

カラムナエンジン(columnar engine)
大規模データの複雑な分析や膨大なデータのアドホッククエリシナリオにおいて、カラムストアはAPデータベースにおける重要な技術の一つです。カラムストアは、行指向ストレージとは異なるデータファイルの編成方法で、テーブル内のデータを列単位で物理的に配置します。データをカラムストアで格納すると、分析シナリオでクエリ計算に使用される列データのみをスキャンでき、全行スキャンを回避してIOやメモリなどのリソース使用量を削減でき、計算速度が向上します。また、カラムストアは本質的により良いデータ圧縮条件を備えており、より高い圧縮率を得やすく、ストレージ容量とネットワーク転送帯域幅を削減できます。
OceanBaseは、LSM-Tree (Log Structured Merge-Tree)のデータストレージ構造に基づき、高同時実行トランザクション処理(TP)機能の継続的な最適化によって、ランダム書き込み・リアルタイム更新・強い一貫性などのシナリオでのパフォーマンスを継続的に向上させ、大量のエンジニアリング実践経験を蓄積し、独自のストレージエンジン技術体系を構築してきました。同時に、LSM-Treeの階層的なメジャーコンパクション特性とデータ静的構造化機能により、バッチ書き込み、低頻度更新を特徴とするOLAPシナリオに本質的に適応しています。カラムストアのデータ圧縮、階層のメジャーコンパクション戦略、ストレージ断片化の最適化を通じて、分析系ワークロードに求められる高効率なスキャン要求を満たすと同時に、TPとAPの混合ワークロードを単一のアーキテクチャで支えることを実現しています。
V4.3バージョンでは、既存の技術の蓄積をベースにOceanBaseストレージエンジンを引き続き拡張して、カラムストアのサポートを実現し、ストレージの統合を実現しています。1つのコード、1つのアーキテクチャ、1つのOBServer、列指向データと行指向データの共存で、TP系とAP系のクエリのパフォーマンスの両立を真に実現しています。
カラムナエンジンアーキテクチャ
OceanBaseデータベースは、ネイティブ分散データベースとして、ユーザーデータをデフォルトでマルチレプリカで格納します。マルチレプリカの利点を活用して、ユーザーに強力なデータ検証やデータ移行の再利用などのさらに拡張された体験を提供するため、独自のLSM-Treeストレージエンジンも多くの目的特化型の設計を行っています。まず、ユーザーデータ全体は、大きく二つの部分に分けることができます:ベースラインデータと増分データです。
ベースラインデータ
グローバル一貫性を持つバージョン管理:OceanBaseデータベースは、従来のLSM-Tree設計パラダイムを打ち破り、分散型マルチレプリカアーキテクチャの基盤を活用して「日次コンパクション」メカニズムを実現しています。システムは定期的または必要に応じてグローバルなバージョン番号を選定し、テナントはそのバージョン番号に基づいて全レプリカでメジャーコンパクション(Major Compaction)を実行します。これにより、特定のバージョンに対応するベースラインデータが生成されますが、このデータはすべてのレプリカで物理的に完全に一致します。
多様なストレージ形式のサポート:ベースラインデータは、行指向・列指向・行列混合形式の3つの物理形態をサポートしています。ユーザーは、テーブル作成設定を通じて柔軟に選択でき、異なるビジネスシナリオのストレージ要件を満たします。
増分データ
- 動的マルチバージョン管理:最新のベースラインデータが生成された後に行われるすべての書き込み(メモリ上のMemTableに書き込まれた直後のデータや、ディスク上のSSTableにダンプされたデータ)は、増分データとして扱われます。各レプリカは独立して複数バージョンのデータを管理して、データの一貫性は保たれません。また、ベースラインデータが特定バージョンに基づいて生成されるのとは異なり、増分データにはすべてのバージョンのデータが含まれます。
- 行指向ストレージの優先戦略:増分データは、強制的に行指向モードで保存されます。これにより、トランザクション処理(TP)の実行パスが、ネイティブの行指向アーキテクチャと完全に互換性を保つことが保証され、トランザクションログやロック機構といったコアコンポーネントを共有できます。
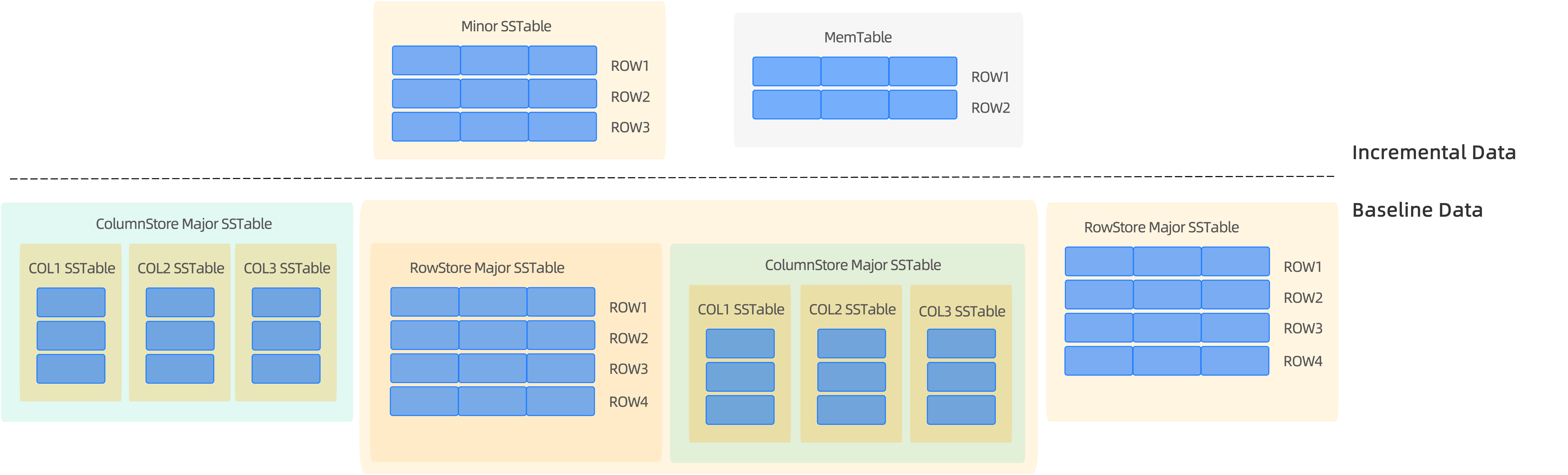
行列混合ストレージ体系
OceanBaseデータベースは、カラムストアを用いるシナリオでは更新処理の頻度が少なく、制御しやすいという点に着目し、独自のベースラインデータと増分データの特性を結合し、アプリケーション層に透過的なカラムストア実装方式を提案しています:
- ストレージ形態のデカップリング:ベースラインデータは列指向形式で構成されています(各列を独立したSSTableとし、それらを仮想的に一つの論理テーブルとして扱う)。一方、増分データは行指向形式を維持します。これにより、DML操作やアップストリーム・ダウンストリームとの同期において、ストレージの違いを意識する必要が完全になくなります。
- 動的同期エンジン:データベースの内部で、行指向データと列指向データ間の双方向同期パイプラインを構築します。既存のOLAPシステムからの移行や、行指向テーブルからのアップグレードをスムーズに行うことが可能です。業務アプリケーションは、ストレージ形式の違いを意識する必要はありません。
- インテリジェントなルーティング機能:オプティマイザーから実行エンジンまで、システムは負荷特徴に基づいて最適な行/列アクセスパスを自動選択し、カラムストアのパフォーマンス優位性をAPシナリオで十分に発揮させながら、TPトランザクションに対する行指向ストレージのネイティブサポートを保持します。
主要な統合機能
| 機能面 | 主要な技術実装 |
|---|---|
| SQLの一体化 |
|
| ストレージの一体化 |
|
| トランザクションの一体化 |
|
カラムストアの主な特徴
- 特徴1:適応型コンパクション(Compaction)
新しい列指向のストレージモードの導入後、データのメジャーコンパクション動作は、従来の行指向データのみの場合と比べて大きく変化しました。増分データはすべて行指向であるため、ベースラインデータとのコンパクション後に各列の独立したSSTableに分割する必要があり、コンパクション時間とリソース使用量が行指向と比較して大幅に増加します。そこで、列指向テーブルのコンパクションを高速化するため、ストレージ層ではプロセスに以下の適応的な最適化を加えています。列指向テーブルでは、行指向テーブルと同様にデータを水平分割して並列にコンパクションすることで高速化を図るだけでなく、新たに垂直分割による高速化も追加しました。これは、複数の列のコンパクション処理を、単一のコンパクションタスク内にまとめて実行するものです。さらに、1つのタスクが担当する列の数は、システムリソースの状況に応じて自動的に増減させることが可能です。これにより、システム全体としてコンパクションの速度とメモリ消費量のバランスを最適化します。
- 特徴2:列指向エンコードアルゴリズム
OceanBaseデータベースでは、データは2段階の圧縮を経て保存されます。第1段階はOceanBase自社開発の行指向・列指向混合エンコード圧縮で、第2段階は汎用圧縮です。このうち、行列混合エンコードはデータベースの内蔵アルゴリズムであるため、非解凍で直接クエリをサポートでき、同時にエンコード情報を利用してクエリのフィルタリングを高速化できます。 しかし、既存の行列混合エンコードアルゴリズムは依然として行指向のデータ構成に最適化されていました。そこで、列指向テーブル向けに全く新しい列指向エンコードアルゴリズムを実装しました。既存のエンコードアルゴリズムと比較して、新しいアルゴリズムはクエリの全面的なベクトル化実行をサポートしており、異なる命令セットに対応したSIMD最適化をサポートします。また、数値型の圧縮率を大幅に向上させ、既存アルゴリズムと比較してパフォーマンスと圧縮率の全面的な向上を実現しています。
- 特徴3:Skip Index
通常、一般的な列指向データベースは、各列データについて一定の粒度で事前に集約計算を行い、集約結果をデータと一緒に永続化します。ユーザーのクエリリクエストが列データにアクセスする際、データベースは事前に集約されたデータを使用してデータをフィルタリングできるので、データアクセスのオーバーヘッドを大幅に削減でき、不要なIO消費を減らせます。このカラムナエンジンでは、skip indexのサポートが追加されています。各列データに対してマイクロブロック単位で最大値、最小値、およびnull総量などの多角的な集約計算を行います。また、階層的に上位への集約加算を行って、マクロブロックやSSTableなどのより大きな粒度の集約値を取得します。ユーザークエリは、スキャン範囲に基づいて継続的にドリルダウンすることにより、適切な粒度の集約値を選択してフィルタリングと集約の出力を行うことができます。
- 特徴4:クエリプッシュダウン
OceanBaseデータベースはV4.xバージョンより、ストレージ層の演算子と式が全面的にベクトル化実行に対応しており、一部のシナリオでのクエリプッシュダウンをサポートしています。カラムナエンジンでは、プッシュダウン機能がさらに強化および拡張されています。具体的には以下が含まれます:
- すべてのクエリfilterのプッシュダウン。同時にfilterタイプに基づいて、skip indexとエンコード情報をさらに活用して高速化できます。
- 常用集約関数のプッシュダウン。非group byシナリオで、現在のところ、count/max/min/sum/avgなどの集約関数をストレージエンジンにプッシュダウンできます。
- group byのプッシュダウン。NDV(個別値の数)が少ない列では、group byのストレージ計算へのプッシュダウンをサポートしており、マイクロブロック内の辞書情報を利用して大幅な高速化を実現します。
カラムストアの詳細な紹介と使用ガイドについては、カラムストアを参照してください。
共有ストレージモード
OceanBaseデータベースは、シェアードナッシング(Shared-Nothing, SN) と 共有ストレージ(Shared-Storage, SS) という2つのデプロイモードをサポートしています。
共有ストレージ(Shared-Storage)モードは、データを共有ストレージデバイスに集中して保存し、複数のデータベースノードが同一のデータにアクセスできるアーキテクチャであり、パブリッククラウド環境で適用されます。このモードは主に、ストレージ管理の簡素化、リソース利用率の向上、そして特定のシナリオにおけるより柔軟な高可用性切り替え(フェイルオーバー)をサポートするために使用されます。
ストレージの冗長性を低減: 従来のシェアードナッシング・アーキテクチャでは、各ノードが独立したデータレプリカを保持するため、ストレージリソースの浪費が生じがちでした。一方、共有ストレージでは複数のコンピュートノードが同一のデータを読み取ることができるため、レプリカ数が減少し、全体的なストレージコストを削減できます。
迅速な障害復旧: コンピュートノードがダウンした場合、他のノードが共有ストレージ内のデータに直接アクセスできるため、複雑なレプリカ同期やデータ移行プロセスに依存することなく、迅速にサービスを引き継ぐことが可能です。
運用管理の簡素化: 統一されたストレージプールにより、バックアップ、スナップショット、監視などの操作が容易になり、データベースシステムの保守性が向上します。
OceanBaseのコンピュートとストレージの分離に基づく「2レプリカ構成」アーキテクチャでは、以下を実現します:
- 低コスト: 全データをオブジェクトストレージに保存し、ホットデータをローカルディスクにキャッシュすることで、P99クエリ性能を保証しつつストレージコストを削減します。弾力的なスケーリング(伸縮性)を備えており、コンピュートとストレージを個別に拡張・縮小可能です。シェアードナッシング・アーキテクチャと比較した際のパフォーマンス低下は平均0.3%〜1.7%に抑えられています。
- 高可用性: 「2F(フル機能レプリカ)」の2レプリカデプロイモードによりコンピュートノードの高可用性を保証します。Paxosベースの独立したログストレージサービスと組み合わせることで、システムは RPO=0、RTO<8秒 を保証します。
OceanBaseのコンピュートとストレージの分離に基づく「単一レプリカ構成」アーキテクチャでは、以下を実現します:
究極のコストパフォーマンス: 全データを低コストなオブジェクトストレージに保存し、ホットデータをローカルディスクにキャッシュします。単一レプリカ形態は、2F1Aや3Fといったクラスタ形態と比較して、計算コストを2〜3倍削減します。また、単一ゾーン内でも、変化する性能要件に合わせてコンピュートノードを迅速に追加・削除することが可能です。
高可用性: 同一地域内(同城)で冗長化されたオブジェクトストレージにより、データセンターレベルの災害復旧(DR)をサポートします。単一レプリカ形態であっても、Paxosベースの独立したログサービスおよび共有ストレージを組み合わせることで、コンピュートノードがダウンした際にも迅速に新しいコンピュートノードを立ち上げ、高可用性機能を提供します。
ベクトル化実行エンジン
ベクトル化実行は、効率的にデータのバッチ処理を行える技術です。分析クエリにおいて、ベクトル化実行により実行パフォーマンスを大幅に向上させることができます。OceanBaseデータベースは、V3.2バージョンでベクトル化実行エンジンが導入されましたが、デフォルトでは無効でした。OceanBaseデータベースV4.0バージョンから、デフォルトでベクタ化実行エンジンが有効になりました。また、OceanBaseデータベースV4.3バージョンではベクトル化エンジン2.0が実装されており、データ形式、演算子実装の最適化、ストレージベクトル化の最適化などにより、ベクトル化エンジンの実行パフォーマンスが大幅に向上しています。

データ形式の概要
ベクトル化エンジン2.0では、新しい列単位のデータ形式が導入されており、データ記述情報(null、len、ptr)をそれぞれ列単位で格納して、冗長ストレージを回避しています。異なるデータ型と使用シナリオに基づいて、3つのデータ形式が設計されています:固定長データ形式、可変長離散形式、および可変長連続形式です。
- 固定長データ形式:一度だけlength値を格納すればよく、冗長ストレージが不要です。直接アクセスでき、データ局所性が良好です。1.0バージョンと比較して、容量の節約、効率の向上が実現され、ポインタのswizzling操作も省略されました。
- 可変長離散形式:各データはメモリ内で連続しない可能性があり、アドレスポインタと長さで記述されています。この形式はエンコードデータ時にディープコピーを回避できます。ショートサーキット評価シナリオに適しており、データ再編成を回避します。
- 可変長連続形式:データはメモリ内で連続して格納され、長さ情報とオフセットアドレスがoffset配列に記述されます。この形式はデータアクセス効率が向上しますが、ショートサーキット評価や、カラムストアにおけるエンコーディングとプロジェクションの際には、データの再編成やディープコピーが必要です。そのため、主に列単位のマテリアライズシナリオで使用されます。
演算子と式のパフォーマンス最適化
ベクトル化エンジン2.0は、演算子と式を全面的に最適化しています。重要な考え方として、新しい形式の情報とデータ構造に特化した実装を利用して、CPUのキャッシュミスと命令オーバーヘッドを削減し、全体の実行パフォーマンスを向上させることが挙げられます。主な最適化には、以下が含まれます:
- バッチデータのプロパティ情報の活用:バッチデータの特徴情報を維持し、NULL値の特別処理とフィルタリング判断を排除し、SIMD計算を最適化します。
- アルゴリズムとデータ構造の最適化:中間結果のマテリアライズ構造を最適化し、行/列マテリアライズをサポートしています。Sort演算子はソートキーと非ソートキーの分離マテリアライズを実装しており、ソート処理中のキャッシュミスが削減され、全体的な効率が向上しています。
- 特化実装による最適化:具体的なシナリオに特化した最適化が行われています。たとえば、複数列固定長join keyの1つの固定長列へのエンコードや集約計算の特化実装により、実行効率が大幅に向上しました。
ストレージのベクトル化による最適化
ストレージ層で、SIMD高速化プロジェクション、述語プッシュダウン、集約プッシュダウン、groupbyプッシュダウンなどを使用して、新しいベクトル化形式を全面的にサポートしています。プロジェクション時に列タイプと長さに基づいてカスタマイズされたテンプレートにより計算を簡素化します。述語計算は列エンコード上で直接実行され、複雑な式の高速計算を容易にしています。集約プッシュダウンは、中間層の事前集約情報を利用して統計関数を効率的に処理し、groupbyプッシュダウンはエンコードデータ情報を利用してパフォーマンスを大幅に高速化します。
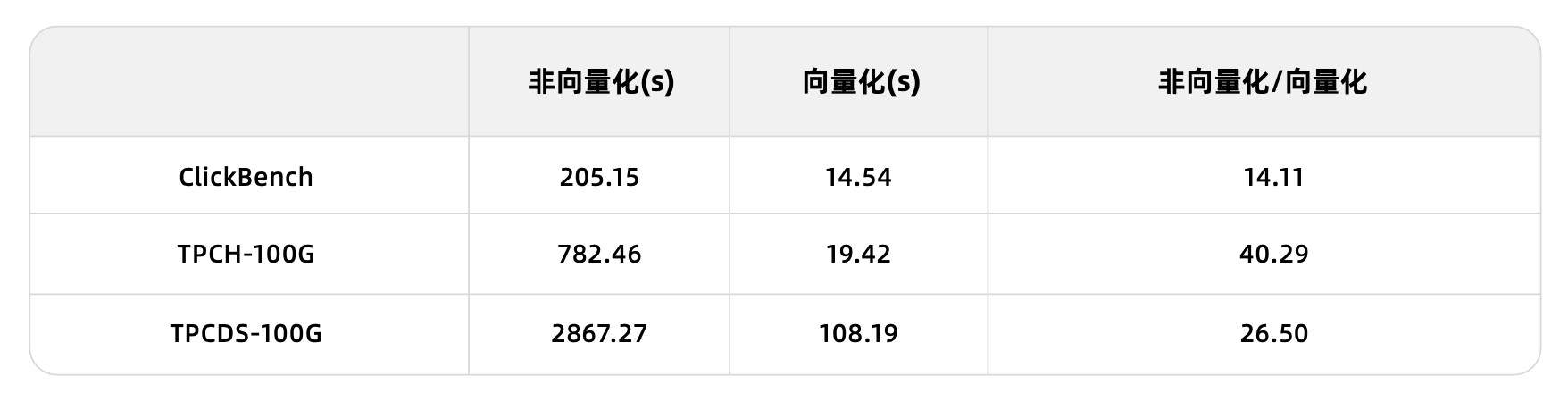
全体的なパフォーマンスにおいて、OceanBaseデータベースでベクトル化機能のON/OFF比較テストを実施した結果、ベクトル化エンジンは非ベクトル化エンジンと比較して、性能が1オーダー向上しました。
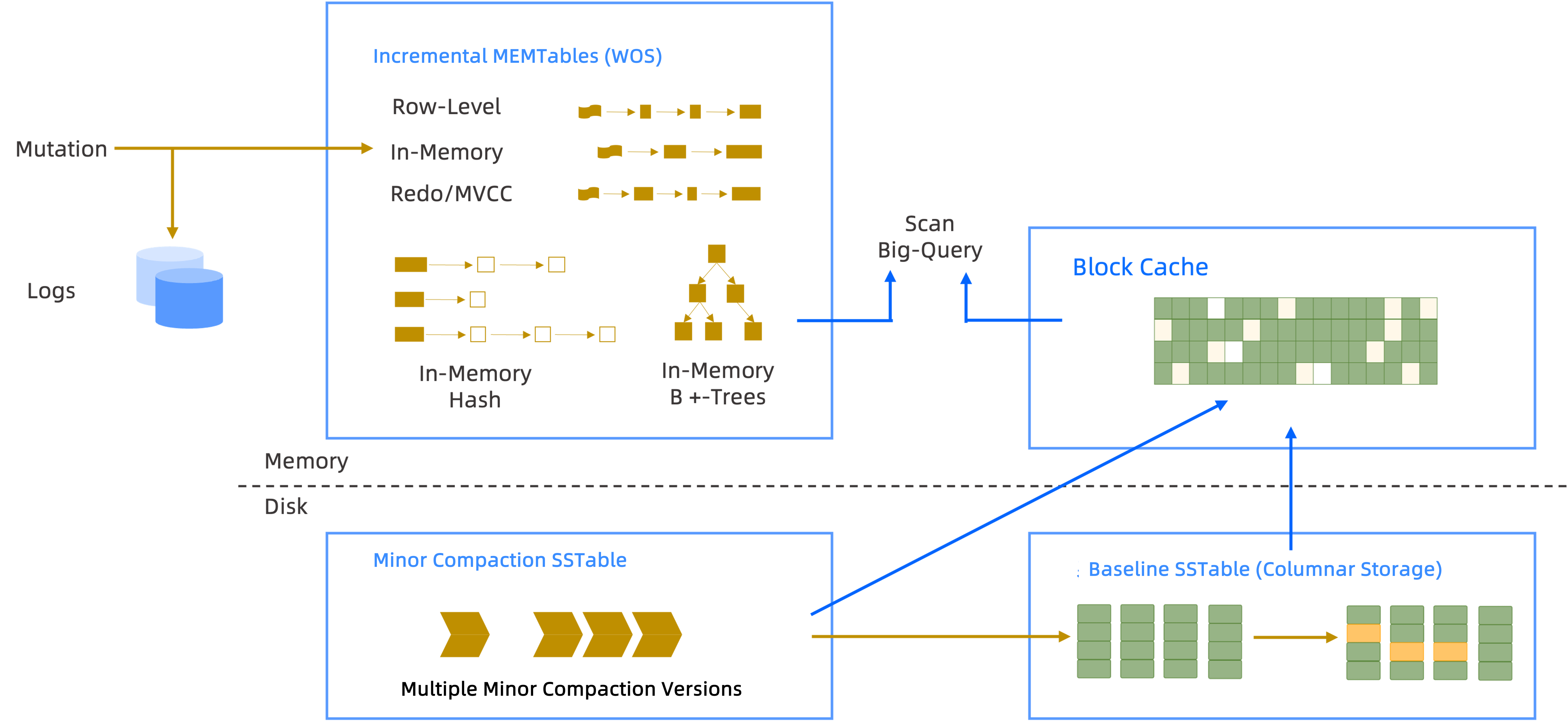
リアルタイム書き込み
OceanBaseは、LSM-Tree (Log-Structured Merge-tree)アーキテクチャを採用しています。このアーキテクチャの設計により、データベースのリアルタイム書き込み機能を保証しています。以下ではOceanBaseデータベースのリアルタイム書き込み機能について詳しく説明します。
コアストレージのメカニズム
LSM-Tree
OceanBaseは、効率的なリアルタイム書き込みをサポートするため、LSM-Tree構造を用いて増分データを格納しています。LSM-Treeは、書き込み操作の最適化のために特別に設計された特殊なツリー構造です。重要な考え方として、まず書き込み操作をメモリ内の構造に記録し、一定量に達してから非同期でバッチ書き込みをディスクに対して行うことで、ディスクI/Oの回数を大幅に削減し、書き込みパフォーマンスを向上させることが挙げられます。OceanBaseは、これらの増分データをダンプおよびコンパクションプロセスを通じて定期的にベースラインデータとコンパクションし、データの一貫性と完全性を保証します。
リアルタイム書き込み機能
OceanBaseデータベースは、LSM-Treeアーキテクチャを採用しており、リアルタイムデータの書き込み処理において卓越したパフォーマンスを発揮します。少量のデータ更新であっても、大量のデータインポートであっても、OceanBaseデータベースは迅速に応答し、データのリアルタイム書き込みを保証します。その主なパフォーマンスには、以下の側面があります:
- 効率的な書き込み処理:OceanBaseデータベースはLSM-Treeにより、書き込み操作を集中的に処理し、ディスク操作を削減し、書き込み効率を向上させます。
- データの即時クエリ可能性:データがLSM-Treeのメモリ構造に書き込まれると、即座に外部へのクエリ提供が可能となり、データのリアルタイム性が保証されます。
- 最適化されたデータコンパクションプロセス:インテリジェントなダンプおよびメジャーコンパクション戦略により、効率的なクエリをサポートします。
- 強力な並行処理機能:OceanBaseデータベースは、分散型アーキテクチャを利用することにより、複数ノードで並列して書き込み操作を処理できるため、リアルタイムのデータ処理機能を大幅に向上させます。
インテリジェント・マテリアライズド・ビュー
インテリジェント・マテリアライズド・ビューの真価は、ユーザーがSQL形式でデータ処理結果を定義するだけで、OceanBaseがデータの更新や計算の依存関係を自動的に管理する点にあります。これにより、企業は複雑なETLスクリプトの記述やデータパイプラインの管理が不要になります。ターゲットとなるデータ構造を定義するだけで、OceanBaseがデータのリフレッシュ、依存関係の管理、そしてパフォーマンスの最適化を自動的に処理します。このアプローチは、データエンジニアリングのプロセスを大幅に簡素化して運用コストを削減すると同時に、データの鮮度と整合性を確実に保証します。
OceanBaseデータベースがサポートしているのは、非同期マテリアライズドビューです。つまり、ベーステーブルのデータが変更されても、マテリアライズドビューは即座に更新されず、ベーステーブルのDML操作の実行パフォーマンスを保証します。ただし、マテリアライズドビューのデータには、ベーステーブルに対する遅延が発生し、データの更新はタイムリーなリフレッシュに依存します。マテリアライズドビューデータの更新は、2つの戦略をサポートしています:フル更新と増分更新です。
- フル更新は、マテリアライズドビューに対応するクエリステートメントを直接再実行し、既存のビューの結果データを完全に計算して上書きします。遅延要件が低く、ベーステーブルのデータ更新頻度が低い、またはデータ量が少ないシナリオに適しています。たとえば、毎日または毎週更新されるデータ集約レポートなどです。
- 増分更新は、前回のリフレッシュ以降のデータ変更部分のみを処理し、リフレッシュに必要な時間とリソースを大幅に削減できます。正確な増分更新を実現するため、OceanBaseデータベースにはOracleのMLOG (Materialized View Log)に類似したマテリアライズドビューログ機能が実装されています。ベーステーブルのインクリメンタル更新データを詳細に記録することで、マテリアライズドビューの迅速な増分更新を保証します。増分更新は、特に遅延要件が高く、データ量が膨大で変更が頻繁なビジネスシナリオに適しています。たとえば、リアルタイム取引システムでは、データが毎分または毎秒変化する可能性があります。
OceanBaseデータベースは、リアルタイムマテリアライズドビューもサポートしており、データのリアルタイム分析が可能です。リアルタイムマテリアライズドビューは、マテリアライズドビューログメカニズムを利用してベーステーブルのデータ変更をキャプチャおよび処理し、クエリ時にオンラインでデータ変更を計算および統合します。そのため、マテリアライズドビューが最新の変更データを物理的に格納していなくても、ユーザーがベーステーブルを直接クエリするのと一致したクエリ結果を確実に取得できます。同時に、マテリアライズドビューのクエリ・リライト機能を利用して、透過的なクエリの高速化を実現します。
OceanBaseデータベースでは、マテリアライズドビューに主キーを指定したり、インデックスを作成したりすることが可能です。これにより、主キーやインデックスに基づく単一行検索、範囲クエリ、関連するシナリオのパフォーマンスが最適化されます。マテリアライズドビューが複数テーブルJOINで形成された大きなワイドテーブルである場合、カラムストアのマテリアライズドビューを作成することにより、特定のクエリのパフォーマンスを向上させることができます。また、パーティションマテリアライズドビューを作成することにより、パーティションプルーニング機能を利用して操作対象のデータ量を削減できます。
最新のOceanBase V4.3.5バージョンでは、ネストされたマテリアライズドビュー(Nested Materialized View、Nested MV)機能が導入されています。これにより、既存のマテリアライズドビューを基盤として、新しいマテリアライズドビューを簡単に構築でき、データウェアハウスのETLプロセスに適しています。ネストされたマテリアライズドビューは、データの変換とロードの段階で中間結果を生成でき、これらの結果を後続処理の入力として使用して、データ処理プロセス全体の効率をさらに最適化します。
マテリアライズドビューの詳細と使用ガイドについては、マテリアライズドビューの概要(MySQLモード)および マテリアライズドビューの概要(Oracleモード)を参照してください。
インテリジェント・マテリアライズド・ビューの主な特徴:
- 宣言的なSQL定義: インテリジェント・マテリアライズド・ビューでは、ユーザーが宣言的な方法でデータ処理結果を定義でき、変換ステップを手動で管理する必要がありません。ユーザーは標準的なSQLクエリを記述してデータ変換ロジックを指定するだけで、OceanBaseがそのクエリの実行と保守を担当します。
- 自動リフレッシュメカニズム: OceanBaseは、ユーザーが指定した目標とするデータの鮮度要件に基づき、スケジューリングや実行を含むデータリフレッシュのカスケード関係を自動的に処理します。ユーザーはデータがどの程度最新であるべきか(例:30秒や5分の許容ラグ)を定義するだけで、OceanBaseが自動的にその要件への準拠を保証します。
- 増分処理の最適化: インテリジェント・マテリアライズド・ビューは自動増分ビューメンテナンス技術を使用しており、フル更新を実行するのではなく、前回の更新以降の変更分のみを計算します。これにより、パフォーマンスが大幅に向上し、計算コストが削減されます。
- 依存関係の管理: インテリジェント・マテリアライズド・ビューはデータの依存関係を自動的に追跡し、ベースデータが変化した際に正しい順序で更新されるようにします。これにより、複雑なデータパイプラインの依存関係を手動で管理する必要がなくなります。
オプティマイザ
OceanBaseデータベースのクエリオプティマイザは、HTAPハイブリッドワークロードおよびリアルタイム分析シナリオ向けに設計されています。一般に、トランザクション型(TP)ワークロードは「単一クエリのアクセスデータ量が少ない」「RT(応答時間)への要求が厳しい」「スループットが高い」という特徴を持ちます。一方、分析型(AP)ワークロードは「単一クエリのアクセスデータ量が多い」「スループットは相対的に低い」という特徴を持ちます。負荷タイプが異なれば、求められる実行計画の形態やチューニング方法も大きく異なります。
- TPワークロードでは通常、基本テーブルのフィルタ述語や結合述語に対して適切なインデックス構造を作成する必要があり、各テーブルができるだけ適切なインデックスパスを選択してデータスキャン量を大幅に削減することが求められます。
- APワークロードでは通常、カラムストアによるフルテーブルスキャンに依存し、Skip Index(スキップインデックス)を使用して一部のデータブロックのスキャンを高速にスキップします。また、並列度を高めることでクエリの応答時間を短縮します。
OceanBaseのAPオプティマイザは、TPオプティマイザの能力を完全に継承した上で、各種の複雑なクエリシナリオに対し、各モジュールの機能強化を行っています。
より完全なクエリ書き換え能力:クエリ書き換えモジュールは豊富な書き換えアルゴリズムをサポートしています。異なる書き換えアルゴリズムが異なるパターンにマッチし、対応する等価変換を行うことで、業務SQLをより「良い」方向へ改造します。現在、ビューのマージ、サブクエリの引き上げ(Subquery Unnesting)、内部結合の除去、外部結合の除去、恒真・恒偽条件の除去といったルールベースの書き換えアルゴリズムに加え、OR Expansion、JA(Join Aggregation)サブクエリ引き上げ、Win Magic、Group-By Placementなどのコストベースの書き換えアルゴリズムもサポートしています。
分散実行計画の生成: OceanBaseは1段階方式の分散実行計画生成スキームを採用しています。これは、一般的なデータベースシステムが採用している2段階方式(まず最適な単一ノード計画を生成し、それを分散化してオプティマイザの設計を簡素化する方式)とは全く異なります。2段階方式はHTAPシナリオにおいて多くの問題に直面します。例えば、結合順序の列挙プロセスにおいて、単一ノード環境で最適なNEST-LOOP JOINアルゴリズムが、分散化されると大量のノード間データアクセスを発生させ、全体的な実行効率が分散HASH JOINアルゴリズムより著しく劣る場合があります。OceanBaseの1段階計画生成フレームワークは、結合順序や結合アルゴリズムを列挙する過程で、データ分布特性や並列化などの要素が計画選択に与える影響を同時に考慮し、多角的な要素を総合的に判断して、全体としてより優れた分散実行計画を選択します。
行・列パスの選択: HTAPハイブリッドワークロードを適切に処理するため、クエリオプティマイザの核心的なインテリジェント機能の一つが、自動的な行・列パス選択です。これは、あるクエリに対して、オプティマイザがデータアクセスの特徴に基づき、行ストア(Row Store)から読むか、カラムストア(Column Store)から読むかをインテリジェントに決定し、最適な実行パフォーマンスを目指すものです。OceanBaseは列指向スキャンに特化したコストモデルを設計し、新しい統計情報メカニズムを導入することで、列指向スキャンに対するSkip Indexのメリットを正確に評価し、行指向インデックスと列指向スキャンの間で的確な選択が行えるように保証しています。
より使いやすいAuto DOP:通常、データベースは複雑なSQL実行を高速化するためにパラレル実行を使用しますが、実際の業務シナリオにおいて、並列化を有効にすべきか、また並列度(DOP)をいくつにすべきかを容易に判断するのは困難です。OceanBaseはAuto DOP機能を提供しており、オプティマイザが計画生成時にクエリの所要時間を予測し、並列化の可否と適切な並列度を自動的に決定します。これにより、SQLはデフォルト状態で比較的優れたパフォーマンスを得ることができます。
実行計画管理: OceanBaseのSPM(SQL Plan Management、SQL実行計画管理)技術は、リアルタイム分析型業務の長期的かつ安定した稼働を保証する重要な技術です。データ量の急激な変化、統計情報の更新、あるいはデータベースのバージョンアップ後に、オプティマイザが以前より劣る新しい実行計画を選択してしまう状況に対し、この技術は実行計画の進化をインテリジェントに管理し、実際のトラフィックの一部を用いた検証を行うことで、実行計画のリグレッションを防ぎます。
詳細には、統計情報とコストベースの最適化を参照してください。
特殊インデックス
従来のリレーショナルデータベースでは、B-Tree、Hashなどのインデックスは主に構造化データの完全一致検索(数字、日付など)を対象としています。しかし、実際のビジネスでの半構造化データ(JSONドキュメントなど)、非構造化テキスト(ログ、長文テキスト)、および多次元分析シナリオの普及に伴い、OceanBaseは2種類の特殊なインデックスを提供しています:
- 全文インデックス:転置インデックスに基づいて実装され、形態素解析技術を使用してテキスト内容にキーワードマッピングを構築します。ログ分析、ドキュメント検索などのシナリオに適しています。
- 複数値インデックス:JSON配列フィールドに対して要素レベルのインデックスを構築し、配列を仮想行レコードに展開してB-Treeインデックスを構築することにより、集合データのクエリ効率を大幅に向上させます。
この2つのインデックスは、差別化されたデータ構造設計により、異なるデータ型(テキスト/JSON)とクエリモード(あいまい一致)に対して、それぞれ最適化を提供し、複雑なデータクエリの高速化層を共同で構成しています。
全文インデックス
リレーショナルデータベースでは、インデックスは通常、完全一致検索のクエリを高速化するために使用されます。しかし、従来のB-Treeインデックスは、大量のテキストデータとあいまい検索を処理する場合、しばしばパフォーマンス要件を満たすことができませんでした。この場合、全テーブルスキャンを実行して行ごとに一致するデータを検索することになり、特にテキスト量が大きく、データ量が膨大なシナリオではパフォーマンスのボトルネックを引き起こします。さらに、近似一致や関連性ソートなどの複雑なクエリ要件も、単純なSQLリライトでは実現が困難です。
これらの問題を解決するため、OceanBaseは現在、MySQL互換の全文インデックス機能をサポートしています。全文インデックスは、テキスト内容を事前に処理して、キーワードインデックスを構築することにより、全文検索の効率を大幅に向上させます。
全文インデックスは、テキストデータを高速に検索する技術です。その主な機能には以下が含まれます:
- 全文検索:全文検索インデックスを構築することで、文書全体や長文のテキストコンテンツを包括的にインデックス化し、より柔軟で効率的な検索を実現します。
- 高速な検索:ユーザーは入力したキーワードに基づいてデータベース内で一致するテキストを高速に検索でき、検索時間が大幅に短縮されます。
- 大量テキストの効率的な処理:全文インデックスは、記事、レポート、ウェブページ、電子メールなど、さまざまなタイプのテキストデータを効果的に処理し、ユーザーに正確で高速な検索体験を提供します。
- 複雑なクエリのサポート:基本的なキーワード検索に加えて、全文インデックスは近似マッチングや関連性ソートなどの複雑なクエリニーズもサポートでき、データベースの検索機能を大幅に向上させます。
全文インデックス機能の導入により、OceanBaseは大規模テキストデータと複雑な検索ニーズに直面した際に、クエリパフォーマンスを大幅に向上させ、ユーザーがより効率的に必要な情報を取得できるようにします。
全文インデックスの詳細な紹介と使用ガイドについては、全文インデックス(MySQLモード)を参照してください。
複数値インデックス
複数値インデックスは、OceanBaseデータベースのMySQLモードにおける特殊なインデックス機能で、主にJSONドキュメントや集合データ型の処理に使用されます。複数の値に対するクエリや複数の属性に対するクエリが必要なシナリオに適しています。その主な特徴は以下のとおりです:
- 配列または集合上にインデックスを作成できる
- 現在はJSONドキュメントに適用できる
- JSON配列要素の検索に基づくクエリ効率を向上させることができる
複数値インデックスはAPシナリオで非常に有用です。APシナリオは通常、複雑なデータ分析とレポート生成を含み、複数値インデックスはこれらの操作を高速化できます。たとえば、データウェアハウスでは、複数値インデックスを使用して複数次元のデータ分析を高速化し、レポート生成の効率を向上させることができます。具体的な適用シナリオは以下のとおりです:
- 多対多の関連クエリ:複数値インデックスの使用により、エンティティ間の多対多関係のクエリを最適化できます。たとえば、俳優と映画の関係で、JSON配列を使用して映画のすべての俳優を格納し、JSONの複数値インデックスを使用して特定の俳優が出演したすべての映画のクエリを高速に実行できます。
- タグとカテゴリのクエリ:エンティティが複数のタグやカテゴリを持つ場合、複数値インデックスを使用して関連するクエリを高速化できます。たとえば、商品の複数タグをJSON配列に格納し、JSONの複数値インデックスを使用して特定のタグを含む商品を高速に検索できます。
複数値インデックスの詳細な紹介と使用ガイドについては、複数値インデックスを参照してください。
複雑なデータ型
OceanBaseデータベースは、分散かつマルチモーダル統合のデータベースです。リアルタイム分析のシナリオにおいて、SQLエンジンを基盤とし、構造化・半構造化・非構造化データを単一のデータベース内で同時に処理することが可能です。
マルチモーダルストレージの基盤となるのはLOB(Large Object)であり、LOBはAIにおけるストレージおよびデータ処理において重要な役割を果たします。AIシナリオにおけるマルチモーダルデータ(画像、テキスト、音声、動画)はいずれもラージオブジェクトであるため、LOBのパフォーマンスは、AIの事前学習(プレトレーニング)をはじめとする計算効率に極めて大きな影響を与えます。OceanBaseはストレージ層において非常に効率的なLOB実装を提供しており、SQLレベルでは最大512MBのストレージをサポートし、DBMS.Lobパッケージを使用することで、TB級のラージオブジェクトの効率的な保存とアクセスに対応します。
データ分析のシナリオにおいて、OceanBaseはArray、Roaring Bitmap、Mapといったマルチモーダルデータ型をネイティブにサポートしています。これにより、構造化データの効率的な保存・クエリだけでなく、半構造化データや複雑な集計分析にも直接対応可能です。
- Roaring Bitmap/Map:大規模なタグ分析、ユーザーセグメンテーション(ターゲット抽出)、重複排除集計(Distinct Count)など、高度なデータマイニングのシナリオに適しています。
- Array:ログ検索、行動軌跡、多次元タグなどの複雑な業務に対して極めて高い柔軟性を提供し、真の意味での「多機能データベース」を実現します。
高圧縮ビットマップデータ型の詳細な紹介と使用ガイドについては、高圧縮ビットマップデータ型(RoaringBitmap)を参照してください。
配列型の詳細な紹介と使用ガイドについては、配列型を参照してください。
JSONは現在、最も汎用的な半構造化データ型として、トランザクション、分析、さらにはAIのシナリオにおいて非常に広く活用されています。
- トランザクションシナリオ:スキーマレスで柔軟なカラムストレージおよび計算として機能します。
- 分析シナリオ:JSONのマルチバリューインデックスが、多次元タグの柔軟な計算に適しています。
- AIシナリオ:モデルとアプリケーションをつなぐ架け橋としての役割を担うと同時に、AIエージェントやワークフローなどのデータ処理パイプラインにおいて、標準の入出力フォーマットとしても機能します。
多様なワークロード下でのJSONの能力を支えるため、OceanBaseのJSON機能は、豊富な計算式やJSONベースのマルチバリューインデックスなどを実装しています。基盤となるストレージフォーマットにおいては、JSON BinaryをサポートしてJSON内データのランダムアクセス(読み書き)を最適化しているだけでなく、JSONの構造化エンコーディングもサポートしています。これは、類似したJSONから構造化情報を抽出することで、ストレージ圧縮率およびJSON Pathに基づくクエリ性能を大幅に最適化するものです。JSONデータ型の詳細な紹介と使用ガイドについては、JSON データ型 を参照してください。
生成AIの時代において、マルチモーダルデータの処理はますます重要になっています。OceanBaseはベクトル処理能力および全文検索能力を強化し、ナレッジ検索シナリオにおけるハイブリッド検索のニーズをより強力にサポートします。「ベクトルアルゴリズム+データベース」の完全自社開発アプローチにより、OceanBaseのベクトル機能はオープンソースのベクトルデータベースと比較して明確な優位性を持ち、VectorDBbenchにおいて代表的なオープンソースの競合製品を上回る性能を記録しています。
カラムストアレプリカント
HTAPハイブリッドワークロードシナリオにおいて、 TPとAPのリソースを物理的に厳密に分離したいという要求に応えるため、OceanBaseデータベースはカラムストアレプリカント(Column Store Replica, Cレプリカ)のサポートを提供しています。カラムストアレプリカントは新しいレプリカタイプです。読み取り専用特性を持ち、レプリカ上のすべてのユーザーテーブルのベースラインデータはカラムストア形式のデータのみを格納します。カラムストアレプリカントは独立したZoneにデプロイされます。OLAP業務は、独立したODPエントリポイントを通じてカラムストアレプリカントにアクセスし、弱い整合性読み取り方式で実行されます。カラムストアのバッチ処理の優位性を活用してクエリを高速化でき、既存のOLTP業務に影響を与えません。2F1Aのデプロイモードでは、行ストアとカラムストアが混在する方式と比較して、2F1A1Cのデプロイにより、TP/APの物理レベルでの厳格な分離ニーズを実現できるだけでなく、ストレージのコストも節約できます。
カラムストアレプリカントは、レプリカの分散戦略と弱い整合性読み取りの解放メカニズムにおいて、通常の読み取り専用レプリカのルールに完全に準拠しています。両者の主な違いは、基礎データのストレージ構造にあります。通常の読み取り専用レプリカと同様に、カラムストアレプリカはプライマリノードの選出とログの同期投票プロセスに参加しませんが、静的データテーブル、コミットログ、メモリデータテーブルといったコアコンポーネントは同様にすべて含まれています。
カラムストアレプリカントの使用ガイドについては、カラムストアレプリカントを参照してください。
MySQLエコシステムの互換性
究極のパフォーマンスと拡張性を追求すると同時に、OceanBaseデータベースはMySQLエコシステムとの高い互換性の提供にも取り組んでいます。これにより、MySQLで稼働している業務をOceanBaseデータベースにシームレスに移行でき、既存のOLAPエコシステムツールと技術スタックを十分に活用して、データ分析とビジネスインサイトの迅速なイテレーションと革新を実現します。
構文の互換性:OceanBaseデータベースは、データ定義言語(DDL)、データ操作言語(DML)、データ制御言語(DCL)を含む(ただしこれらに限定されない)MySQLの標準SQL構文を全面的にサポートしています。これは、これまでMySQLを使用して記述されたデータクエリ、テーブル構造定義、インデックス作成、権限管理などのステートメントが、ほぼそのままOceanBaseデータベース上で実行可能であることを意味します。これにより、構文の大幅な調整が不要となり、移行コストと学習曲線が大幅に低減されます。
- シームレスな移行:既存のMySQLアプリケーションは、OceanBaseデータベースに迅速に移行して、移行プロセス中のコード修正作業量を削減できます。
- スキルの再利用:MySQL開発者やDBAは、新しくデータベース構文を学習する必要がなく、適応期間を短縮できます。
- エコシステムの融合:MySQLエコシステムと互換性のある構文基盤により、OceanBaseデータベースを既存のBI、ETL、データ可視化などのツールチェーンにより良く統合できます。
ビューの互換性:OceanBaseはMySQLのinformation_schemaビューと互換性があります。たとえば:
- テーブル情報クエリ:TABLESやCOLUMNSビューなどをサポートしており、ユーザーはデータベース内のすべてのテーブルの構造や列情報をクエリできます。これは、データ辞書の管理やサードパーティツールの統合にとって非常に重要です。
- 権限管理:SCHEMATAやSCHEMA_PRIVILEGESなどのビューをサポートしており、管理者がデータベースやテーブルの権限設定を手軽に確認・管理するのに役立ちます。
多くのデータベース管理、モニタリング、分析ツールは、 INFORMATION_SCHEMAに依存してデータベースのステータスやアーキテクチャ情報を取得します。OceanBaseデータベースのこの互換性機能により、これらのツールは特別なカスタマイズをすることなく、直接OceanBaseデータベース上で動作させることが可能です。OceanBaseデータベースは、各種のOLAPエコシステムツールをサポートしています。たとえば:
OceanBaseは、バッチ処理からストリーミング処理まで、フルスタックのデータ統合を実現しています。
- Flink、Kafka、OMS、OBLOADER、Dataworks、dbtなどの主要ツールのシームレスな接続をサポートし、企業の既存のETL、リアルタイム同期、データウェアハウス環境へ容易に統合できます。
- データベースカーネルは、ダイレクトロード、ファイル/ODPS/HDFS外部テーブル、External Catalogなどをサポートしており、マルチソースデータの統合やデータレイク連携における開発・運用のハードルを大幅に低減します。
- MySQL/Oracleの構文と高度な互換性を持ち、Tableau、PowerBI、Flink、Quick BIなどの主要なBI、分析、ストリーム計算ツールをゼロコードで移行・接続でき、真の「Out-of-the-Box」を実現します。
OceanBaseは、コアエンジンの革新だけでなく、数多くのエコシステム製品にも適応しています。
- 自動化オーケストレーションとスケジューリング:DolphinScheduler、n8n、Airflowなどのスケジューリングプラットフォームと深く統合し、多段階のデータ処理タスクの自動オーケストレーションと運用を実現します。これにより、大規模なデータガバナンスと複数システム間の連携効率が向上します。
- オブザーバビリティ:** Prometheus、Grafanaなどの監視ツールとシームレスに連携し、マルチテナント、ノード、クラスタのリアルタイム性能監視、アラート、インテリジェントな運用保守をサポートします。これにより、大規模クラスタや多角的な事業ラインの安定運用が容易になります。
- データ可視化によるエンパワーメント:Superset、Tableau、QuickBなどの主要BIプラットフォームと全面的に互換性があり、多種多様なロールによるセルフサービス分析、インタラクティブなダッシュボード、複雑な業務レポートをサポートし、ビジネスインサイトの獲得とデータ駆動型の意思決定を支援します。
現在のOceanBaseのOLAPエコシステムインテグレーション状況については、エコシステムインテグレーションを参照してください。