、1 はベクトルが完全に同じ方向であることを示し、0 は直交を示し、-1 は完全に反対の方向を示します。
コサイン類似度の計算方法は次のとおりです:
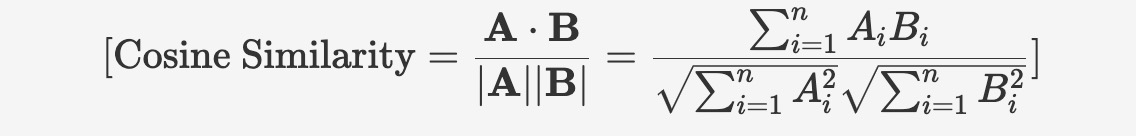
コサイン類似度の度量が1に近づくとより類似していることを示すことから、コサイン距離(またはコサイン非類似度)をベクトル間の距離の測定方式として使用することがあります。コサイン距離は1からコサイン類似度を引くことで計算することができます。
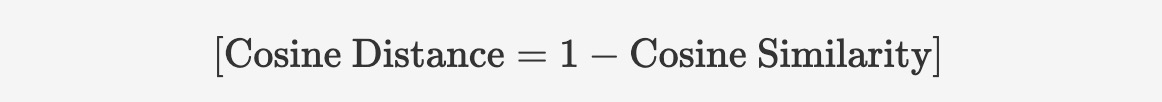
コサイン距離の値の範囲は [0, 2] であり、0 は完全に同じ方向(距離なし)、2 は完全に反対方向を表します。
関数構文は以下のとおりです:
cosine_distance(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。これには、1次元配列(例:
[1,2,3,..])と文字列(例:'[1,2,3]')が含まれます。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素にNULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)で表される距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t3(c1 vector(3));
INSERT INTO t3 VALUES('[1,2,3]');
INSERT INTO t3 VALUES('[1,2,1]');
SELECT cosine_distance(c1, [1,2,3]) FROM t3;
+------------------------------+
| cosine_distance(c1, [1,2,3]) |
+------------------------------+
| 0 |
| 0.12712843905603044 |
+------------------------------+
2 rows in set
Inner_product
内積は、点乗積またはスカラー積とも呼ばれ、2つのベクトル間の積を表します。幾何学的に言えば、内積は2つのベクトルの方向と大きさの関係を表します。内積の計算方法は以下のとおりです:
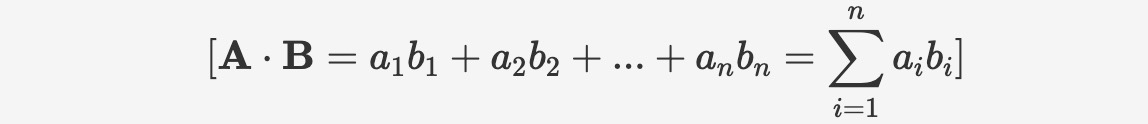
構文については以下のとおりです:
inner_product(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。これには、1次元配列(例:
[1,2,3,..])と文字列(例:'[1,2,3]')が含まれます。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素にNULLを含めることはできません。
この関数で疎ベクトルを使用する場合、パラメータのどちらか一方を疎ベクトル形式の文字列(例:c2,'{1:2.4}')として指定できますが、両方の引数を文字列にすることはサポートしていません。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)で表される距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
密ベクトルの例は次のとおりです:
CREATE TABLE t4(c1 vector(3));
INSERT INTO t4 VALUES('[1,2,3]');
INSERT INTO t4 VALUES('[1,2,1]');
SELECT inner_product(c1, [1,2,3]) FROM t4;
結果は次のとおりです:
+----------------------------+
| inner_product(c1, [1,2,3]) |
+----------------------------+
| 14 |
| 8 |
+----------------------------+
2 rows in set
疎ベクトルの例は次のとおりです:
CREATE TABLE t4(c1 INT, c2 SPARSEVECTOR, c3 SPARSEVECTOR);
INSERT INTO t4 VALUES(1, '{1:1.1, 2:2.2}', '{1:2.4}');
INSERT INTO t4 VALUES(2, '{1:1.5, 3:3.6}', '{4:4.5}'));
SELECT inner_product(c2,c3) FROM t4;
結果は次のとおりです:
+----------------------+
| inner_product(c2,c3) |
+----------------------+
| 2.640000104904175 |
| 0 |
+----------------------+
2 rows in set
Negative_inner_product
Negative_inner_productは、2つのベクトルの負の内積を計算するために使用され、計算方法は次のとおりです:
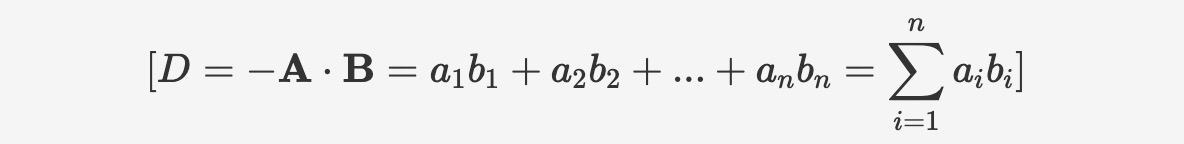
構文については以下のとおりです:
negative_inner_product(vector v1, vector v2)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。これには、1次元配列(例:
[1,2,3,..])と文字列(例:'[1,2,3]')が含まれます。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素にNULLを含めることはできません。
この関数で疎ベクトルを使用する場合、パラメータのどちらか一方を疎ベクトル形式の文字列(例:
c2,'{1:2.4}')で指定することはできますが、両方のパラメータを文字列にすることはサポートされていません。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)で表される距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
密ベクトルの例は次のとおりです:
CREATE TABLE t4(c1 vector(3));
INSERT INTO t4 VALUES('[1,2,3]');
INSERT INTO t4 VALUES('[1,2,1]');
SELECT negative_inner_product(c1, [1,2,3]) FROM t4;
結果は次のとおりです:
+-------------------------------------+
| negative_inner_product(c1, [1,2,3]) |
+-------------------------------------+
| -14 |
| -8 |
| -14 |
| -8 |
+-------------------------------------+
4 rows in set
疎ベクトルの例は次のとおりです:
CREATE TABLE t5(c1 INT, c2 SPARSEVECTOR, c3 SPARSEVECTOR);
INSERT INTO t5 VALUES(1, '{1:1.1, 2:2.2}', '{1:2.4}');
INSERT INTO t5 VALUES(2, '{1:1.5, 3:3.6}', '{4:4.5}'));
SELECT negative_inner_product(c2,c3) FROM t5;
結果は次のとおりです:
+-------------------------------+
| negative_inner_product(c2,c3) |
+-------------------------------+
| -2.640000104904175 |
| 0 |
+-------------------------------+
2 rows in set
Vector_distance
vector_distanceは、2つのベクトル間の距離を計算するために使用され、指定されたパラメータによって異なる距離アルゴリズムを選択します。
構文については以下のとおりです:
vector_distance(vector v1, vector v2 [, string metric])
vector v1/v2 パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。これには、1次元配列(例:
[1,2,3,..])と文字列(例:'[1,2,3]')が含まれます。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素にNULLを含めることはできません。
metric パラメータは、距離アルゴリズムを指定するために使用されます。オプションです。
指定されていない場合、デフォルトのアルゴリズムは
euclideanです。指定されている場合、選択可能な値は以下に限られます。
euclidean。ユークリッド距離を示し、L2_distanceと同じ意味です。manhattan。マンハッタン距離を示し、L1_distanceと同じ意味です。cosine。余弦距離を表し、Cosine_distanceと同じ意味です。dot。内積を表し、Inner_productと同じ意味です。
戻り値の説明は以下のとおりです:
戻り値は
distance(double)で表される距離値です。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t5(c1 vector(3));
INSERT INTO t5 VALUES('[1,2,3]');
INSERT INTO t5 VALUES('[1,2,1]');
SELECT vector_distance(c1, [1,2,3], euclidean) FROM t5;
結果は次のとおりです:
+-----------------------------------------+
| vector_distance(c1, [1,2,3], euclidean) |
+-----------------------------------------+
| 0 |
| 2 |
+-----------------------------------------+
2 rows in set
類似度関数
類似度関数は、2つのベクトルの類似性の度合いを測定するために使用され、値が大きいほどベクトル同士が類似していることを示します。これは距離関数とは逆の概念であり、類似度が高いほど距離は小さくなります。ベクトル検索では、類似度のしきい値を設定することで、条件を満たす結果をフィルタリングできます。
inner_product_similarity
inner_product_similarity は、2つのベクトル間の内積類似度を計算するために使用されます。関数の戻り値の計算方法は inner_product と同じですが、戻り値は距離ではなく類似度を表します。inner_product との換算式は次のとおりです:inner_product_similarity(v1, v2) = (1 + inner_product(v1, v2) / (vector_norm(v1) * vector_norm(v2))) / 2。vector_norm 関数は、ベクトルのユークリッドノルム(大きさ)を計算するために使用され、ベクトルと原点の間のユークリッド距離を表します。ベクトル v = [v1, v2, v3, ..., vn] の場合、そのノルム計算式は vector_norm(v) = √(v1² + v2² + v3² + ... + vn²) です。
構文は以下のとおりです。
inner_product_similarity(vector v1, vector v2)
パラメータの説明は以下のとおりです。
ベクトル型以外に、パラメータはベクトル型にキャスト可能な任意の型を受け入れます。これには、単一レベルの配列型(例:
[1,2,3,..])や文字列型(例:'[1,2,3]')が含まれます。2つのパラメータの次元は同じである必要があります。
単一レベルの配列型パラメータが存在する場合、その要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです。
戻り値は
similarity(double)型の類似度値であり、値が大きいほど類似していることを示します。任意のパラメータが
NULLの場合、NULLを返します。
例は以下のとおりです。
CREATE TABLE t12(c1 vector(3));
INSERT INTO t12 VALUES('[1,2,3]');
INSERT INTO t12 VALUES('[1,2,1]');
SELECT inner_product_similarity(c1, [1,2,3]) FROM t12;
返される結果は以下のとおりです。
+---------------------------------------+
| inner_product_similarity(c1, [1,2,3]) |
+---------------------------------------+
| 0.9999999552965164 |
| 0.9364357516169548 |
+---------------------------------------+
2 rows in set
または、より単純な例:
SELECT inner_product_similarity([1,0,0], [0,1,0]);
返される結果は以下のとおりです。
```shell
+--------------------------------------------+
| inner_product_similarity([1,0,0], [0,1,0]) |
+--------------------------------------------+
| 0.5 |
+--------------------------------------------+
1 row in set
cosine_similarity
cosine_similarity は、2つのベクトル間のコサイン類似度を計算するために使用されます。これはベクトルの長さ(大きさ)に関係なく、方向の類似性を反映します。計算式は cosine_similarity(v1, v2) = 1 - (cosine_distance(v1, v2) / 2) です。
構文は以下のとおりです。
cosine_similarity(vector v1, vector v2)
パラメータの説明は以下のとおりです。
ベクトル型以外に、パラメータはベクトル型にキャスト可能な任意の型を受け入れます。これには、単一レベルの配列型(例:
[1,2,3,..])や文字列型(例:'[1,2,3]')が含まれます。2つのパラメータの次元は同じである必要があります。
単一レベルの配列型パラメータが存在する場合、その要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです。
戻り値は
similarity(double)型の類似度値であり、範囲は[-1, 1]です。ここで1はベクトルが完全に同じ方向であることを、0は直交していることを、-1は完全に反対方向であることを示します。値が大きいほど類似していることを示します。任意のパラメータが
NULLの場合、NULLを返します。
例は以下のとおりです。
CREATE TABLE t13(c1 vector(3));
INSERT INTO t13 VALUES('[1,2,3]');
INSERT INTO t13 VALUES('[1,2,1]');
SELECT cosine_similarity(c1, [1,2,3]) FROM t13;
返される結果は以下のとおりです。
+--------------------------------+
| cosine_similarity(c1, [1,2,3]) |
+--------------------------------+
| 0.9999999552965164 |
| 0.9364357516169548 |
+--------------------------------+
2 rows in set
または、より単純な例:
SELECT cosine_similarity([1,0,0], [0,1,0]);
返される結果は以下のとおりです。
+-------------------------------------+
| cosine_similarity([1,0,0], [0,1,0]) |
+-------------------------------------+
| 0.5 |
+-------------------------------------+
1 row in set
l2_similarity
l2_similarity は、2つのベクトル間の L2 類似度を計算するために使用されます。L2 類似度はユークリッド距離に基づいていますが、戻り値は距離ではなく類似度を表します。類似度の値が大きいほど、2つのベクトルは類似していることを示します。l2_squared との換算式は l2_similarity(v1, v2) = 1 / (1 + l2_squared(v1, v2)) です。
構文は以下のとおりです。
l2_similarity(vector v1, vector v2)
パラメータの説明は以下のとおりです。
ベクトル型以外に、パラメータはベクトル型にキャスト可能な任意の型を受け入れます。これには、単一レベルの配列型(例:
[1,2,3,..])や文字列型(例:'[1,2,3]')が含まれます。2つのパラメータの次元は同じである必要があります。
単一レベルの配列型パラメータが存在する場合、その要素に
NULLを含めることはできません。
戻り値の説明は以下のとおりです。
戻り値は
similarity(double)型の類似度値であり、値が大きいほど類似していることを示します。任意のパラメータが
NULLの場合、NULLを返します。
例は以下のとおりです。
CREATE TABLE t14(c1 vector(3));
INSERT INTO t14 VALUES('[1,2,3]');
INSERT INTO t14 VALUES('[1,2,1]');
SELECT l2_similarity(c1, [1,2,3]) FROM t14;
返される結果は以下のとおりです。
+----------------------------+
| l2_similarity(c1, [1,2,3]) |
+----------------------------+
| 1 |
| 0.2 |
+----------------------------+
2 rows in set
または、より単純な例:
SELECT l2_similarity([1,0,0], [0,1,0]);
返される結果は以下のとおりです。
+---------------------------------+
| l2_similarity([1,0,0], [0,1,0]) |
+---------------------------------+
| 0.3333333333333333 |
+---------------------------------+
1 row in set
算術関数
算術関数は、ベクトル型と「ベクトル型、1次元配列型、特殊な文字列型」との間、および、1次元配列型と「1次元配列型、特殊な文字列型」との間で、加算(+)、減算(-)、乗算(*)の算術計算を提供します。計算は要素ごとに行われます。例えば、加算の場合は以下のようになります。
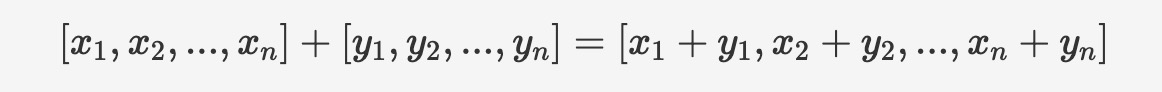
構文については以下のとおりです:
v1 + v2
v1 - v2
v1 * v2
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。これには、1次元配列(例:
[1,2,3,..])と文字列(例:'[1,2,3]')が含まれます。注意: 2つのパラメータは同時に文字列タイプにすることはできません。少なくとも1つのパラメータはベクトルまたは1次元配列タイプでなければなりません。2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素にNULLを含めることはできません。
戻り値の説明は以下のとおりです:
2つのパラメータのうち少なくとも1つがベクトル型の場合、戻り値はベクトルパラメータと同じベクトル型になります。
2つのパラメータのうち、1次元配列タイプしかない場合、戻り値は
array (float)タイプになります。いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t6(c1 vector(3));
INSERT INTO t6 VALUES('[1,2,3]');
SELECT [1,2,3] + '[1.12,1000.0001, -1.2222]', c1 - [1,2,3] FROM t6;
結果は次のとおりです:
+---------------------------------------+--------------+
| [1,2,3] + '[1.12,1000.0001, -1.2222]' | c1 - [1,2,3] |
+---------------------------------------+--------------+
| [2.12,1002,1.7778] | [0,0,0] |
+---------------------------------------+--------------+
1 row in set
比較関数
比較関数は、ベクトル型と「ベクトル型、1次元配列型、特殊な文字列型」との比較計算を提供します。これには、=、!=、>、<、>=、<= の比較記号が含まれます。計算方法は、要素ごとの辞書順比較です。
構文については以下のとおりです:
v1 = v2
v1 != v2
v1 > v2
v1 < v2
v1 >= v2
v1 <= v2
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。これには、1次元配列(例:
[1,2,3,..])と文字列(例:'[1,2,3]')が含まれます。注意
2つのパラメータのうち、少なくとも1つはベクトル型でなければなりません。
2つのパラメータの次元は同じでなければなりません。
パラメータに1次元配列を指定する場合、その配列の要素にNULLを含めることはできません。
戻り値の説明は以下のとおりです:
戻り値はbool型です。
いずれかのパラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t7(c1 vector(3));
INSERT INTO t7 VALUES('[1,2,3]');
SELECT c1 = '[1,2,3]' FROM t7;
結果は次のとおりです:
+----------------+
| c1 = '[1,2,3]' |
+----------------+
| 1 |
+----------------+
1 row in set
集計関数
注意
ベクトル列をGROUP BY条件として使用することはサポートされていません。DISTINCTもサポートされていません。
Sum
Sum関数は、テーブル内のベクトル列の合計を計算するために使用されます。要素ごとに累積加算することで、合計ベクトルが得られます。
構文については以下のとおりです:
sum(vector v1)
パラメータの説明は以下のとおりです:
- ベクトル型のみサポートされています。
戻り値の説明は以下のとおりです:
sum (vector)の値を返します。
例:
CREATE TABLE t8(c1 vector(3));
INSERT INTO t8 VALUES('[1,2,3]'),('[2,3,4]'),('[3,4,5]');
SELECT sum(c1) FROM t8;
結果は次のとおりです:
+---------+
| sum(c1) |
+---------+
| [6,9,12] |
+---------+
1 row in set
多行ベクトルを要素ごとに加算すると、1次元目は1+2+3=6、2次元目は2+3+4=9、3次元目は3+4+5=12となるため、結果は [6,9,12] です。
Avg
Avg関数は、テーブル内のベクトル列の平均値を計算するために使用されます。
構文については以下のとおりです:
avg(vector v1)
パラメータの説明は以下のとおりです:
- ベクトル型のみサポートされています。
戻り値の説明は以下のとおりです:
avg (vector)の値を返します。このベクトル列の
NULL行にはカウントされません。入力パラメータが空の場合、
NULLを出力します。
例:
CREATE TABLE t9(c1 vector(3));
INSERT INTO t9 VALUES('[2,4,6]'),('[4,6,8]'),('[6,8,10]');
SELECT avg(c1) FROM t9;
結果は次のとおりです:
+---------+
| avg(c1) |
+---------+
| [4,6,8] |
+---------+
1 row in set
多行ベクトルの要素ごとの平均:1 番目の次元 (2+4+6)/3=4、2 番目の次元 (4+6+8)/3=6、3 番目の次元 (6+8+10)/3=8 なので、平均値は [4,6,8] です。
その他の一般的なベクトル関数
Vector_norm
Vector_norm関数は、ベクトルのユークリッドノルム(大きさ)を計算するために使用されます。これは、ベクトルと原点間のユークリッド距離を表します。計算方法は以下のとおりです:
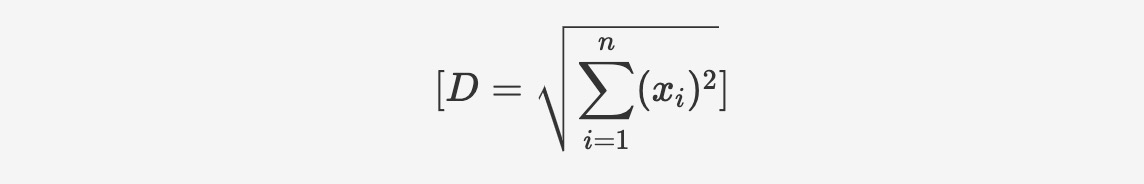
構文については以下のとおりです:
vector_norm(vector v1)
パラメータの説明は以下のとおりです:
ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。これには、1次元配列(例:
[1,2,3,..])と文字列(例:'[1,2,3]')が含まれます。パラメータに1次元配列を指定する場合、その配列の要素にNULLを含めることはできません。
戻り値の説明は以下のとおりです:
norm(double)のノルム値を返します。パラメータが
NULLの場合、NULLを返します。
例:
CREATE TABLE t10(c1 vector(3));
INSERT INTO t10 VALUES('[1,2,3]');
SELECT vector_norm(c1),vector_norm([1,2,3]) FROM t10;
結果は次のとおりです:
+--------------------+----------------------+
| vector_norm(c1) | vector_norm([1,2,3]) |
+--------------------+----------------------+
| 3.7416573867739413 | 3.7416573867739413 |
+--------------------+----------------------+
1 row in set
ベクトルの正規化
ベクトルの正規化(Normalization)とは、ベクトルの長さ(ノルム)を1に標準化する処理のことです。vector_norm 関数は、このベクトルの正規化を行うためによく使用されます。
l2_distance 距離タイプを使用するベクトルインデックスについては、類似度検索の精度を向上させるために、ベクトルに対して正規化処理を行うことを推奨します。正規化後のベクトルのノルムは 1 となり、L2 距離の範囲は [0, 2] の間に制限されます。これにより、類似度の値が極端に小さくなることで生じる精度の問題を回避できます。
例として、ベクトル [3, 4] の場合:
- ベクトルのノルム:
vector_norm([3, 4]) = √(3² + 4²) = 5 - 正規化後:
[3, 4] / 5 = [0.6, 0.8]
正規化後のベクトルのノルムは 1 になります。検証方法は以下のとおりです。
SELECT vector_norm([0.6, 0.8]);
返される結果は以下のとおりです。
+-------------------------+
| vector_norm([0.6, 0.8]) |
+-------------------------+
| 1.000000029802322 |
+-------------------------+
1 row in set
Vector_dims
Vector_dims関数は、ベクトルの次元を返すために使用されます。
構文については以下のとおりです:
vector_dims(vector v1)
パラメータの説明は以下のとおりです:
- ベクトル型に加えて、ベクトル型へ強制的に型変換できる他のデータ型もパラメータとして指定できます。これには、1次元配列(例:
[1,2,3,..])と文字列(例:'[1,2,3]')が含まれます。
戻り値の説明は以下のとおりです:
dims (int64)の次元値を返します。パラメータが
NULLの場合、エラーが発生します。
例:
CREATE TABLE t11(c1 vector(3));
INSERT INTO t11 VALUES('[1,2,3]');
INSERT INTO t11 VALUES('[1,1,1]');
SELECT vector_dims(c1), vector_dims('[1,2,3]') FROM t11;
結果は次のとおりです:
+-----------------+------------------------+
| vector_dims(c1) | vector_dims('[1,2,3]') |
+-----------------+------------------------+
| 3 | 3 |
| 3 | 3 |
+-----------------+------------------------+
2 rows in set